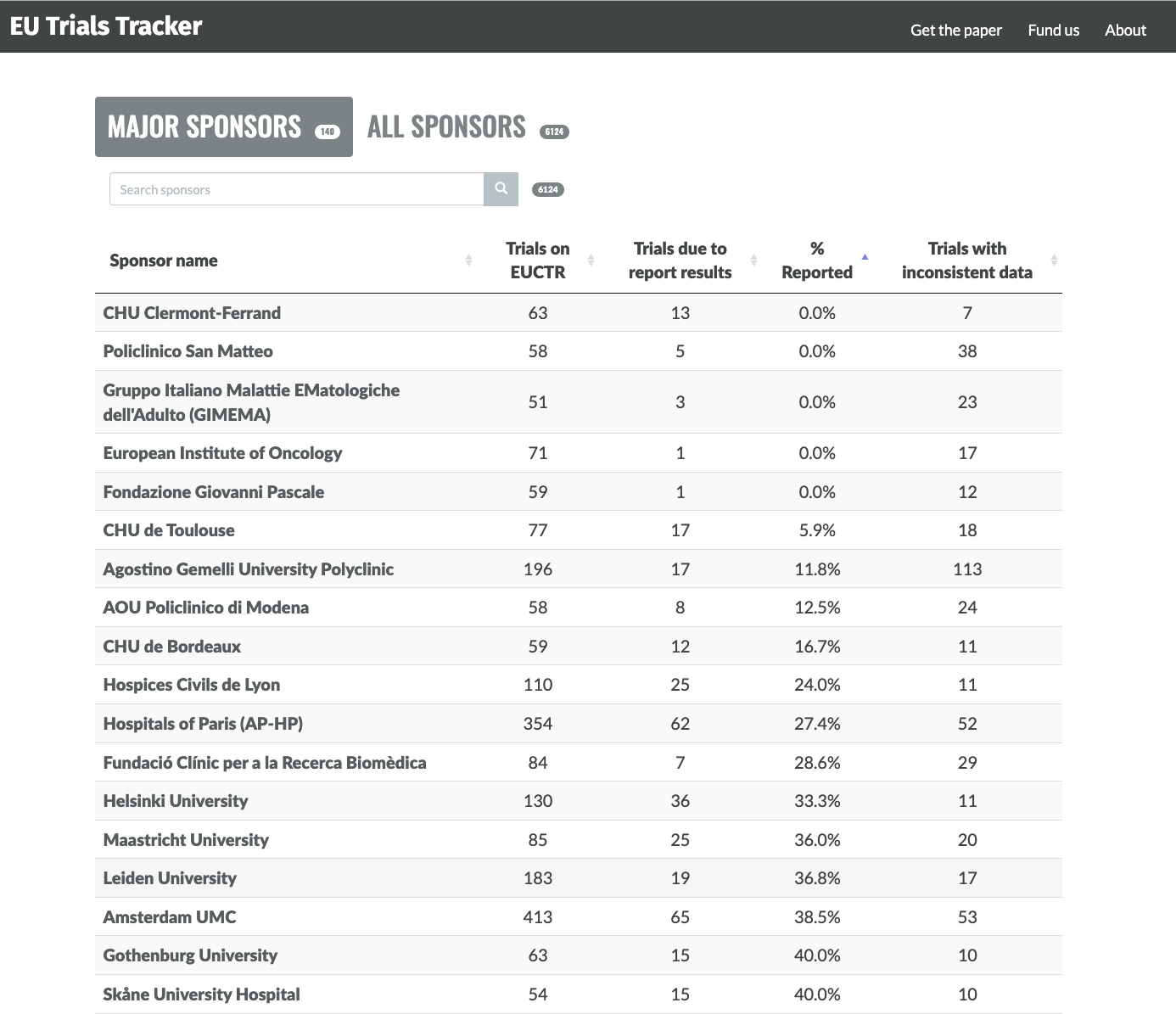
The British trials tracker, a never ending list of fame and shame
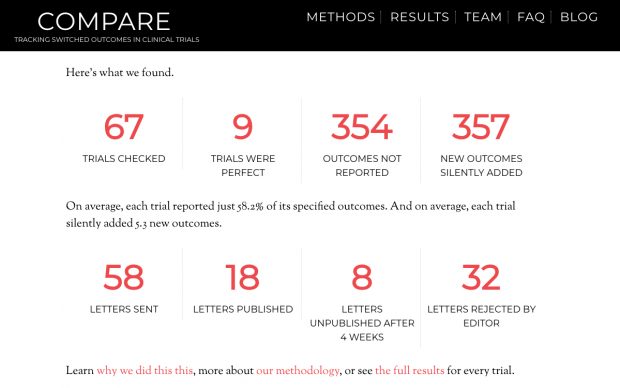
Although limited in scope, the COMPARE website of switched outcomes is also entertaining.
CC-BY-NC Science Surf
accessed 12.03.2026
The British trials tracker, a never ending list of fame and shame
Although limited in scope, the COMPARE website of switched outcomes is also entertaining.
Working on a meta-science paper on pitfalls of pre-registration I found it timely to attend a seminar of the Royal Society about the “The promises and pitfalls of pregistration“.
My personal highlights from today are the introduction 6:35 by Nicholas deVito, the end of the Fiona de Fidler talk 1:36.03 and the great Nick Brown at 4:27:57.
Here is day 2, Tue March 5 2024
404 errors reported by Nature
More than one-quarter of scholarly articles are not being properly archived and preserved, a study of more than seven million digital publications suggests.
The findings, published in the Journal of Librarianship and Scholarly Communication on 24 January indicate that systems to preserve papers online have failed to keep pace with the growth of research output.
“Our entire epistemology of science and research relies on the chain of footnotes,” explains author Martin Eve, a researcher in literature, technology and publishing at Birkbeck, University of London. “If you can’t verify what someone else has said at some other point, you’re just trusting to blind faith for artefacts that you can no longer read yourself.”
I save every PDF that I cite. But books are gone as soon as I give them back to the library.
But when I am gone?
Then it is gone.
404.
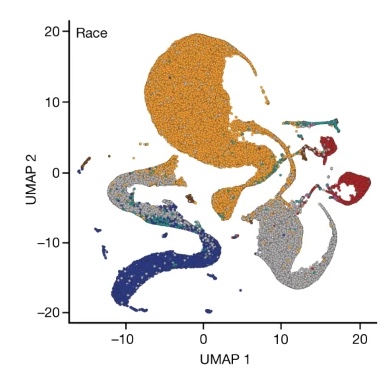 “Genetic drivers of heterogeneity” is the new description for the failed genetic concept of “reverse genetic engineering” – where we see now only sand running through the fingers.
“Genetic drivers of heterogeneity” is the new description for the failed genetic concept of “reverse genetic engineering” – where we see now only sand running through the fingers.
The genetic cause of type II diabetes explodes now into fragments. There are now 1,289 “association signals” in a new study while in another study published back to back in Nature 1 billion new genetic variants are being described that have not been included in the 1289 or 08-15 analysis.
What is the purpose of counting grains of sand?
And why introducing a new concept of race as noted also by others?
27 Feb 2024
Another reaction by Michael Eisen and Ewan Birney
The problem, critics said, is that UMAP creates blobs that look distinct while masking the inherent messiness in the data. “The fact that they are distinct is an artefact/feature of UMAP,” Ewan Birney, director of the European Bioinformatics Institute, wrote in a long thread
and by Lior Pachter who has an analysis way beyond the outrage
We begin with the figure legend, which lists Race, Ethnicity and Ancestry. Race and Ethnicity refer to the self identified race choices for participants (based on the OMB categories). Ancestry refers to the genetic ancestry groups discussed above. While these three concepts are distinct, the Ancestry colors are the same as some of the Race and Ethnicity colors: This is problematic because the coloring suggests a 1-1 identification between certain races and ethnicities, and genetic ancestry groups.
where we indeed arrive now at scientific racism.
part I
(sound is poor)
part II
part III
part IV
TBC
Nature News writes about a genetic study in Chinese families
The study also identified some new links. For example, mothers with higher levels of bile acid had shorter babies. Clifton says the analysis falls short of establishing causality but offers leads for further research.
I wonder about the title “The Born in Guangzhou Cohort Study enables generational genetic discoveries” which is more promotional than informational. I wonder also about the geopolitical statement as the map includes also Taiwan (with zero observations, as found also in a previous Cell paper).
And well this is certainly not the first family study in China (see the halted research of Scott Weiss just before he went into vitamin lobbying).
It is also not any new information that mothers with higher levels of bile acid have shorter babies. Did neither interviewer nor interview partner ever hear of intrahepatic cholestasis during pregnancy that is leading to multiple adverse perinatal outcomes?
Cholestasis is leading to preterm birth, which is leading to LBW (by an OR of 2) and also to shorter babies. Without any preregistration and any replication study included, it is difficult to make any conclusion of “leads for further research”. The bile acid result may be a regional artifact if it is only found in one region – basically like in the farming studies.
Neither are numbers in this study as large as the Nature News piece wants us to believe, I think that 332 trios is only an average study size.
I asked for that earlier [2019,2022] while only now this idea is being taken up, see https://error.reviews/

and well also nNature journalist is covering the story 6 months later.
With funding from the Humans in Digital Transformation programme, a fund to drive a digitalization strategy at the University of Bern, which has offered the project 4 years of support and 250,000 Swiss francs (US$289,000), reviewers are paid up to 1,000 francs for each paper they check. They get a bonus for any errors they find, with bigger bonuses for bigger errors — for example, those that result in a major correction notice or a retraction — up to a maximum of 2,500 francs.
The Bill Gates problem – billionaire philanthropists investing only in their own interests – is a real problem
Similarly restricted views exist in other areas, too. In the energy sector, for instance, Gates flouts comparative performance trends to back exorbitantly expensive nuclear power instead of much more affordable, reliable and rapidly improving renewable sources and energy storage. In agriculture, grants tend to support corporate-controlled gene-modification programs instead of promoting farmer-driven ecological farming, the use of open-source seeds or land reform. African expertise in many locally adapted staples is sidelined in favour of a few supposedly optimized transnational commodity crops.
On the hand, billionaires do not pay tax – which is adding even more weight to the Nature commentary. But what are the alternatives “tax the rich“? One remarkable woman is now showing how this could work – Marlene Engelhorn
Marlene Engelhorn, who is 31 and lives in Vienna, wants 50 Austrians to determine how €25m (£21.5m) of her inheritance should be redistributed. “I have inherited a fortune, and therefore power, without having done anything for it,” she said.
“And the state doesn’t even want taxes on it.”
Epidemiologie hat eher wenig mit Politik zu tun, obwohl politische Überzeugungen unstrittig mit den Lebensumständen zusammenhängen. Um so mehr war ich doch überrascht, wie sehr die individuelle politische Einstellung bei COVID-19 die Infektionsraten und damit auch die Mortalität beeinflusst hat – siehe unsere Studie in ZRex, die es vor 3 Tagen nun sogar in den Bundestag geschafft hat.
Überrascht bin ich nun auch von einer neuen Studie in Sci Rep die politisches bzw historisches Wissen mit politischer Ausrichtung in Zusammenhang bringt.
Contrary to the dominant perspective, we found no evidence that people at the political extremes are the most knowledgeable about politics. Rather, the most common pattern was a fourth- degree polynomial association in which those who are moderately left-wing and right-wing are more knowledgeable than people at the extremes and center of the political spectrum.
Je extremer die Überzeugung um so weniger Ahnung? Das stimmt nur begrenzt für Deutschland obwohl es ein neuer SZ Artikel so vermuten lässt
Am besten informiert waren jene, die moderat nach links oder rechts tendierten. Ganz in der Mitte des politischen Flusses beobachteten die Forscher eine kleine Untiefe, auch hier war das Wissen eher flach.
Damit ist die arme Grafik des Artikels überinterpretiert.
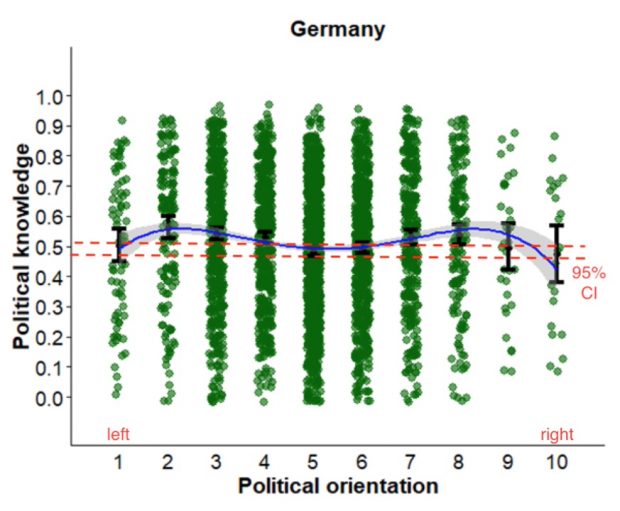
Die Unterschiede sind allenfalls grenzwertig auf 0.05 Niveau signifikant, wobei auch fraglich ist ob denn die 0.05 Punkte Wissenszuwachs überhaupt relevant sind.
In anderen Ländern sieht die Situation allerdings komplett anders aus…
A new paper in Nature Methods has some interesting and world-first comparison of
97 metrics reported in the field of biomedicine alone, each with its own individual strengths, weaknesses and limitations and hence varying degrees of suitability for meaningfully measuring algorithm performance on a given research problem
By forming an international multidisciplinary consortium of 62 experts they performed a multistage Delphi process identifying pitfalls related to the inadequate choice of the problem category (P1), to poor metric selection (P2) and poor metric application (P3. Here is one P1 example of this highly recommended paper.
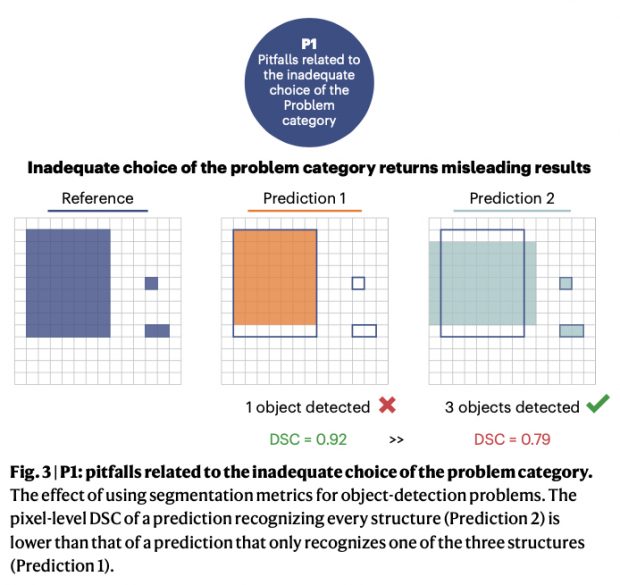
The pixel metrics are github while the code from the paper is also online. And do not miss the sister publication by Maier-Hein L. et al. “Metrics reloaded: recommendations for image analysis validation” also in Nat. Methods 2014.
