I found only one relevant blog post about PDFs produced by scientific publishers.
Although PDFs are the main formal output nowadays (no more “papers”) there is basically no standardization which meta data should be included in scientifc PDFs. It’s largely due to the software in the production office what’s in the PDF document — a largely underused resource.
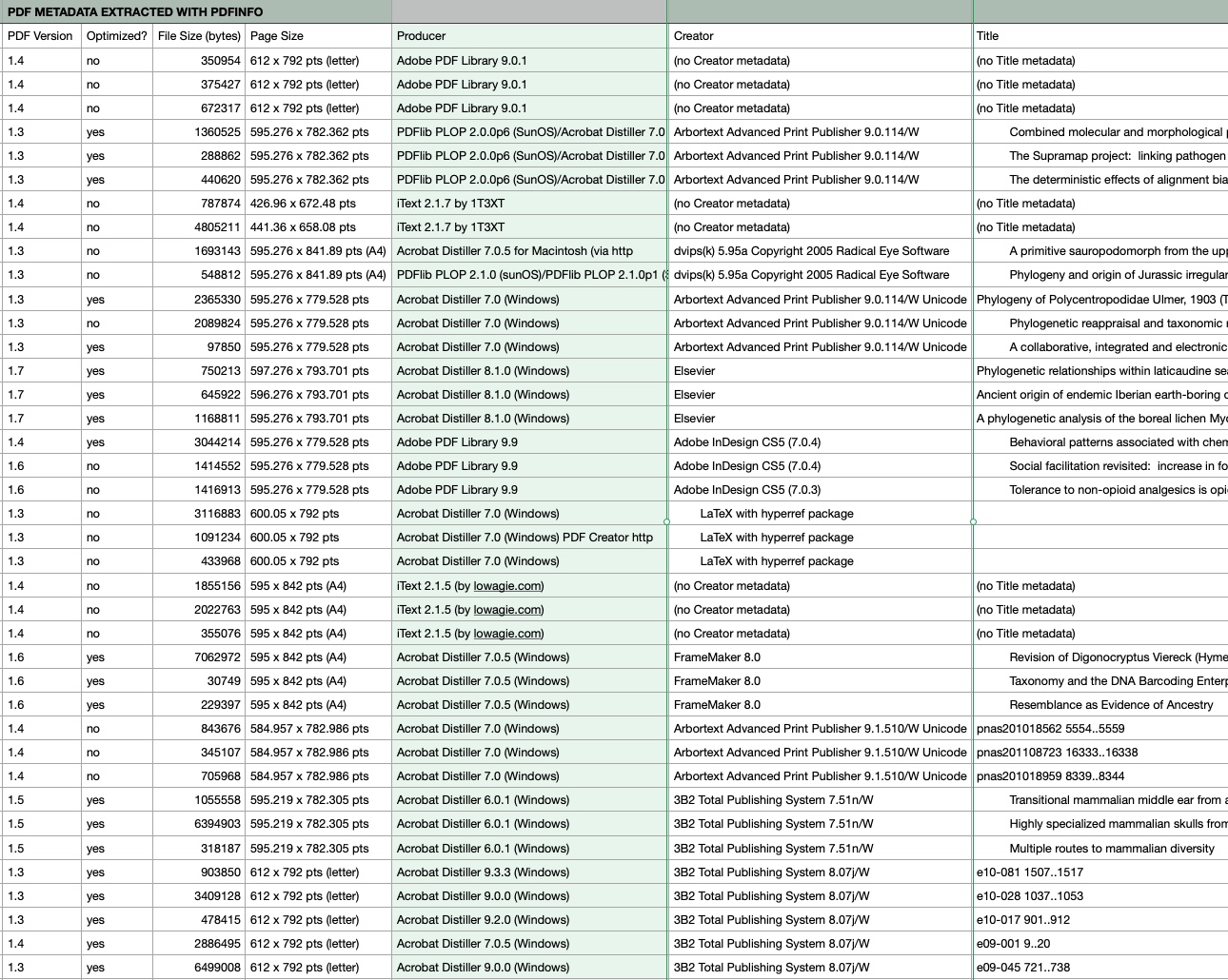
This is at least my experience when working on an image duplication pipeline in scientific papers. But test it yourself ….