… or your gel scans with fingerprints seem to be the only secure way to prevent later photoshopping. Engadget has all the details of a new Canon patent, yea, yea.
CC-BY-NC Science Surf , accessed 13.06.2026
… or your gel scans with fingerprints seem to be the only secure way to prevent later photoshopping. Engadget has all the details of a new Canon patent, yea, yea.
Welcome Just Science Participant! Here is an extra primer how to store your references from the scientific papers that you are reading. In 1983 I was writing on cards, moved to a simple 4-column-database in 1989, used Endnote in 2005 and eventually moved to Zotero in 2007. Zotero is an open source database that sits as a plugin in your Firefox browser [download link]. The neat thing Continue reading More Zotero support
More recently I tested another emulator being useful for several genetics programs running under unix*: virtualbox by innotek. I am still struggling with the network adapter and mounting hda1 as writable but everything already works. Continue reading More virtual computer worlds
I started with the Khoury manuscript, replaced it with the Terwillinger book and are finally using this one.

It costs about 63$.
Sorry about the many abbreviations here – I promise to switch back to science with the next blog entry. When I had to install iTunes last year Continue reading iPOD goes TC
This is about Gaggle that I came across only very recently in a new Cell paper on predictive models of transcriptional control. It is not about Google; is it really true Continue reading Gaggle not Google
Over the last weekend I worked on redesigning my workflow of handling PDFs while taking into account the many new capabilities of the Zotero literature management. Continue reading A workflow for managing PDFs with Zotero
There are many ways how to accidentially duplicate files: storing multiple mail attachments, copying or restoring files to a wrong directory. Here is a simple way Continue reading A little gift from Science Surf
— an important question for a science blogger. The answer is yes, at least in principle, as you can see from my screenshot: I am able to drag and drop a reference from the Zotero list view into the Scribefire edit pane. As the reference appears there in full text only, I have already submitted a support request at the Scribefire site as. I think we need to implement DOI support and I will look into the possibility to write a Zotero plugin. A quick fix to reformat the dropped reference would probably be a simple bookmarklet.
BTW The Endnote import into Zotero works best with the “Refman” option on the UPPER RIGHT BAR in Endnote selected before starting the text export. The resulting text file then can be flawless imported in Zotero if it contains less than 100 or 200 references.
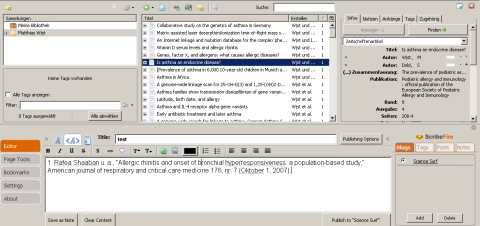
Zotero is a browser plugin that I am currently exploring as it can recognize PUBMED or PLoS entries and knows about Endnote/Refer/BibX export in UTF-8 format. The Open Office 2.1 insert reference macro produces a runtime error here and importing 100 references freezes my computer for about 5 minutes. Nevertheless Zotero follows a promising concept and holds much premises for the future; just discovered that data are stored in “…\zotero\zotero.sqlite”, great! one of the best available databases. This is the reason why I will

yea, yea.
As there is no central Zotero server, I wonder how I could access my local installation from different sites. The recommended portable Firefox is not really an universal solution. As with other open source databases, surrounding code of SQLITE is getting commercialized but there seems to be a free? sqlite server for download.
This is a more philosophical remark on science publication: With a technical sound solution for online referencing I expect that science blogs will get more influence while printed papers will loose their importance. Post publication peer review (attached comments) is certainly as good as pre publication peer review (that kills many new ideas, always delays publication and costs a lot of money better spent for research). You can cite me for that idea ;-)
Of a proven set of regulatory regions in zebrafish, computer programs find only between 29% and 61% of the true motifs. This does not come very much unexpected given the vast array of data shown by the Encode project. It even relates to the most basic question: What is a gene?
The more expert scientists become in molecular genetics, the less easy it is to be sure about what, if anything, a gene actually is.
iwith at least 5772 21U-RNAs? So – if I am sitting on the other side of the table when you are being examined don’t talk about junk DNA anymore, yea, yea.
I have currently a paper under submission at the EJHG that covers ethical issues of genetic testing. One of the key messages is that genetic data are not anonymous if having simply stripped of names.
A story in a completely different field confirms my fears. According to a NYT article
Last October, Netflix, the online movie rental service, announced that it would award $1 million to the first person or team who can devise a system that is 10 percent more accurate than the company’s current system for recommending movies that customers would like.
but things turned worse by an article of Narayanan und Shmatikov Continue reading Anonymizing genetic data
You may want to read the full story at Public Rambling (fiction), the NYT article of Amy Harmon (fact) or the “Peepshow” article of Marco Evers (fact) and come back here afterwards.
The recent advances in genome sequencing (and typing) has left us with an enormous amount of data. Although technology has been available for a couple of years knowledge exploded only recently, where people now may decide to participate in a genome study or even have their genes tested on their own costs at DeCodeMe, 23andme, Navigenics or other personal genome service provider.
The main question is, what do these data really mean for us? Should we start an Open Source Project Genome Explained to collect the necessary annotation rules and provide a platform to apply these rules to local data? The data mode may be quite simple: Continue reading Genome explained