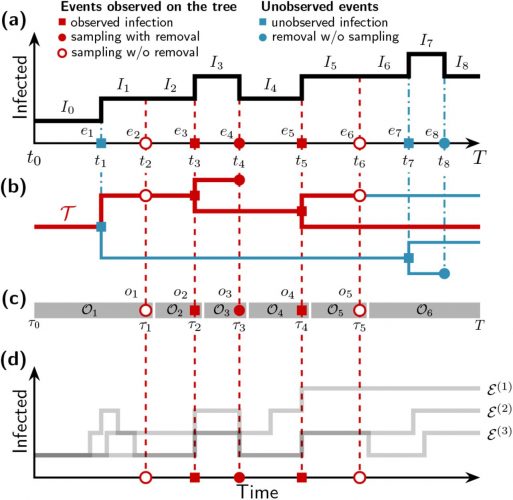
Die Charité distanziert sich von Matthes und Willich
Die Charité in Berlin hat sich von Aussagen eines ihrer Stiftungsprofessoren zu Nebenwirkungen nach einer Coronaimpfung distanziert. „Die Fakultät der Charité hat die Methodik der Onlineumfrage geprüft. Hierbei wurde festgestellt, dass diese Arbeit methodische Schwächen aufweist“, teilte ein Charité-Sprecher am Freitagabend mit.
Die Thesen von Harald Matthes, Stiftungsprofessor für Integrative und Anthroposophische Medizin an der Charité, hatten vor einigen Wochen viel Aufmerksamkeit bekommen. Er hatte nach Befragungen im Rahmen seiner sogenannten ImpfSurv-Studie behauptet, dass es eine Untererfassung an Nebenwirkungen beim zuständigen Paul-Ehrlich-Institut (PEI) gebe.
Warum bringt das die Universität Bonn bei Streeck nicht fertig? Auch da lief wissenschaftlich alles schief soweit überhaupt etwas wissenschaftliches kam. Wird Wissenschaft immer mehr von parteipolitischem Interesse vereinnahmt?
Bundesbildungsministerin Bettina Stark-Watzinger (FDP) hat eine repräsentative Studie zum Immunisierungsgrad gegen Sars-CoV-2 in der Bevölkerung angekündigt. Das Bundesbildungsministerium stellt dafür drei Millionen Euro zur Verfügung … Geleitet wird sie vom Bonner Virologen Hendrik Streeck … Die repräsentative Stichprobe der Bevölkerung wird vom Umfrageinstitut Infratest dimap unter Nutzern des Bonussystems „Payback“ genommen.
Haben wir eigentlich in Deutschland keine Epidemiologen, dass man nun einem unerfahrenen Virologen eine solche Studie überlässt? Und haben wir nicht Millionen bereits für die Nako Kohorte ausgegeben aber brauchen nun “Payback” Kunden?
Eine Antwort kommt von Stefan Huster, Vorsitzender des Sachverständigenrats zur Evaluation der Pandemiemaßnahmen
Die Evaluation der Corona-Maßnahmen dürfte allerdings das Thema sein, das die Öffentlichkeit am meisten interessiert. Im Ausschuss gibt es unter den verbliebenen 17 Mitgliedern aber sechs Juristen. Ist das nicht eine aberwitzige Besetzung?
Juristischer Sachverstand ist schon wichtig, auch wenn er vielleicht etwas überrepräsentiert ist. Wir sollen nach dem gesetzlichen Auftrag ja auch Vorschläge für eine Reform des Infektionsschutzgesetzes erarbeiten. Für die Evaluation der einzelnen Maßnahmen aber war die Kommission von Anfang an zu dünn aufgestellt.
Bis zu Drostens Austritt gab es im Ausschuss immerhin drei Virologinnen und Virologen. Aber aus der Epidemiologie, deren Kerngebiet die Ausbreitung von Krankheiten ist, gab und gibt es niemanden.
Die Kommission wurde 2021 je zur Hälfte vom damaligen Bundestag und der damaligen Bundesregierung besetzt, beim Bundestag zudem nach Parteienproporz. Niemand hat die Besetzung koordiniert, das merkt man leider. Wir bräuchten neben Epidemiologen unbedingt auch mehr Manpower, um die notwendige Literaturrecherche stemmen zu können. Auch der Zeitdruck ist enorm.
Aber wie die SZ kommentiert – genau die hätte man sich von der Kommission erwartet. Epidemiologie RIP.