Wir brauchen offensichtlich auch so ein “Kill Switch” Gesetz wie in Kalifornien das einen Notausschalter vorschreibt , wenn die Filter nicht mehr mitkommen undunethische Entscheidungen getroffen werden.
As we’ve previously explored in depth, SB-1047 asks AI model creators to implement a “kill switch” that can be activated if that model starts introducing “novel threats to public safety and security,” especially if it’s acting “with limited human oversight, intervention, or supervision.”
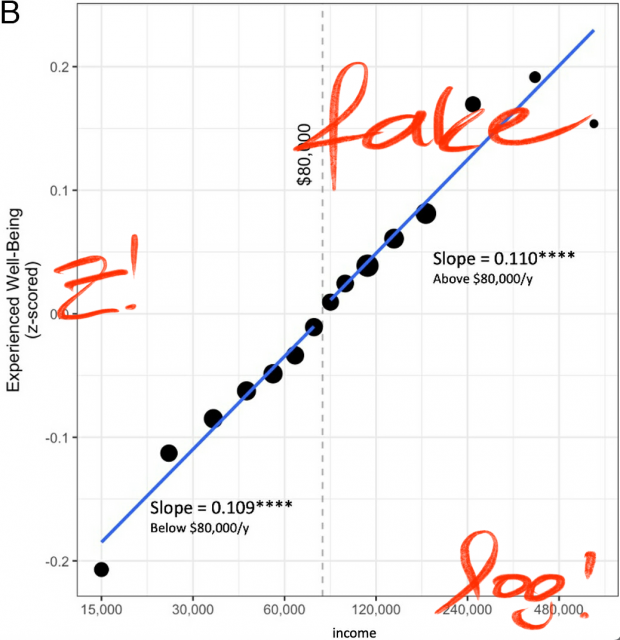
Nur – wann wird der Kill Switch aktiviert? Bilder wie die von Elon Musk’s X-Grok könnten wahlentscheidend sein.
Oh my god. Grok has absolutely no filters for its image generation. This is one of the most reckless and irresponsible AI implementations I’ve ever seen. pic.twitter.com/oiyRhW5jpF — Alejandra Caraballo (@Esqueer_) August 14, 2024
Charge it to 100%, and keep charging it for at least two more hours.
Unplug your laptop and use it normally to drain the battery.
Save your work when you see the low battery warning.
Keep your laptop on until it goes to sleep due to low battery.
Wait at least five hours, then charge your laptop uninterrupted to 100%.
this is how it looks afterwards
So the question was how to drain it most effectively? Maybe playing video would work but running this short line in the terminal as may times as there are CPUs was much more efficient
yes > /dev/null &
It seems that the initial high loading is most important
Researchers at SLAC-Stanford Battery Center report in a study published today in Joule that giving batteries their first charge “at unusually high currents increased their average lifespan by 50% while decreasing the initial charging time from 10 hours to just 20 minutes.”
Apple Mail can make its Core Spotlight index available to other apps which include an app specific Mail Plugin. This is controlled (from the Apple Mail perspective) in the general preferences under Manage Plug-ins.
Unfortunately however the Houdah plugin stopped now working. So the only working solution seems InfoClick that can build its own index but takes 17 hours for 340.00 emails…
while his explanation of the numerous duplications is clearly wrong
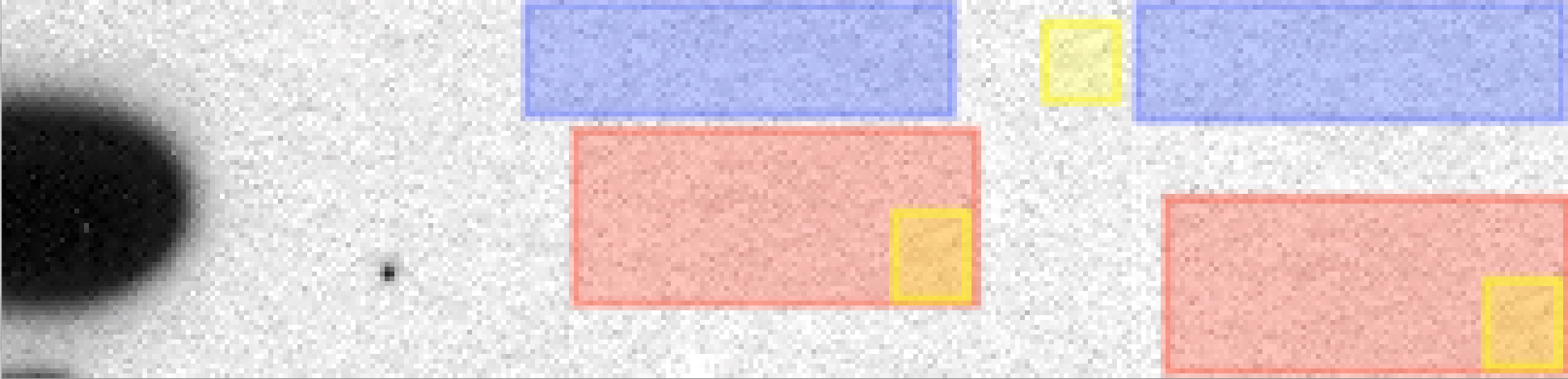
… the tiny allegedly cloned areas of similar background signals partly overlap and are randomly distributed in the image. Besides the fact that it would make no sense to duplicate such small areas of background – a fraudster could just run a gel with empty lanes – and that such duplications do not improve the data, overlapping duplications like this are nearly impossible to manufacture.
Of course also small areas can be copied with the clone tool. If the placement is random or intentional can only be judged from the original image while an educated guess is certainly allowed. Running Photoshop is at least far more time and cost effective than running a gel with an empty lane.
A general problem here is that digital reproductions of images – both of immunoblots and of tissue sections or cells – can create artifactual microduplications especially if the image resolution is changed during reproductions.
This is outright wrong. Artifacts by capturing or stitching software is possible in theory while in practice we have found it only a few times.
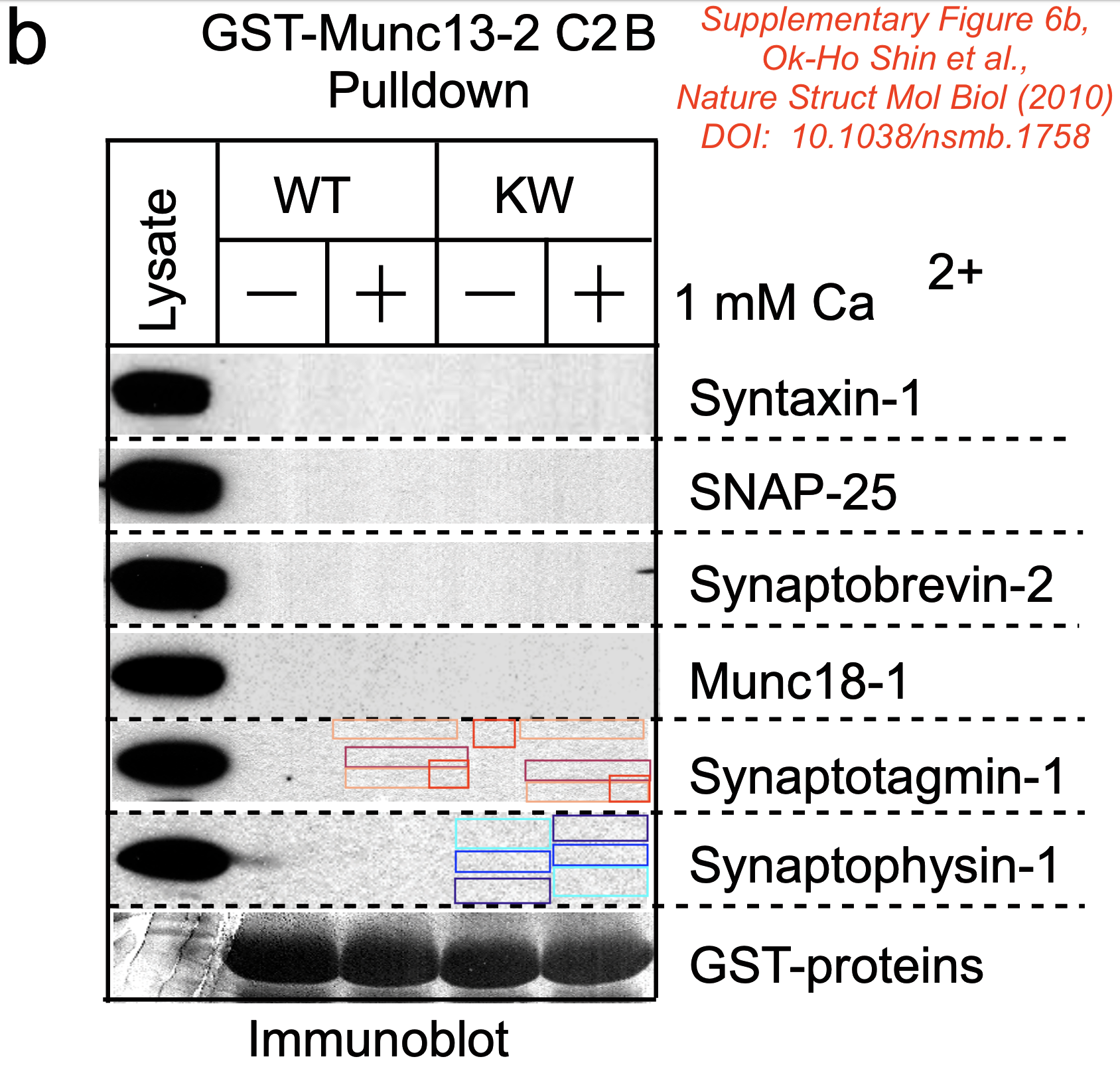
Also the manual annotation below shows 100% identical areas where the KW+ lane pixel has been copied to KW- (the other direction is less likely). Not sure what had been there, dust, dirt, text marker or another dot?
manual pixel-wise annotation, click for full view
Südhof comments on this image on his website
Mistake identified: Dr. E. Bik claims that the Suppl. Figure 6b immunoblot stripes (reproduced digitally at low resolution by the journal from a non-digital original blot) contains tiny areas of microduplications in the background pattern (not the actual signal). These areas are tiny, within a blot, randomly distributed, and only digitally identifiable. She implies that these blots are suspicious and could be manipulated.
Resolution: This is an unusually bizarre accusation since it refers to digital low resolution images in which tiny image areas would have been scrambled by a person if Dr. Bik’s accusation were correct. Even though she maintains publicly that she won’t speculate about motivations, her accusations imply a motivation that would be difficult to understand since any manipulation here would produce a partly altered background. The most likely explanation here is, like for many of the ‘mistakes’ identified by Dr. Bik’s A.I.-powered software, that these random microduplications are simply a reproduction artifact of a digitized image.
Classification: unfounded
Great story: The journal Nature Structural & Molecular Biology received the original blots and digitized them? So this is their fault? These are neither tiny spots, nor are they randomly distributed and of course, they can be seen by naked eye.
German newspapers covered the Südhof stor already (SPIEGEL, FAZ but also Science Magazine). Ulrich Dirnagel/Tagesspiegel believes that any intentional manipulation or deception cannot be recognized. I am not sure when looking at the images above.
The two reports note that Informa will explore how AI can make its internal operations more effective, specifically through Copilot, Microsoft’s AI assistant. “Like many, we are exploring new applications that will improve research and make it easier to analyze data, generate hypotheses, automate tasks, work across disciplines, and research ideas,” a Taylor & Francis spokesperson wrote in an email to The Chronicle.
Publishers neither analyze data, generate hypotheses and work on research ideas – it is just a money making scheme after the
Another publisher, Wiley, also recently agreed to sell academic content to a tech company for training AI models. The publisher completed a “GenAI content rights project” with an undisclosed “large tech company,” according to a quarterly earnings report released at the end of June.
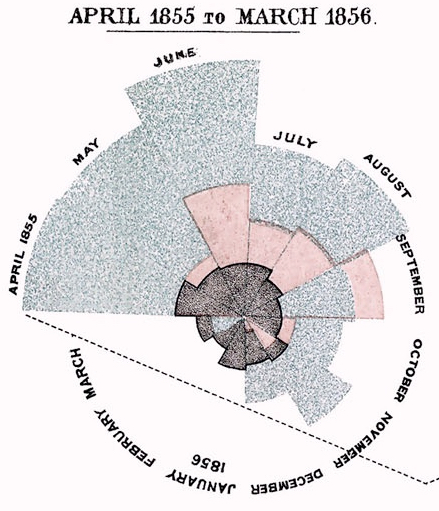
mit interessanten Details zu ihrem Rose Diagramm auf historyofinformation.com
In 1858 nurse, statistician, and reformer Florence Nightingale published “Notes on Matters Affecting the Health, Efficiency, and Hospital Administration of the British Army”. … This privately printed work contained a color statistical graphic entitled “Diagram of the Causes of Mortality in the Army of the EastOffsite Link” which showed that epidemic disease, which was responsible for more British deaths in the course of the Crimean War.
Google researchers have come out with a new paper that warns that generative AI is ruining vast swaths of the internet with fake content — which is painfully ironic because Google has been hard at work pushing the same technology to its enormous user base.
The study, a yet-to-be-peer-reviewed paper spotted by 404 Media, found that the great majority of generative AI users are harnessing the tech to “blur the lines between authenticity and deception” by posting fake or doctored AI content, such as images or videos, on the internet. The researchers also pored over previously published research on generative AI and around 200 news articles reporting on generative AI misuse.
The authors painfully collected 200 observed incidents of misuse reported between January 2023 and March 2024 and find
– Manipulation of human likeness and falsification of evidence underlie the most prevalent tactics in real-world cases of misuse…
– The majority of reported cases of misuse do not consist of technologically sophisticated uses … requiring minimal technical expertise.
– The increased sophistication, availability and accessibility of GenAI tools seemingly introduces new and lower-level forms of misuse that are neither overtly malicious nor explicitly violate these tools’ terms of services, but still have concerning ethical ramifications.
Utilizing publicly available user account data, we track the posting activity of academics on Mastodon over a one year period. Our analyses reveal significant challenges sustaining user engagement on Mastodon due to its decentralized structure as well as competition from other platforms such as Bluesky and Threads. The movement lost momentum after an initial surge of en- thusiasm as most users did not maintain their activity levels, and those who did faced lower levels of engagement compared to Twitter.
While the paper isn’t particular well designed – I would expect some Sankey plots showing the activity movement like those found after elections – the main message is clear. The paper summary also reflects my own experience as I am writing now only occasionally at my blog while my Twitter, Mastodon and Bluesky accounts are left in an orphan state.
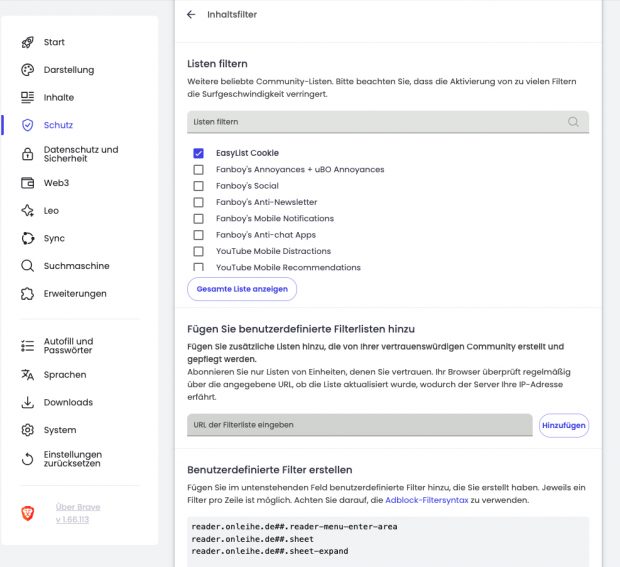
Leider funktionieren die Onleihe Screenshots über GoFullPage in Brave nicht so schön wie in Chrome da zusätzliche CSS Elemente von Onleihe stören . Mit drei Regeln im Inhaltsfilter
kann man sie aber ausblenden. Die Zoom Buttons sind zwar dann auch weg aber der Zoom funktioniert weiter mit CRTL+ bzw CTRL-.
In another website constructed more than a decade ago, I integrated WordPress pages just as iframe .This was quite common at that time but not very elegant as all the formatting had to be adjusted to the parent site for a coherent view. When revising the website last week I have chosen a radical different approach by completely silencing the WP output using a plugin
The title is clickbait as nobody really knows what is really relevant in science although some people still think that a few failed postdocs at NSC (Nature, Science, Cell) are the ultimate judges here.
Google also did not know in the 1990ies when they invented the pagerank with the now famous words “The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu”.
Everybody since then believed in the authoritative power of links but according to Roger Montti they are no more relevant as at a recent conference in Bulgaria Google’s Gary Illyes confirmed that links have lost their importance. And maybe even Google at all?
Create a PHP script that can read a CSV in the form start_date, end_date, event and output as ICS file
function convertDate($date)
{
$dateTime = DateTime::createFromFormat('m/d/Y', $date);
if ($dateTime === false) {
return false; // Return false if date parsing fails
}
return $dateTime->format('Ymd');
}
// Function to escape special characters in text
function escapeText($text)
{
return str_replace(["\n", "\r", ",", ";"], ['\n', '\r', '\,', '\;'], $text);
}
// Read CSV file
$csvFile = 'uci.csv'; // Replace with your CSV file name
$icsFile = 'uci.ics'; // Output ICS file name
$handle = fopen($csvFile, 'r');
if ($handle !== false) {
// Open ICS file for writing
$icsHandle = fopen($icsFile, 'w');
// Write ICS header
fwrite($icsHandle, "BEGIN:VCALENDAR\r\n");
fwrite($icsHandle, "VERSION:2.0\r\n");
fwrite($icsHandle, "PRODID:-//Your Company//NONSGML Event Calendar//EN\r\n");
// Read CSV line by line
while (($data = fgetcsv($handle, 1000, ',')) !== false) {
$startDate = convertDate($data[0]);
$endDate = convertDate($data[1]);
print_r($data) . PHP_EOL;
echo $startDate;
if ($startDate === false || $endDate === false) {
continue;
}
$event = escapeText($data[2]);
// Write event to ICS file
fwrite($icsHandle, "BEGIN:VEVENT\r\n");
fwrite($icsHandle, "UID:" . uniqid() . "\r\n"); // Unique identifier
fwrite($icsHandle, "DTSTART;VALUE=DATE:" . $startDate . "\r\n");
fwrite($icsHandle, "DTEND;VALUE=DATE:" . $endDate . "\r\n");
fwrite($icsHandle, "SUMMARY:" . $event . "\r\n");
fwrite($icsHandle, "DESCRIPTION:" . $event . "\r\n");
fwrite($icsHandle, "END:VEVENT\r\n");
}
// Write ICS footer
fwrite($icsHandle, "END:VCALENDAR\r\n");
// Close files
fclose($icsHandle);
fclose($handle);
echo "ICS file generated successfully.";
} else {
echo "Error: Unable to open CSV file.";
}
Source data are from UCI and output is here from where it can be added as a calendar. BTW created also my first “hello world” Swift/iPhone app using this source although this took a bit more time…
In LaTeX, you can use the biblatex package along with a bibliography management tool like BibTeX … to manage your references. To cite references generated by Bookends, you would typically export your references from Bookends to a BibTeX (.bib) file and then include that file in your LaTeX document.
Here’s a general outline of how you can cite Bookends references in LaTeX using BibTeX:
1. Export your references from Bookends to a BibTeX (.bib) file.
2. Include the BibTeX file in your LaTeX document using \bibliography{your_bibliography_file}.
3. Cite the references in your document using \cite{} or \autocite{} commands, passing the citation key corresponding to each reference in your BibTeX file.
\documentclass{article}
\usepackage[backend=biber]{biblatex}
% Include your bibliography file
\bibliography{your_bibliography_file}
\begin{document}
Some text \autocite{citation_key}.
% Your content here
\printbibliography
\end{document}
Replace your_bibliography_file with the name of your BibTeX file (without the .bib extension), and replace citation_key with the citation key of the reference you want to cite.
After compiling your LaTeX document with the appropriate compiler (usually something like pdflatex followed by biber and then pdflatex again), LaTeX will automatically format the citations and generate the bibliography according to the style specified in your document.
Make sure to choose a citation style compatible with your field or publication requirements. You can specify the citation style in the \usepackage[style=…]{biblatex} command. Popular styles include apa, ieee, chicago, etc.
Mayn journals requiring consecutive line numbering which is not a problem with MS Word, Open Office or LaTeX but with Pages.
Maybe it is possible to add a new background to PDF? Acrobat can do it (which I would not recommend), there is some crazy script out there (that did not work as well as ). My initial solution
did not work as pandoc cannot read the rather complex rtfd format produced by Pages. Also the next try with rtf2latex2e looked terrible, so I went back to RTF export in Libre Office where I corrected the few Math formulas that were not recognized correctly.
Another option would have been Google Docs – they introduced line numbering recently which is probably the fastest and easiest way to do that.
Whenver it comes to more than one formula, it would be even better to move from Pages to Overleaf (online) or Texifier (local).




 .
.