I hope that will never happen to you but when reorganisating my email (from filtered subsets to virtual folder) a large inbox file with ~9000 emails and 1,2 Gb became corrupted.
Spending more than 3 hours on that file, I finally came across Emailchemy that could split the inbox file in chunks of 1000 emails that could re-imported. During this incident, I also found also eml2mbx that allowed to import my cms/vms elm (1991-1992) and windows vines (1993-1997) emails.
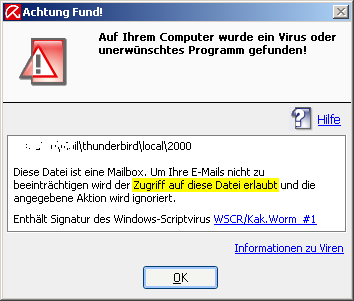
Another benefit: My anti virus program repeatedly complained about a virus sitting in an old email folder. Splitting up now this folder in a separate directory allowed to identify the email that had a script attached.
CC-BY-NC Science Surf , accessed 02.08.2026