It was a long wait – 10 years – for the Vitality vitamin D study in newborns to come to an end. It is super disappointing to see now their first study abstract at the 2026 AAAAI Annual Meeting with a null result. Besides the fact that they got it wrong – Vitamin D3 supplementation was never protective but allergy risk in newborn – the following three screenshots show something that should make any methodologist uncomfortable.
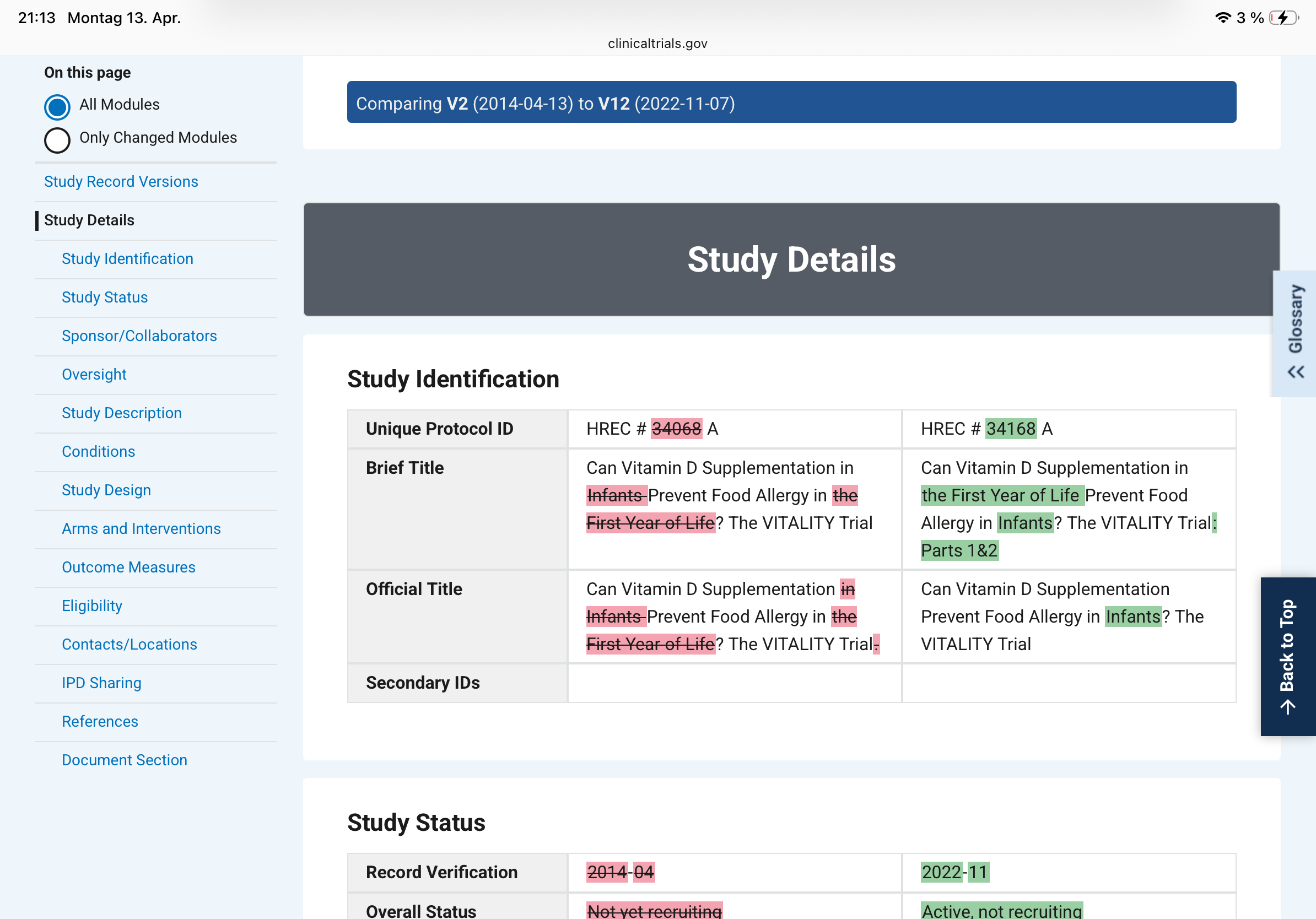
The VITALITY trial filed its first ClinicalTrials.gov record in April 2014. By November 2022 with the data at hand, version 12 shows sweeping rewrites to both the primary outcome and the inclusion criteria. Pink = deleted, green = added.
What changed, concretely:
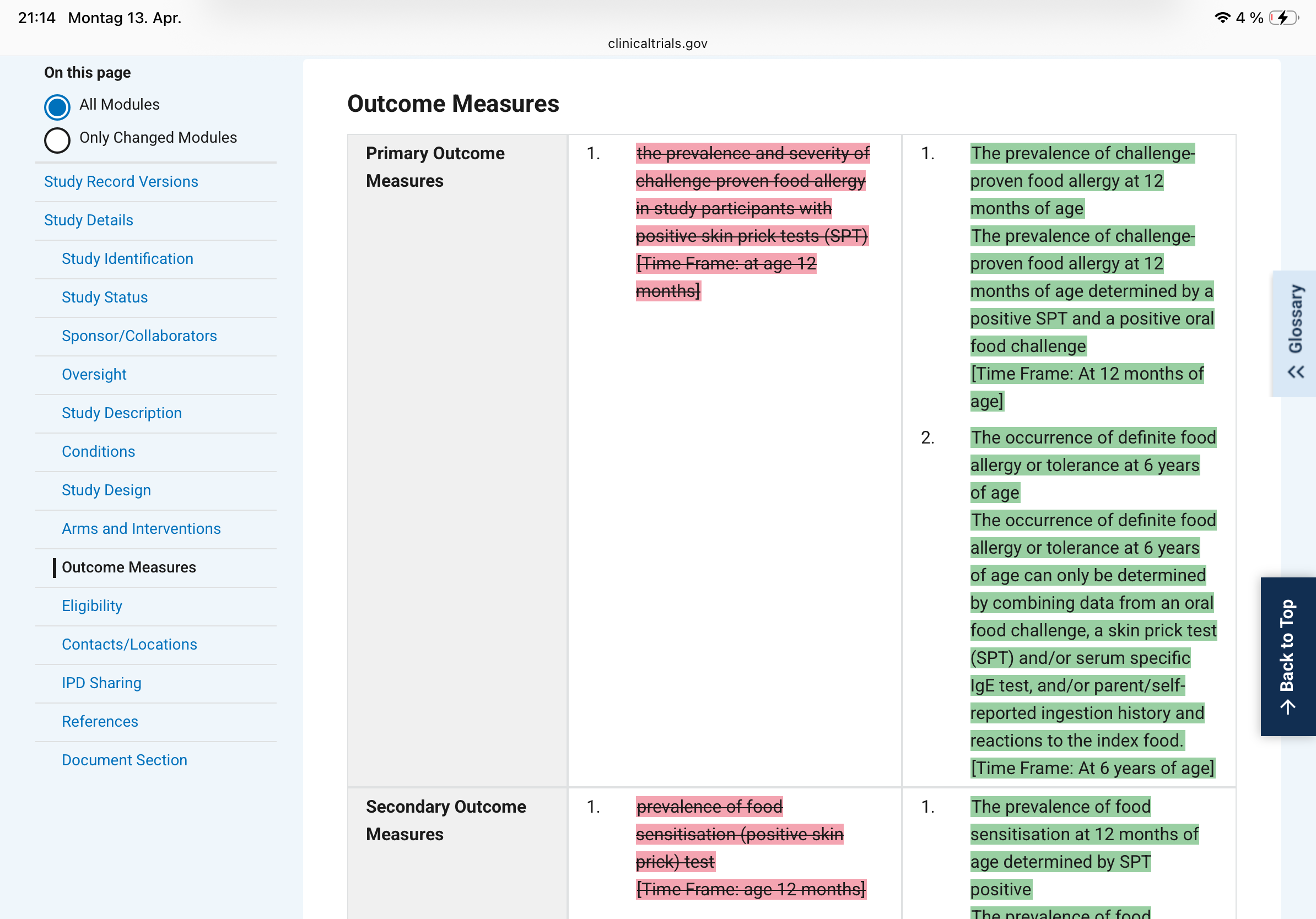
– The original primary outcome was "prevalence and severity of challenge-proven food allergy in participants with positive skin prick tests at age 12 months." Version 12 splits this into two primaries, adds a second time point (6 years of age), and quietly drops "severity" and the SPT-positive filter. That filter was doing real work: restricting the analysis to sensitised children would have given a much smaller, higher-risk denominator.
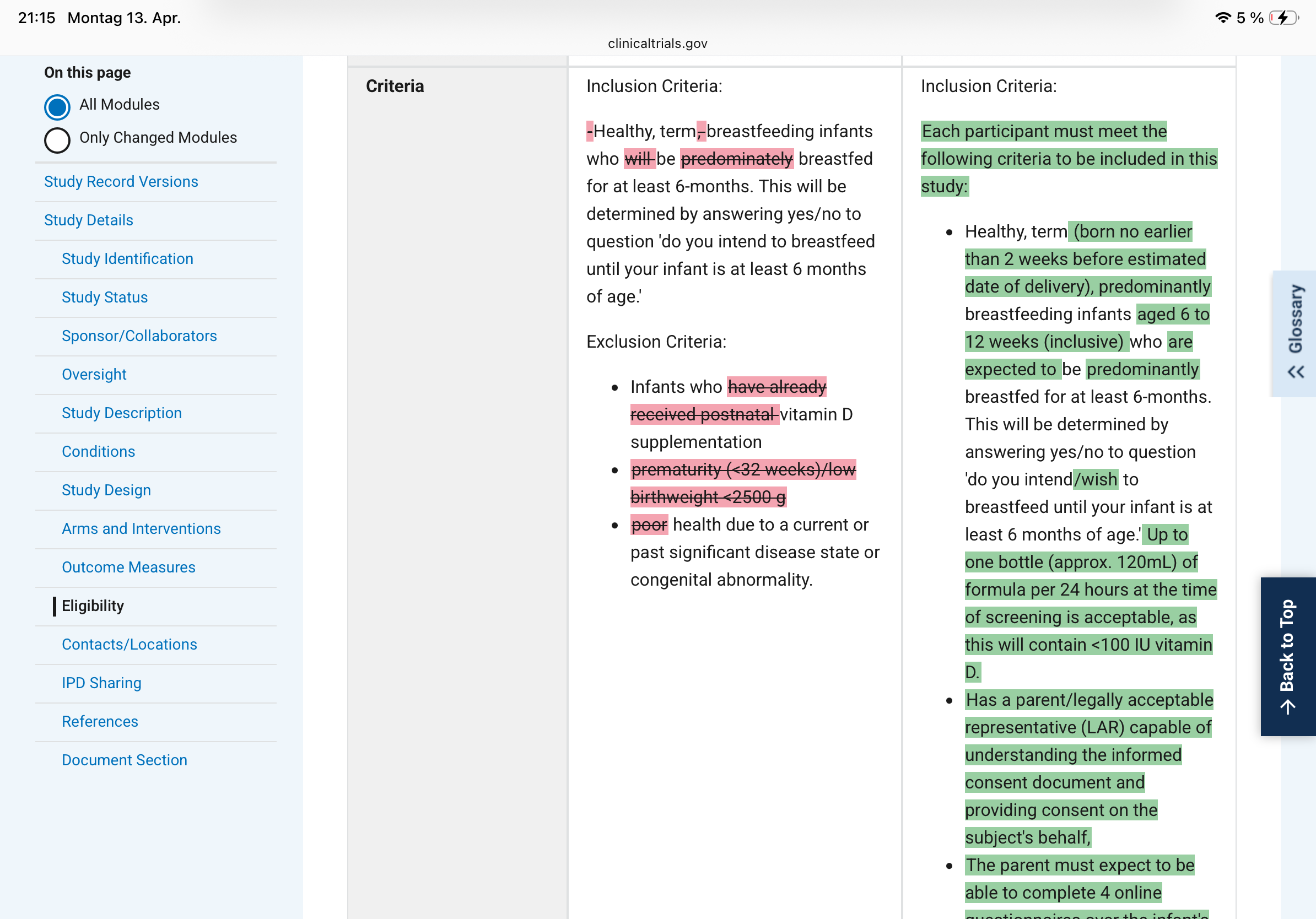
– The inclusion criteria went from "healthy, term, breastfeeding infants" to a detailed specification with an age window (6-12 weeks), formula tolerance up to 120 mL/day, and a new informed-consent bullet. Each addition narrows or shifts the enrolled population.

Why this is a fundamental problem?
Clinical trials are hypothesis tests, not explorations. The logic is identical to a one-sample t-test: you fix the null hypothesis, the test statistic, and the decision threshold before you look at the data, because the Type I error rate (your false-positive probability) is only valid under those pre-specified conditions. The moment you select or redefine your outcome after seeing interim results - even partially, even innocently - you are performing an implicit multiple comparison. You have, in effect, tested several hypotheses and reported only the one that worked.
Changing inclusion criteria mid-study is equally damaging. It redefines the population to which your result generalises. If the original enrolment targeted a broader group and the amended criteria select a more compliant or biologically distinct subgroup, the treatment effect you ultimately report belongs to a population that was never pre-specified. Reviewers and readers have no way to know whether the amendment was scientifically motivated or outcome-motivated.
The specific mischief of outcome switching
Dropping "severity" from the primary outcome is not cosmetic. A trial that fails on prevalence-plus-severity can be reframed as a success on prevalence alone. Dropping the SPT-positive filter expands the denominator, which typically dilutes an effect - unless the intervention actually works better in unselected infants, a hypothesis that was apparently not the original one. Adding a six-year follow-up endpoint transforms a 12-month study into something else entirely, with a different sample-size justification and a different regulatory profile.
What preregistration is supposed to prevent
The entire point of a trial registry is to create a timestamped public contract. Investigators declare in advance: this is our question, this is our population, this is how we will measure success. Journals and regulators can then verify that the published analysis matches the contract. When version 12 diverges this substantially from version 2, the contract has been renegotiated - and the renegotiation happened after years of data collection, when results were at least partially visible to the investigators.
This does not automatically mean misconduct. Trials genuinely need protocol amendments - safety signals emerge, recruitment proves impossible under original criteria, regulatory agencies request changes. But every such amendment requires a documented, dated rationale filed before the analysis is run, and the published paper must report both the original and amended specifications with transparent explanation. Silently absorbing eight versions of changes into a final paper, with no mention of what the original primary endpoint was, converts a confirmatory trial into a disguised exploratory one - while retaining the inferential authority of a pre-registered RCT.
The VITALITY screenshots are a clean teaching example of exactly this problem.