You don´t believe that? It is possible as you can see here Continue reading Advertising on Pubmed
CC-BY-NC Science Surf , accessed 07.04.2026
You don´t believe that? It is possible as you can see here Continue reading Advertising on Pubmed
Süddeutsche Zeitung complains that data are permanently stored but never deleted. Even my irrelevant newsgroup comments have been stored (for 14 years) although they have never been intended to a larger audience. As humans we have no built-in timescale and are not particular good in judging the context of any data. This might be the reason according to SZ that Victor Mayer-Schönberger argues for meta-data when data should be deleted. I agree on this proposal and want this blog entry to be deleted until 16-May-2008 12:00:00 from any server in any world, yea, yea.
There is a nice online study by Trevor Cox on bad vibes which reminds me to a recent comment in Nature: Let the people sing … The most recent development is certainly the digitalorchestraleague postmodern conductors will have game consoles to arrange sound files.
Voice recognition has been on the forefront for many years; genetic fingerprinting is standard use while now nearly all surfaces of common products can be recognized by a phenomenon called laser speckle. Continue reading May I introduce to you
A Spiegel Science article reports
And how are unconscious (intuitive?) decisions made? Another mapping attempt at scienceblog:doi:10.1162/jocn.2006.18.12.2077
The last R newsletter (volume 7/1, April 2007) has a solution to a long standing problem. The new package mratios can deal now with ratios of means of normally distributed random variables and ratios of regression coefficients arise in a variety of ways. For two-sample problems, the package is capable of constructing confidence
intervals and performing the related tests when the group variances are assumed homogeneous or heterogeneous.
Science blogs usually refer to a scientific paper. To increase the visibility of science blogs, e.g. for a reverse lookup by search engines like “find all science blogs to a particular paper” it would be useful if science blogs would include a defined tag to which paper they relate. A http link will only partially work as single articles may be found at duplicate sites (journal or the publishers site or even through agencies like OVID and PUBMED CENTRAL). Using the DOI identifier is an alternative. To recognize any source document I therefore propose the following (unofficial) IANA scheme to be included somewhere in the body of your post
scienceblog:doi:10.1371/journal.pmed.0040072:
If there is no DOI available, I propose to use the link instead
scienceblog:http:www.thelancet.com/journals/lancet/article/PIIS014067360209654X: Please note that there should be an extra “:” at the end of the string; alternatively you may use a white space.
05.05.2007 Automatic DOI number extraction from blogs following this convention is now available at the Science Blog Finder page – just enter you rss feed address to get your blog indexed every 24 hours.
First monday has an interesting paper on the 100 most visited Wikipedia pages for the period of September 2006 to January 2007 (Wikipedia is the ninth most visited site in the U.S. with 43 million visitors). The crystal search link in the paper does not work but the table reports that science ranks at place 5 – not too bad.



A new major release of my favorite software is definitely worth another entry here. Besides many other features there is now a new function to add tags to emails – quite important if you need to assign emails to different projects. Furthermore (virtual) search folder are now cached for speed, many thanks, yea, yea.
Following the last Microsoft patch day, my laptop started with this quite unusual error message Continue reading A patch of the patch of the patch of the …
When getting important documents for review I usually check them for plagiarism. One of the best address seems docoloc – try it out, they have Continue reading More on plagiarism
I hope that will never happen to you but when reorganisating my email (from filtered subsets to virtual folder) a large inbox file with ~9000 emails and 1,2 Gb became corrupted.
Spending more than 3 hours on that file, I finally came across Emailchemy that could split the inbox file in chunks of 1000 emails that could re-imported. During this incident, I also found also eml2mbx that allowed to import my cms/vms elm (1991-1992) and windows vines (1993-1997) emails.
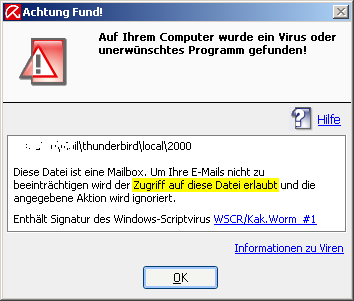
Another benefit: My anti virus program repeatedly complained about a virus sitting in an old email folder. Splitting up now this folder in a separate directory allowed to identify the email that had a script attached.
It seems that the online book giant as well as the internet search giant have disabled the print function from their preview pages – maybe somebody can explain to me what is the difference between free viewing and prohibited printing?
Looking at the page code, it seems that there is no encryption at all but some low grade user camouflage as shown in the Web Developer Extension. Is this “encryption” just an alibi function?
If you are interested in a more in depth analysis of the new library of Alexandria that Google is planning, German Tagesspiegel “Google hupf!” discusses three interesting points:
Finally, web 2.0 services are arriving at the desktop of the molecular biologists; nice to have also a SSL connection at Info-PubMed.
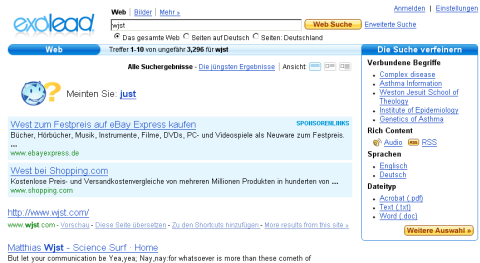
In my experience Google Scholar already shows more counts than ISI Web of Science. A new paper in first monday highlights another search engine that allows even truncation of search terms*: Exalead is a European (Paris) based search engine which does allow truncation and has a nice interface too.
A new series of papers in the BMJ discusses some alarming consequences of “impact” measurements
The impact factor now has a worrying influence not just on publication of papers but on the science behind them too … One consequence has been to make universities prioritise laboratory based life sciences that produce research published in the highest impact factor journals, causing substantial damage to the clinical research base.
that goes beyond the previous view of Seglen.