There is a new paper of Rainer Rehak and Taylor Kate Woodcock. “Automating civilian harm: On Israel's use of the AI-enabled targeting system Lavender in Gaza and International Humanitarian Law. 2026 ACM Conference, 10.1145/3805689.3812357” that has some cruel details expanding on the current Wikipedia entry on AI-assisted targeting in the Gaza Strip.
The information depends on investigative journalism, built on anonymous IDF sources and leaked documents, but not independent forensic access. So there may be some limitations but this is all we know. The IDF’s response is consistently reported as a partial denial: the IDF stated some claims were baseless while others reflected a flawed understanding of IDF directives, describing a human-controlled process. There are three distinct systems.
Lavender is an “AI-powered database” which lists tens of thousands of Palestinian men linked by AI to Hamas or Palestinian Islamic Jihad, used for target recommendation
Gospel automatically reviews surveillance data looking for buildings and equipment thought to belong to the enemy and recommends bombing targets. One officer told the Guardian “I would invest 20 seconds for each target at this stage, and do dozens of them every day. I had zero added-value as a human, apart from being a stamp of approval.”
Where’s Daddy? is designed specifically to strike people at home with family present, because it was operationally easier than catching them during military activity.
Rehak and Woodcock now write
The digital infrastructure necessary for collecting, storing, and processing the data is provided by large US companies. The cloud storage of approximately 13.6 petabytes (13,600 terabytes) is provided by Google and Amazon under the name Project Nimbus. Cisco, Dell and Red Hat/IBM provide additional IT services. Palantir is responsible for integrating data from heterogeneous sources, and the AI applications are provided by Microsoft/OpenAI and Google; however not without internal resistance. To ensure optimal collaboration between the companies and the Israeli military, there are various personnel overlaps, e.g. Microsoft employees are also part of Unit 8200 of the IDF or regularly switch roles.
Their central finding is that the systems fail all three by design, not by accident. Reported configuration details they cite: thresholds for what counts as a “target” are adjusted up or down purely to hit a daily quota; pre-set tolerances allow roughly 15 civilian deaths per “junior” target and far more for “senior” targets; cheap, imprecise munitions are deliberately used on lower-value targets; and human review of each AI-generated target reportedly takes around 20 seconds, often just confirming the target’s sex. Internal IDF checks reportedly found about a 10% misidentification rate by the military’s own loose criteria.
The authors argue this combination amounts to a “reckless disregard” for distinction (people are targeted on statistical resemblance, not verified conduct), a failure of precautions (known error-prone, brittle systems are used uncritically at speed and scale), and very likely disproportionate harm given the resulting civilian death toll. They conclude that “targeted killing” is a misleading label for what they characterize as a more indiscriminate, quota-driven process, and that - given Israel’s technical sophistication - the high civilian toll is more plausibly a deliberate policy choice than an unintended side effect.
The cynical naming convention (Lavender, Gospel, Where’s Daddy?) sits awkwardly next to the lethality the AI systems used.
As if that weren’t enough, there seems to be another system not mentioned by Rehak and Woodcock called “Server in the Sky” (SITS) on drone fleets attributed to Haaretz reporting earlier this month. It deployed across Hermes 450 and 900 drones, designed to process intelligence and detect/classify targets in real time.
According to the documents, the algorithm independently analyzes the intelligence gathered by the drones’ sensors and cameras, automatically detecting targets, classifying them and deciding whether to track them or pass them on - to the command center, air force pilots or troops on the ground.
The server and the analytics it runs also allow the drone fleet to be managed autonomously, handing over tasks as the drones surveil a defined sector, shifting the burden among these unmanned aircraft to maintain continuous visibility.
So far neither ICJ (International Court of Justice) nor ICC (International Criminal Court) has so far issued a ruling that evaluates the Lavender/Gospel/Where’s-Daddy systems specifically as evidence – the charges so far center mainly on starvation as a weapon, destruction of infrastructure, and the overall casualty count.
Why does the reporting on the AI systems circulates only in NGO and academic analyses but has neither reached the public nor the ICJ? Germany accepts drone research projects and exports as this is prohibited only for systems that operate completely outside human control.
In Terror (2015) von Schirach has a pilot decide whether to shoot down a hijacked airliner heading for a packed stadium, killing 164 passengers to save tens of thousands. Germany’s Federal Constitutional Court had already ruled this unconstitutional: such a shoot-down violates the inviolable human dignity (Art. 1 GG) and right to life (Art. 2 GG) of the innocent passengers – a person may never be reduced to a mere calculation. It’s an absolute prohibition, not a proportionality balance; you simply don’t weigh lives against lives. That’s the sharp contrast with the IDF system that does the opposite. It pre-configures civilian deaths as tolerable collateral (15 for “junior,” hundreds for “senior” targets), not even as an emergency judgment under pressure like von Schirach’s pilot, but as a routine, repeatable daily setting.
Google und Ebay Bewertungen steuern Warenflüsse, mehr noch als jede Werbung.
Sie aggregieren verteiltes Wissen, komprimieren es zu Signalen und machen es für Dritte nutzbar – immer unter der Voraussetzung, dass die Eingabedaten die Realität hinreichend abbilden. Diese Voraussetzung ist keine technische Selbstverständlichkeit, sondern eine normative Anforderung, die im Alltag digitaler Plattformen aber immer mehr ignoriert wird.
Nehmen wir eBay. Seit November 2025 hinterlegt die Plattform automatisch eine positive Bewertung, wenn ein Käufer nach abgeschlossenem Kauf sich nicht meldet. Die Begründung ist nachvollziehbar: Schweigen ist häufig tatsächlich Zufriedenheit, und ein dichtes Bewertungsnetz stabilisiert das Vertrauen in den Marktplatz. Aber das System misst nicht mehr damit, was es zu messen vorgibt. Eine positive Bewertung, die nicht auf erlebter Zufriedenheit beruht, sondern auf dem Ausbleiben einer Handlung, ist wie ein Datum ohne Zeitangabe – formal vorhanden, semantisch leer. Wer einen defekten Artikel erhält und es versäumt, fristgerecht zu reagieren, erscheint im System als zufriedener Käufer. Das Protokoll stimmt. Aber mit der Realität hat das nichts mehr zu tun.
Google operiert nach derselben Logik, nur mit umgekehrtem Vorzeichen. Negative Bewertungen, die nachweislich auf realen Erfahrungen beruhen – und deren Authentizität Nutzer sogar per eidesstattlicher Erklärung belegt haben – werden auf Antrag des bewerteten Unternehmens routinemäßig gelöscht, wenn das Unternehmen "Unangemessenheit" oder "Diffamierung" geltend macht. Das Ergebnis ist dasselbe wie bei eBay, nur eine Eskalationsstufe darüber: Nicht Schweigen wird als Zustimmung kodiert, sondern das Missfallen wird zum Verschwinden gebracht. Was bleibt, ist kein Abbild der Realität mehr, sondern ein gefiltertes, plattformkonformes Surrogat, das dem widersprechenden Unternehmen höhere Einnahmen beschert.
Man könnte von struktureller Deception sprechen – einer Täuschung, die nicht aus Absicht, sondern aus Design entsteht1. Das Beunruhigende daran ist gerade die Absichtslosigkeit: Weil kein einzelner Akteur mehr verantwortlich zeichnet, fehlt auch die Motivation zur Korrektur. Bei einer klassischen Lüge gibt es einen Täuschenden, der zur Rechenschaft gezogen werden kann. Bei einem absichtlich auf Täuschung konstruierten Bewertungsalgorithmus gibt es nur ein Produktteam, das auf Conversion-Raten schaut. Ethik oder Moral? Brauchen wir nicht, unvergesslich das Video vom großen Tech-CEO-Vasallen-Dinner im September 2025 auf dem betonierten Rasen vor dem Weißen Haus.
Schlimmer noch: automatisierte Systeme skalieren diesen Effekt hoch. Was im Einzelfall als Ungenauigkeit wirkt, akkumuliert sich über alle AI's zu einem systematischen Vertrauensproblem. Vertrauenssysteme, die sich selbst korrumpieren, verlieren damit aber jeden Tag mehr an Nützlichkeit – sie kippen um. Die Sterne leuchten noch, aber bedeuten nichts mehr. Das betrifft auch jede positive Bewertung, die nun als Werbung degradiert wird, aber eigentlich auf einer Erfahrung beruhte, sofern sie nicht auch gekauft war.
Ist das organisierter Betrug?
Juristisch kaum. Bandenmäßiger Betrug setzt nach § 263 StGB Täuschungsabsicht, Irrtumserregung und Vermögensschaden voraus – und bei der Qualifikation "bandenförmig" eine organisierte Mehrtäterstruktur mit Tatplan. Beide Unternehmen handeln aber offen: Das Schweigen-gleich-Zustimmung-Prinzip und Jederzeit-Löschen-Prinzip steht mit Sicherheit irgendwo in den Nutzungsbedingungen. Juristisch greifbar wäre allenfalls irreführende Geschäftspraxis im Sinne des UWG oder der europäischen Omnibus-Richtlinie.
Epistemisch aber – im Kern ist es natürlich Betrug. Wenn man Betrug funktional versteht, als systematische Erzeugung falscher Überzeugungen zum eigenen Vorteil, dann trifft die Beschreibung erstaunlich gut: eBay profitiert von stabilen Verkäuferbewertungen, Google von einem bereinigten Reputationssystem, das Unternehmenskunden nicht vergraullt. Dass dies ohne strafrechtlich relevante Absicht geschieht, macht es gesellschaftlich nicht weniger problematisch – es macht es nur schwerer angreifbar.
Die Omnibus-Richtlinie – EU-Richtlinie 2019/2161, in Deutschland seit Mai 2022 in Kraft, hat das UWG geändert. Der für unseren Kontext entscheidende Punkt: Plattformen sind seither verpflichtet offenzulegen, ob und wie sie Bewertungen auf Echtheit prüfen. Wer suggeriert, Bewertungen seien authentisch, ohne ein Prüfverfahren zu betreiben, handelt nun unlauter. Außerdem sind gekaufte oder anderweitig gefälschte Bewertungen ausdrücklich als unlautere Geschäftspraxis eingestuft. Warum greift das bei eBay und Google trotzdem nicht? Weil beide Unternehmen formal prüfen – nur eben nicht auf Wahrheit, sondern auf Regelkonformität. eBay prüft, ob eine Transaktion stattgefunden hat. Google prüft, ob eine Beschwerde vorliegt. Das genügt juristisch als “Prüfverfahren”, auch wenn das Ergebnis völlig wertlos ist. Die Richtlinie hat eine Lücke dort, wo es darauf ankäme: Sie reguliert das Verfahren, nicht die Qualität des Ergebnisses.
Die folgenden drei Fallbeispiele im Anhang illustrieren, wie Konstruktionsbias und strukturelle Täuschung in unterschiedlichen Kontexten auftreten, wobei sich der Leser gerne selbst die Konsequenzen ableiten kann..
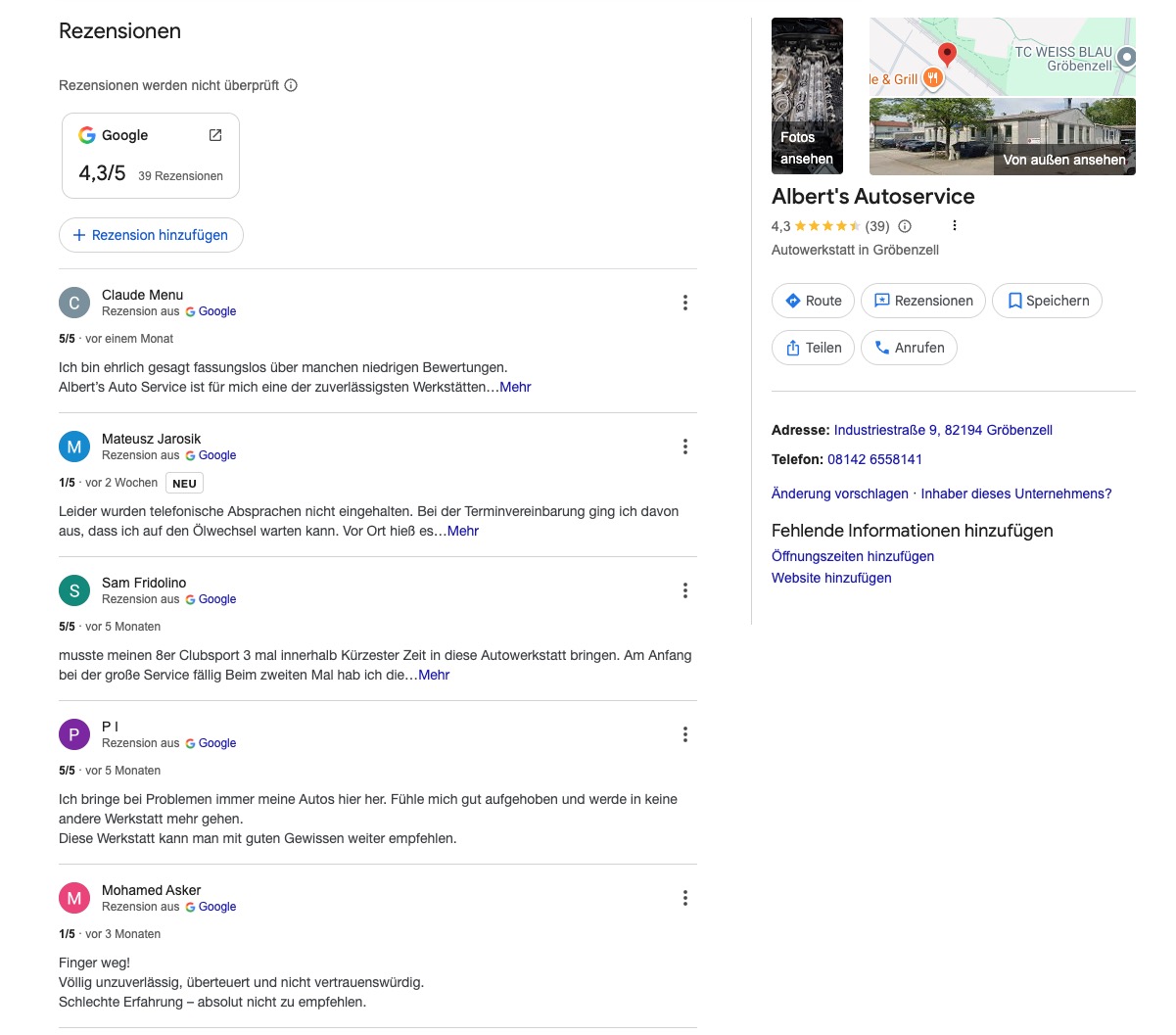
Im September 2024 beauftragte ein Kunde die Werkstatt von Burim Qeriqi in Gröbenzell mit der Reparatur eines Kurzschlusses. Die Rechnung belief sich auf 255,17 Euro. Die anschließend aufgesuchte Fachwerkstatt stellte schriftlich in ihrer Rechnung fest, dass die Lampen in beiden Fassungen fehlten oder falsch angeschlossen waren, die Verkabelung der dritten Bremslampe nicht funktionierte und korrodierte Kabelverbindungen am Unterboden unangetastet geblieben waren. Die Nachbesserung kostete 720,00 Euro. Qeriqi ist, wie sich später herausstellte, kein Mitglied der KFZ-Innung – ein Umstand, der auf seiner Google-Seite naturgemäß nicht vermerkt ist. Die sachliche und belegbare Rezension des Kunden auf Google verschwand jedenfalls bald darauf. Ein Tracing der Bewertungen über achtzehn Monate ergab: Die Werkstatt löscht negative Bewertungen systematisch und umgehend. Google stellt dafür das Werkzeug bereit – ohne Prüfung der inhaltlichen Berechtigung, ohne Berücksichtigung von Belegen. Eine einzelne negative Bewertung, die zum Zeitpunkt der Recherche noch sichtbar war, illustriert eher die Geschwindigkeit des Löschvorgangs als dessen Ausnahmen. Was auf der Profilseite verbleibt, ist kein Abbild der Kundenerfahrungen, sondern das Ergebnis aktiven Reputationsmanagements – ermöglicht und abgesichert durch die Plattform.
Screenshot 16.3.2026. Die negativen Bewertungen fehlen – ist die positive Bewertungen von Claude Menu aus Nizza echt?
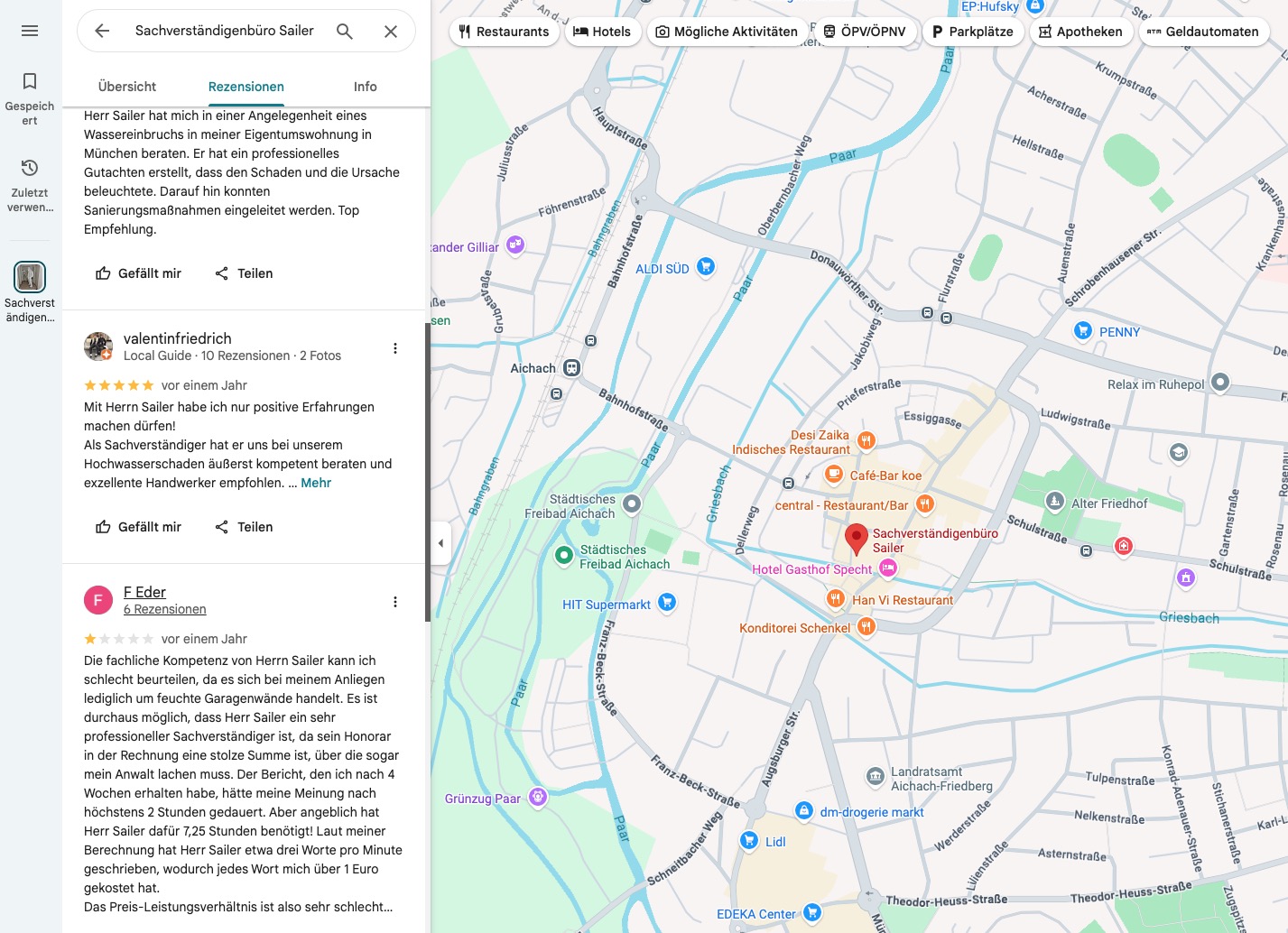
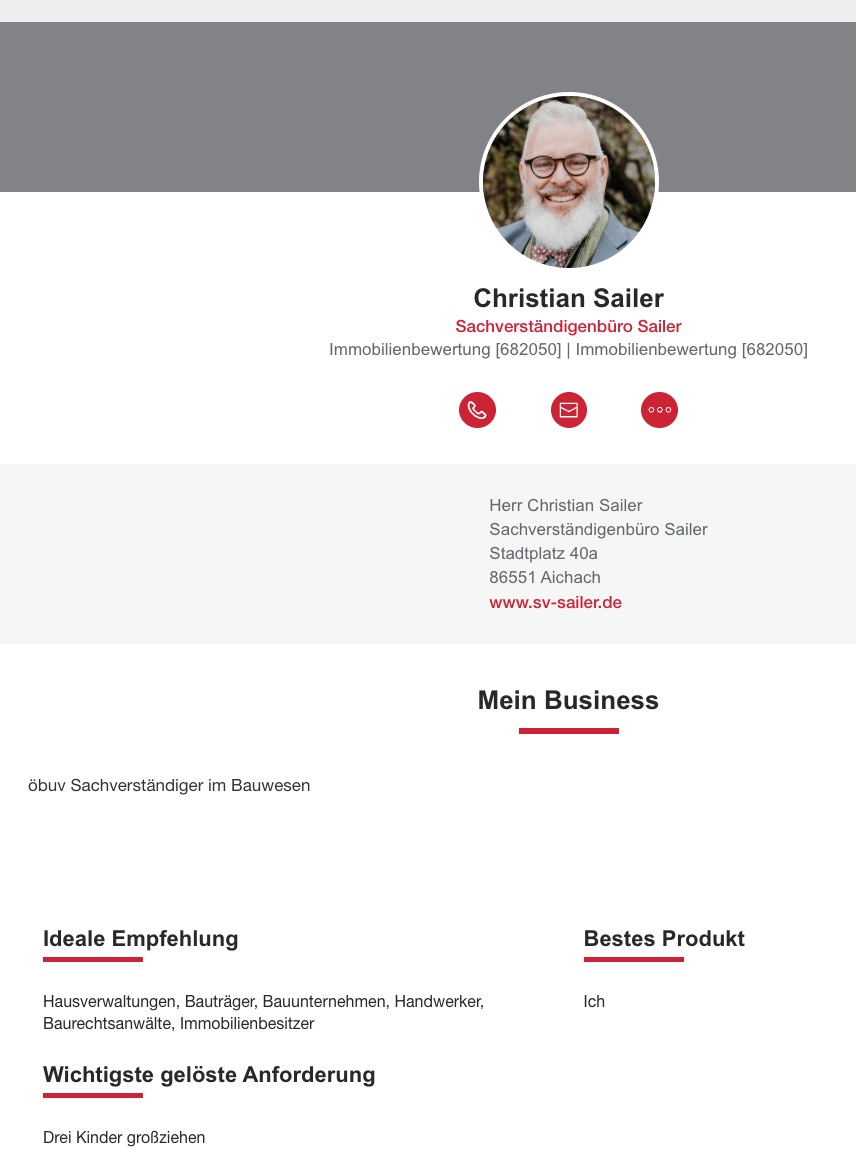
Der Gutachter wird wegen eines Wasserschadens von einem Kunden auf Rat seines Anwalts kontaktiert. Der Gutachter erscheint spät, unvorbereitet, liefert statt einer strukturierten Bestandsaufnahme einen langatmigen Vortrag. Der Kunde bricht das Gutachten ab. Die anschließende Honorarforderung landet vor Gericht und endet mit einem Vergleich – einem rechtsförmigen Abschluss, der den Sachverhalt aktenkundig macht. Der Kunde verfasst daraufhin eine präzise, tatsachenbasierte Rezension auf Google: keine Polemik, keine Vermutungen, nur der dokumentierte Hergang mit der Empfehlung keinen Blanko Werkauftrag zu unterschreiben. Das Ergebnis ist vorhersehbar. Google teilt mit, eine Beschwerde wegen Diffamierung erhalten zu haben, und löscht den Zugriff auf den Beitrag 2. Die Begründung lautet lapidar: der Inhalt “verstößt anscheinend gegen” die entsprechende Kategorie. Kein Nachweis, keine Abwägung, kein Einblick in die Prüfung, keine Reaktion auch auf die Reklamation, die Bewertung stehen zu lassen. Das Wort “anscheinend” ist dabei bezeichnend – es signalisiert, dass keine eigentliche Prüfung stattgefunden hat, sondern eine Kategorisierung. Was hier verschwindet, ist keine Meinung, sondern ein gerichtlich bestätigter Sachverhalt. Die Plattform fungiert als Zensurinstanz ohne Erkenntnisinteresse: Sie prüft nicht, ob eine Aussage wahr ist, sondern ob jemand Einspruch erhoben hat..
Screenshot 16.3.2026Screenshot 16.3.26 mit Selbstdarstellung der Qualifikationen
Fallbeispiel3
Strikeforge GbR Ebay Händler
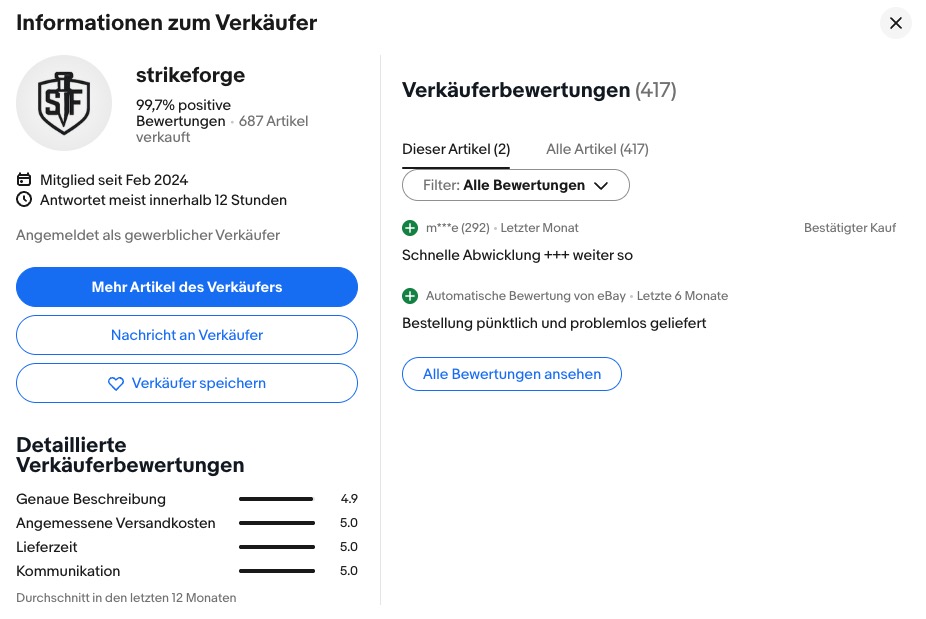
Ein Kunde kauft auf eBay einen AirTag-Halter aus dem 3D-Drucker – billiges Filament, zu geringe Wandstärke. Das Teil bricht kurz darauf unterwegs ab, der AirTag geht verloren – 5,99 € für den Halter, 32,99€ Verlust für den AirTag summieren sich zu 39€. Ohne Garantie, ohne Schadenersatz, dafür aber mit Belehrung durch den Verkäufer Philipp Huguenin, daß die Widerrufsfrist “bereits seit längerer Zeit abgelaufen ist. Schäden, die nach dieser Nutzungsdauer durch Belastung im Gebrauch entstehen, können wir leider nicht als Reklamation übernehmen. Vielen Dank für dein Verständnis.” Der Verkäufer dreht die Beweislast auch noch um – er definiert den Produktfehler (zu geringe Wandstärke) als Gebrauchsverschleiß und entzieht sich damit jeder Gewährleistungspflicht. Die gesetzliche Gewährleistungsfrist beträgt 2 Jahre ab Kauf – die Widerrufsfrist (14 Tage) ist etwas völlig anderes. Die Verwechslung von Widerrufsrecht und gesetzlicher Gewährleistung zeigt entweder Unkenntnis oder Kalkül. Der Kunde gab jedenfalls keine Bewertung ab. Nach dem Kauf erscheint auf eBay aber eine positive Bewertung für den Kauf – automatisch generiert, plattformkonform, sachlich falsch.
Screenshot 16.3.206
Das ist der Mechanismus in Reinform. Kein Verkäufer hat gelogen. Kein Algorithmus hat eine Entscheidung getroffen, die sich jemand bewusst überlegt hätte. Das System hat schlicht Schweigen als Zufriedenheit interpretiert und daraus eine Aussage gemacht. Der Verkäufer der mangelhaftenWare sammelt weiter positive Bewertungen. Der nächste Käufer verlässt sich darauf. Der AirTag des Übernächsten geht ebenfalls verloren – informiert durch ein Bewertungssystem, das funktioniert, solange man nicht fragt, was es eigentlich misst.
Literatur
1 Der Begriff schließt an Miranda Frickers Konzept der hermeneutical injustice an: Strukturelle Lücken im kollektiven Deutungsrepertoire führen dazu, dass bestimmte Erfahrungen nicht adäquat artikuliert – oder in diesem Fall: nicht dauerhaft dokumentiert – werden können. Fricker, M.: Epistemic Injustice. Power and the Ethics of Knowing. Oxford 2007
2 siehe auch SWR vom 7.7.2025 “Google-Bewertungen: Warum ehrliche Kritik oft gelöscht wird”
Googles Antwort: Allgemein und ausweichend
In einem offiziellen Erklärvideo beschreibt Google, wie Rezensionen geprüft werden: mithilfe von künstlicher Intelligenz und einem Moderationsteam. 2024 seien über 240 Millionen Beiträge entfernt worden.
"Unsere Richtlinien besagen eindeutig, dass Rezensionen auf echten Erfahrungen beruhen müssen - weshalb wir umgehend gegen böswillige Akteure vorgehen (...)", schreibt Google.Sackgasse für ehrliche Meinung
Kunden, deren ehrliche Meinung immer wieder gelöscht wird, sind frustriert. Was sie erleben, nimmt ihnen das Vertrauen in das Bewertungs-System.
Tatsächlich ist gerade in Deutschland eine wahre “Lösch-Industrie” entstanden. Scharen von Agenturen und Anwaltskanzleien haben sich auf das Entfernen von Beiträgen spezialisiert. Das Ergebnis: 99,97 Prozent aller Löschungen in der Europäischen Union wurden laut einer EU-Transparenzdatenbank im Jahr 2025 in Deutschland vorgenommen.
Neben dem Schutz des Rufs von Einzelpersonen schützt das deutsche Recht das geschäftliche Ansehen von Unternehmen. Es ermöglicht Unternehmen, die Entfernung unwahrer Tatsachenbehauptungen oder sachlich nicht gerechtfertigter Meinungsäußerungen zu verlangen, die dem geschäftlichen Ansehen schaden könnten ("Diffamierung"). Deutsche Gerichte haben die Hürden für Unternehmen, Bewertungen als diffamierend anzufechten, niedrig angesetzt. Neben dem Nachweis, dass eine Bewertung eine diffamierende Aussage enthält, können Unternehmen auch anführen, dass die Person, die eine Bewertung verfasst hat, kein Kunde war (z. B. weil sie keinen Beleg über einen Geschäftsvorgang haben).
Aber nun wird es tricky: Eine ungeprüfte, bloß behauptete Verleumdungsbehauptung, die von einer Plattform ohne eigene Prüfung weiterverbreitet wird, stellt selbst eine Diffamierung dar, nicht?
A study in Nature last month highlights a previously underappreciated aspect of this phenomenon: the existence of data voids, information spaces that lack evidence, into which people searching to check the accuracy of controversial topics can easily fall…
Clearly, copying terms from inaccurate news stories into a search engine reinforces misinformation, making it a poor method for verifying accuracy…
Google does not manually remove content, or de-rank a search result; nor does it moderate or edit content, in the way that social-media sites and publishers do.
So what could be done?
There's also a body of literature on improving media literacy - including suggestions on more, or better education on discriminating between different sources in search results.
Sure increasing media literacy at the consumer site would be helpful. But letting Google earn all that money without any further curation efforts? The original study found
Here, across five experiments, we present consistent evidence that online search to evaluate the truthfulness of false news articles actually increases the probability of believing them.
So why not putting out red flags? Or de-rank search results?
With the even increasing use of ChatGPT there is also a debate not only on responsibility but also crediting findings to individual authors.
The artificial-intelligence (AI) chatbot ChatGPT that has taken the world by storm has made its formal debut in the scientific literature - racking up at least four authorship credits on published papers and preprints. Journal editors, researchers and publishers are now debating the place of such AI tools in the published literature, and whether it's appropriate to cite the bot as an author.
Software recognition of AI generated text is not 100% accurate in particular if there are less than 1000 characters available. And of course, scientific texts will be always edited to evade the classifier.
Having discussed here this issue yesterday, we think that we need some kind of software regulation – sending the generated AI output not only to the individual user but keeping a full logfile of the output that can be accessed, indexed and searched by everybody.
'Good' and 'public benefit' are subjective concepts and will vary according to individual perceptions and context. Private and public interest are inevitably intertwined and pitting them against each other creates a false dichotomy. For example, if patients cease to trust their clinicians or more broadly the NHS, public good will suffer. Furthermore, extensive exploration of public attitudes towards sharing medical data has found that people approve in general for their data to be used for medical research and for 'good causes', whether environmental, social or medical, but they do not approve of their data to be used for commercial purposes or for powerful companies to profit at society's expense.
With the new European ruling of Safe Harbor, I anticipate that all major US companies will just give you an extra click to accept their updated licenses. And everything will remain the same…
But there is a true option: Set up your own cloud. “owncloud” (OC) is a mature product and is able to replace Dropbox with native OS X, Windows, iOS, Android and web clients.
Using just four plugins OC can WebDav sync also Files, Calendars, Todos, Contacts and RSS feeds – goodbye iCloud, goodbye Google, goodbye Dropbox, goodbye Feedly and goodbye Doodle. Continue reading Safe harbor for your private data→
Most people think that you can google for everything you want to know. What an overestimate!! There are so many relationships that will probably never turn out in any graph search ( at least I believe so ). And here is a nice example as I recently heard of a patient with an allergy AGAINST dimethindene maleate ( Fenistil (R), an antihistmaine used TO TREAT allergy. So whenever you enter “fenistil allergy” you get 119.000 hits. Although you get that result in 0,23s it will take you 23y to wade through the results. Hint: You could google for “leroy dimethindene” and you will find that there are only 2 patients so far in the literature plus the one that I know.
I have no idea how 23andme got its name but the business model of this company seems to rely on a rather haploid view of the world.
I had the pleasure this weekend to listen to a talk by Joanna Mountain(senior research director at 23andMe, the company that was founded by Googles Sergey Brin‘ s wife Anne Wojcicki). For whatever reasons Brin Continue reading 46andyou→
This is about Gaggle that I came across only very recently in a new Cell paper on predictive models of transcriptional control. It is not about Google; is it really true Continue reading Gaggle not Google→