9 years later – Avery Amereau is singing here in Munich
CC-BY-NC Science Surf , accessed 25.03.2026
This is really cool – I had a long lasting error in my GPX cycle planner where I could never find the culprit.
Basically, the system was freezing after doing a POI search. With the most recent Safari and Chrome updates everything is working now. Just needed a new API key from Google …
http://geschichtedergegenwart.ch/open_access-wie-der-akademische-kapitalismus-die-wissenschaften-veraendert/
Hagner zeigt einige Aspekte auf, wie Open Access unsere Wissenschaftslandschaft verändert. Es ist ein interessanter Essay, leider redet der Autor viel über die MINT-Fächer (Medizin, Informationswissenschaften, Naturwissenschaften, Technik) ohne davon allzu viel zu verstehen. Die Grundaussage stimmt natürlich, dass es eine heterogene Spielwiese ist
Die Praxis von Open Access ist dominiert von einer Vielzahl unterschiedlicher Akteure mit zum Teil gegenläufigen Interessen. Dazu gehören Politiker, globale Verlagskonsortien, Förderorganisationen, Wissenschaftsmanager, Bibliothekare, digitale Aktivisten, die Computerindustrie und schließlich auch diejenigen, um die es eigentlich geht: Wissenschaftler – aber auch hier handelt es sich keineswegs um eine homogene Gruppe.
Dabei ist völlig unklar, wohin die Entwicklung geht. Ob die EU-Rahmenprogramme im Wesentlichen “über Bande gespielte Wirtschaftsförderung” sind, ist relativ egal unwichtig in dem Zusammenhang. Es stimmt auch nur sehr begrenzt, dass man in digitaler Zeitschriften Artikel publizieren kann, die man in “seriösen” Journalen nicht unterbringen kann.
Dafür fehlt der wichtigste Punkt, dass Open Access lediglich die Kosten vom Leser auf die Autoren abwälzt. Die Verlag verdienen ungehindert weiter, statt an Elsevier gehen Steuergelder nun an PLoS, 36 Millionen in 2014. Und wenn Elsevier seine Strategie nur etwas modifiziert im Sinn von „we continued to make good progress on our strategy to systematically transform our business into a professional information solutions“ dann haben wir ziemlich bald das Facebook Phänomen auch in der Forschung: Keiner ist wirklich überzeugt, aber de facto frisst es unsere Zeit.
Der Titel des Essays ist jedenfalls gut. Da könnte man viel interessantes herausholen, zum Beispiel, dass Zeitschriften keine “periodicals” mehr sind und Wissenschaft zur Dauerberieselung wird. Wenn der Zeitschriftenname nun keine Werbung für meinen Artikel mehr ist, muss ich nun selbst für jedes Paper eine Kampagne starten?
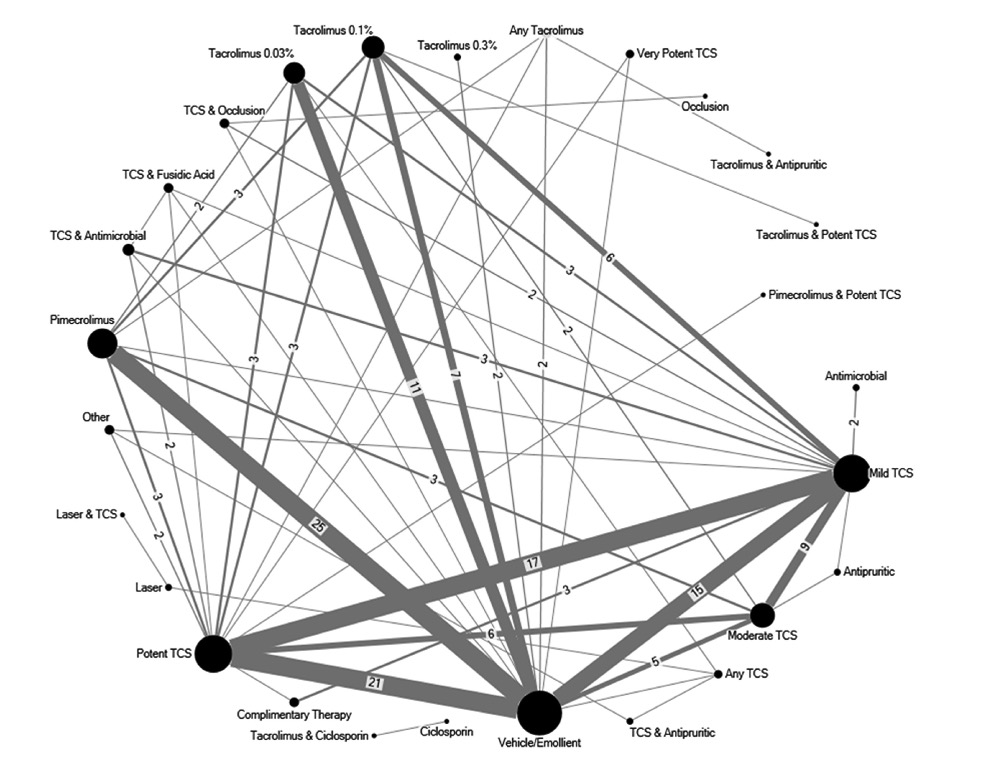
Although I didn’t expect that ever in allergy research there is an editorial with the title “Research Waste in Atopic Eczema Trials – Just the Tip of the Iceberg” refering to a meta-analysis by Wilkes et al.
Clinical trials often continue to be undertaken even though the effectiveness of the intervention under consideration has already been demonstrated. In addition, vehicle- or placebo-controlled studies predominate over head-to-head comparisons, although the latter would be more informative for clinicians in guiding patient management. This creates research waste, and both investigators and funders are to blame.
A new paper in PLoS Negl Trop Dis this week reports
The hygiene hypothesis is accepted by many in the global scientific community […] However, aspects of this hypothesis are based on assumptions that may not fully account for realities about human helminth infections. Such realities include evidence of causal associations between helminth infections and asthma or inflammatory bowel disease
Talking about realities may help proponents of the hygiene hypothesis who are stuck in a never ending loop publishing observational studies.
Even the NEJM contributes to the hygiene hysteria hype this week. Although the allergic rhinitis prevalence isn’t so much lower in old order Amish (who are even a heterogenous group), the difference to Hutterite is being highlighted. I do not even understand the study design here as it is neither cross-sectional, nor case-control nor cohort study. Is it just an exposure description in two different groups? Conclusions like
sustained microbial exposure was also reflected in the phenotypes of peripheral innate immune cells in the Amish.
are strange if we believe that we humans carry more bacterial than human cells. And every smoker encounters a 120fold endotoxin concentration compared to ambient air – without getting rid of asthma or allergy.
The results of our studies in humans and mice indicate that the Amish environment provides protection against asthma
is certainly wrong – nobody knows if this is an environmental or genetic or iatrogenic factor. The key finding is IRF7 expression but unfortunately IRF7 plays a critical role in the innate immune response against viruses – and not bacteria/endotoxin…
I need to downscale images on mobile phones to save bandwidth. Here is my code based on http://www.codeforest.net/html5-image-upload-resize-and-crop. No need for any complicated plugins. Take care of some security holes…
<html>
<head>
<script src="jquery-1.11.1.min.js"></script>
<?php if ($_POST) {
$img = $_POST['image'];
$img = str_replace('data:image/jpeg;base64,', '', $img);
$img = str_replace(' ', '+', $img);
$data = base64_decode($img);
$file = 'cache/' . uniqid() . '.jpg';
file_put_contents($file, $data);
}
?>
</head>
<body>
<form>
<input type="text" value="" name="text" id="text"/>
<input type="file" name="filesToUpload[]" id="filesToUpload" multiple="multiple" />
<input type="button" id="button" value="submit">
</form>
<script>
$('#button').click(function(){
if (window.File && window.FileReader && window.FileList && window.Blob) {
var files = document.getElementById('filesToUpload').files;
for(var i = 0; i < files.length; i++) {
resizeAndUpload(files[i]);
}
}
else {
alert('not supported');
}
});
function resizeAndUpload(file) {
var reader = new FileReader();
reader.onloadend = function() {
var tempImg = new Image();
tempImg.src = reader.result;
tempImg.onload = function() {
var max_width = 500;
var max_height = 500;
var tempW = tempImg.width;
var tempH = tempImg.height;
if (tempW > tempH) {
if (tempW > max_width) {
tempH *= max_width / tempW;
tempW = max_width;
}
}
else {
if (tempH > max_height) {
tempW *= max_height / tempH;
tempH = max_height;
}
}
var canvas = document.createElement('canvas');
canvas.width = tempW;
canvas.height = tempH;
var ctx = canvas.getContext("2d");
ctx.drawImage(this, 0, 0, tempW, tempH);
var dataURL = canvas.toDataURL("image/jpeg");
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
location.reload();
}
};
xhr.open('POST', 'index.php', true);
xhr.setRequestHeader("Content-type","application/x-www-form-urlencoded");
var input = document.getElementById("text");
var inputData = encodeURIComponent(input.value);
var data = 'text=' + inputData + '&image=' + dataURL;
xhr.send(data);
}
}
}
</script>
</body>
</html>
The big issue when running that with multiple phones is image orientation.
To save computing power many mobiles are just save their sensor data without caring about too much about orientation as long as orientation is written in the exif tag.
Here are the 8 possible orientations
ORIENTATION TOP LEFT 1 top left 2 top right 3 bottom right 4 bottom left 5 left top 6 right top 7 right bottom 8 left bottom
I therefore added canvas rotation / flipping after getting image orientation from https://github.com/blueimp/JavaScript-Load-Image. The revised function now looks like
function resizeAndUpload(file) {
var reader = new FileReader();
reader.onloadend = function() {
var can = document.createElement('canvas');
var ctx = can.getContext("2d");
var thisImage = new Image();
thisImage.src = reader.result;
thisImage.onload = function() {
var max_width = 1500;
var max_height = 1500;
var tempW = thisImage.width;
var tempH = thisImage.height;
if (tempW > tempH) {
if (tempW > max_width) {
tempH *= max_width / tempW;
tempW = max_width;
}
}
else {
if (tempH > max_height) {
tempW *= max_height / tempH;
tempH = max_height;
}
}
can.width = tempW;
can.height = tempH;
ctx.save();
var width = can.width; var styleWidth = can.style.width;
var height = can.height; var styleHeight = can.style.height;
if (orientation>1) {
if (orientation > 4) {
can.width = height; can.style.width = styleHeight;
can.height = width; can.style.height = styleWidth;
}
switch (orientation) {
case 2: ctx.translate(width, 0); ctx.scale(-1,1); break;
case 3: ctx.translate(width,height); ctx.rotate(Math.PI); break;
case 4: ctx.translate(0,height); ctx.scale(1,-1); break;
case 5: ctx.rotate(0.5 * Math.PI); ctx.scale(1,-1); break;
case 6: ctx.rotate(0.5 * Math.PI); ctx.translate(0,-height); break;
case 7: ctx.rotate(0.5 * Math.PI); ctx.translate(width,-height); ctx.scale(-1,1); break;
case 8: ctx.rotate(-0.5 * Math.PI); ctx.translate(-width,0); break;
}
}
ctx.drawImage(thisImage,0,0,tempW,tempH);
ctx.restore();
}
var dataURL = canvas.toDataURL("image/jpeg");
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
location.reload();
}
};
xhr.open('POST', 'index.php', true);
xhr.setRequestHeader("Content-type","application/x-www-form-urlencoded");
var input = document.getElementById("text");
var inputData = encodeURIComponent(input.value);
var data = 'text=' + inputData + '&image=' + dataURL;
xhr.send(data);
}
}
Seems there is a real problem ;-) even with valuable SO comments at hand. In the first instance I tried to float all divs. But even when clearing floats this always left a vertical gap. In a second attempt, I used a table but this wasn’t really responsive design. Next, I tried CSS3 multi-column layout
#container {
margin: 0 auto;
column-count: 3;
column-gap: 2px;
width: 320px;
background-color: white;
}
This works as expected (jsfiddle).

and could be even responsive when adding some code for smaller screens
@media screen and (max-width: 1450px) {
#inner {
max-width:950px;
margin: 0 auto;
-moz-column-count: 2;
-webkit-column-count: 2;
column-count: 2;
}
}
@media screen and (max-width: 950px) {
#inner {
max-width:480px;
margin: 0 auto;
-moz-column-count: 1;
-webkit-column-count: 1;
column-count: 1;
}
}
jsfiddle looks great but we are soon running into another problem. Whenever adding more divs as the database is updated, the whole layout gets re-arranged column-wise which is very confusing to the viewer. The same happens with flexbox (attempt #4), currently there is no CSS solution at all. You need some JS layout cheating (codepen).
aeon.co/essays has a a long and convincing plea
Our shoddy thinking about the brain has deep historical roots, but the invention of computers in the 1940s got us especially confused. For more than half a century now, psychologists, linguists, neuroscientists and other experts on human behaviour have been asserting that the human brain works like a computer … we are not born with: information, data, rules, software, knowledge, lexicons, representations, algorithms, programs, models, memories, images …
computers really do operate on symbolic representations of the world. They really store and retrieve. They really process. They really have physical memories. They really are guided in everything they do, without exception, by algorithms…
The idea that memories are stored in individual neurons is preposterous: how and where is the memory stored in the cell?
Indeed, all NMR studies tell us, that many brain areas are being involved in simple tasks. I just wonder why all the current research money goes into human brain mapping projects? We know, it doesn’t work and it is not just a matter of poor organization.
I particular liked the objection of aeon.co that human consciousness acts like computer software. Just bits and bytes get immoral as shown in the movie Transcendence (2014) with disastrous results for humanity. Or like with the Twitter bot Tay that had to be shut down due to its inability to recognize when it was making offensive or racist statements.
Bacterial (and fungal) gut diversity are believed to influence primary allergic sensitization as well as early vitamin D supplementation. The question is – again – could there be any connection? Continue reading Bacteria, vitamin D and allergy
Die FAZ beklagt in einem Beitrag zu Exzellenzinitiative die Doppelzüngigkeit (“doublespeak”)
Mit einem Wort: Es herrscht in der Kommunikation über die Exzellenzinitiative systematischer doublespeak. Ironische, distanzierte, mitunter gar verächtliche Reden über den Antragsprosastil / über Kollegen, die nur noch mit Antragsstellung und Mitteleinwerbung beschäftigt sind / über die, die als akademische Lehrer scheitern und deshalb Wissenschaftsmanager werden wollen / über die groteske Zeitverschwendung, die die Antragstellung erfordert / über glatte Fehlinvestitionen an Ressourcen und Zeit, wenn ein Antrag scheitert (was ja der statistische Standardfall ist) / über inkompetente und von Eigeninteressen geleitete Gutachter / über die Nötigung, schon bei frisch angelaufenen Projekten an den Verlängerungsantrag zu denken / über die ausbleibende Resonanz auf die allfälligen S(t)ammelbände / über die Reklamesprache der Projekte und die Lancierung neuer turns und keywords / über den Egoismus der jeweiligen Teilprojekte etc. pp. – lästerliche Reden sind der Normalfall.
the 4 minute experiment
Again, the recent own cloud 8 -> 9 updates remained difficult. Modifying the database helped:
update oc_appconfig set configvalue = 'dav/appinfo/v1/webdav.php' where appid = 'core' and configkey = 'remote_files'; update oc_appconfig set configvalue = 'dav/appinfo/v1/webdav.php' where appid = 'core' and configkey = 'remote_webdav'; update oc_appconfig set configvalue = 'dav/appinfo/v1/caldav.php' where appid = 'core' and configkey = 'remote_calendar'; update oc_appconfig set configvalue = 'dav/appinfo/v1/caldav.php' where appid = 'core' and configkey = 'remote_caldav'; update oc_appconfig set configvalue = 'dav/appinfo/v1/carddav.php' where appid = 'core' and configkey = 'remote_contacts'; update oc_appconfig set configvalue = 'dav/appinfo/v1/carddav.php' where appid = 'core' and configkey = 'remote_carddav'; update oc_appconfig set configvalue = 'dav/appinfo/v1/carddav.php' where appid = 'core' and configkey = 'remote_contactsplus';
But only to discover that the new calendar entries were corrupt as found by others
/* show old calendars and count */ SELECT o.calendarid, c.userid, c.displayname, c.uri, COUNT(o.calendarid) FROM oc_clndr_objects o JOIN oc_clndr_calendars c ON o.calendarid = c.id GROUP BY calendarid ORDER BY c.userid, c.displayname; /* show new calendars and count */ SELECT o.calendarid, c.principaluri, c.displayname, c.uri, COUNT(o.calendarid) FROM oc_calendarobjects o JOIN oc_calendars c ON o.calendarid = c.id GROUP BY calendarid ORDER BY c.principaluri, c.displayname;
Maybe I give up on own cloud now.
Vermessen hast reichlich widersprüchliche Bedeutungen. Zum einen bedeutet vermessen aktiv – ich bestimme die genauen Maße. Dagegen bedeutet, ich habe mich vermessen, ich habe etwas falsch gemessen. Und als Adjektiv gibt es nochmal eine andere Bedeutung: ich bin vermessen, meint ich bin überheblich. Continue reading Vermessen
so I am not the only one saying that, her eis the link to the BMJ article
A literature review by James estimated preventable adverse events using a weighted analysis and described an incidence range of 210 000-400 000 deaths a year associated with medical errors among hospital patients.16 We calculated a mean rate of death from medical error of 251 454 a year using the studies reported since the 1999 IOM report and extrapolating to the total number of US hospital admissions in 2013. We believe this understates the true incidence of death due to medical error because the studies cited rely on errors extractable in documented health records and include only inpatient deaths.