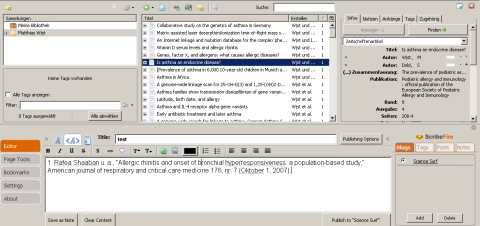
— an important question for a science blogger. The answer is yes, at least in principle, as you can see from my screenshot: I am able to drag and drop a reference from the Zotero list view into the Scribefire edit pane. As the reference appears there in full text only, I have already submitted a support request at the Scribefire site as. I think we need to implement DOI support and I will look into the possibility to write a Zotero plugin. A quick fix to reformat the dropped reference would probably be a simple bookmarklet.
BTW The Endnote import into Zotero works best with the “Refman” option on the UPPER RIGHT BAR in Endnote selected before starting the text export. The resulting text file then can be flawless imported in Zotero if it contains less than 100 or 200 references.