It is an interesting data set that has been released by Sci-Hub yesterday. So let’s have a quick look. Continue reading Sci-Hub download statistics are inflated by VPN use
CC-BY-NC Science Surf , accessed 29.04.2026
It is an interesting data set that has been released by Sci-Hub yesterday. So let’s have a quick look. Continue reading Sci-Hub download statistics are inflated by VPN use
Scientific publishers are creating now more and more dynamic PDFs. Why do we know? There is an unexpected loading delay of a PDF from Routledge / Taylor & Francis group that I observed recently. First I thought about some DDos protection, but is indeed a personalized document.

These websites are all being contacted while creating this PDF:
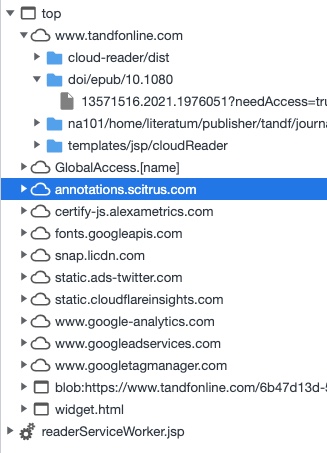
Scitrus.com seems to be part of a larger reference organizer network and links to scienceconnect.io. Alexametric.com is the soon to be retired Alexa internet / Amazon service. Snap.lidcdn.com forwards to px.ads.linkedin.com, the business social network. Then we have Twitter ads, Cloudflare security and Google Analytics. All major players now know that my IP is interested in COVID-19 research. Did I ever agree to submit my IP and time stamp when looking up a rather crude scientific paper?
This is exactly what the German DFG already warned us about last October
For some time now, the major academic publishers have been fundamentally changing their business model with significant implications for research: aggregation and the reuse or resale of user traces have become relevant aspects of their business. Some publishers now explicitly regard themselves as information analysis specialists. Their business model is shifting from content provision to data analytics.
Another paper describes the situation as “Forced marriages and bastards”…
My question is : Will Francis & Taylor even do more? The structure of PDFs allows including objects including Javascript. When examining “document.pdf” using pdf-parser I could not find any javascript or my current IP in clear text. I cannot exclude however that the chopped up IP is stamped somewhere in the document. So I will have try again at a later time point and redo a bitwise analysis. of the same PDF delivered on another day.
At least the DFG document says that organisations might argue that such software allows for the prosecution of users of shadow libraries. While I have doubts that this is legal, we already see targeted advertisement as I received this PDF from Wiley that included an Eppendorf ad.
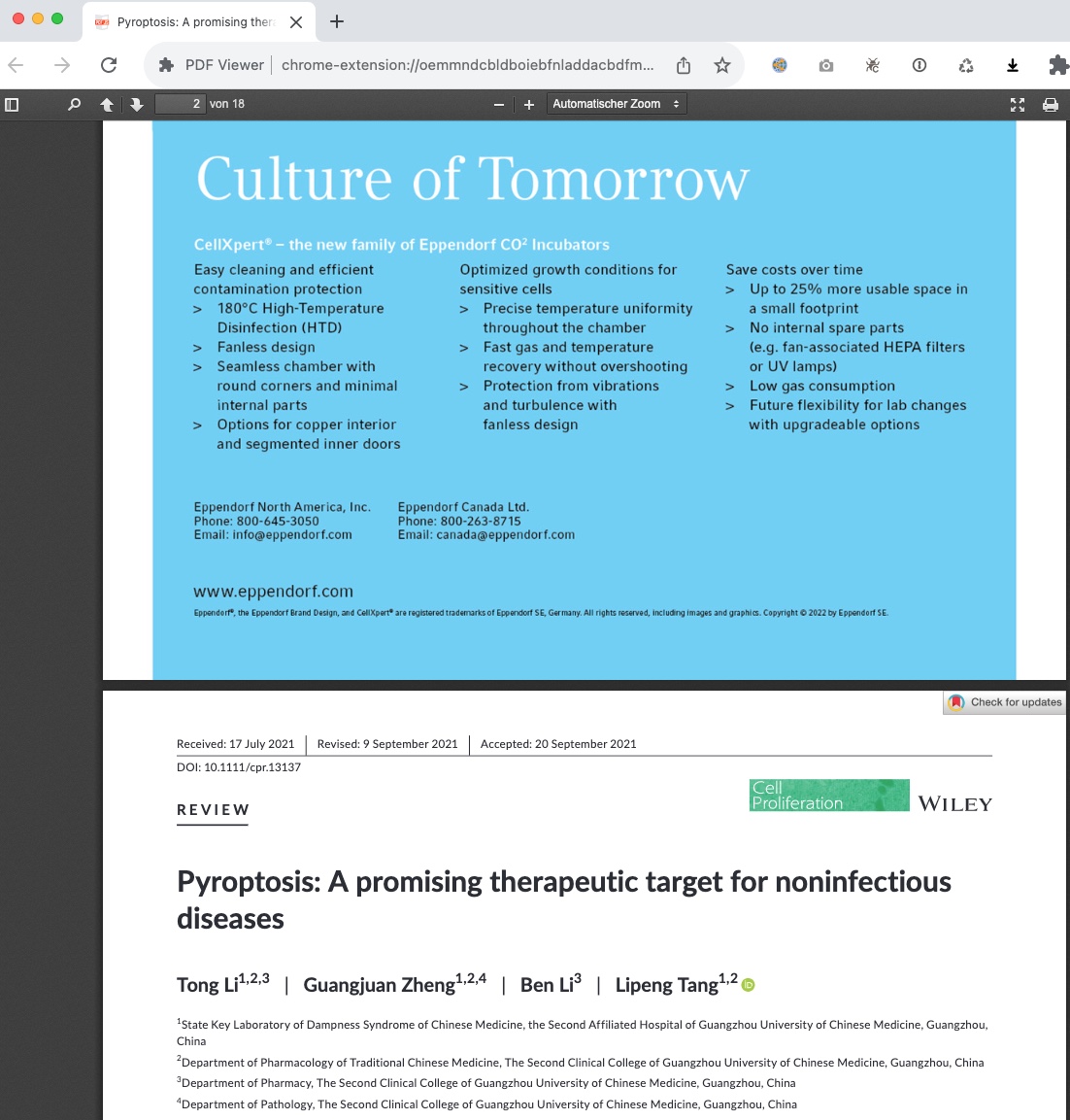
When I downloaded this document a second time using a different IP it was however identical. Blood/Elsevier only let’s you even download only after watching a small slideshow…

Mein erster Computer war ein Sharp PC 1211 als Dauerleihgabe von einem Freund um damit T-test und Wilcoxon Test ab 1983 zu rechnen. Konnte immerhin 1424 Zeilen BASIC Code verstehen und sogar ausdrucken.

Getippt hat mir die handgeschriebene Promotionsarbeit eine Freundin auf einer Olivetti Schreibmaschine mit Zeilenspeicher, die Grafiken entstanden auf einem CAD Plotter! bei dedata. Es folgten dann ein IBM XT im Labor und ein ausgeliehener Schneider PC zu Hause …
Es wäre interessant, die Daten der Photovoltaik zur Steuerung von Steckdosen zu nehmen, um Geräte nur bei Überschuss anzuschalten. Und zwar ohne teure extra Hardware oder einen Smartmeter, der auch noch alle Haushaltsdaten nach aussen funkt quasi als Einladung an potentielle Einbrecher …
Die Kopplung geht einfacher als gedacht. Mein Fronius Wechselrichter ist im Heimnetz unter http://192.168.187.1/solar_api/v1/GetPowerFlowRealtimeData.fcgi zu erreichen. Die aktuelle Wattzahl kommt im json Format.

Die FRITZ!Box kann die Daten zwar im Augenblick nicht verarbeiten (AVM hat dies aber als Produktvorschlag akzeptiert), dafür kann die FRITZ!Box eine Steckdose schalten. Also brauchen wir doch einen zweiten Rechner zur Überbrückung. Ich nehme dafür einen Raspberry Pi Zero (der Pi Zero 2 ist vergriffen, aber auch nicht notwendig) am besten in der Ausführung WH mit Pinleiste. Stromversorgung kommt von einem Netzteil in Nähe des Sicherungskasten/Stromzählers, zum Test über 3 Tage reicht aber auch eine übliche Powerbank.
Zunächst wird das Pi OS auf eine alte micro SD Karte installiert und die Karte in den Zero gesteckt. Sobald der Zero dann im WLAN erscheint, kann man ihn headless d.h, ohne Peripheriegeräte via SSH weiter konfigurieren. Als Messeinheit brauchen wir noch einen USB IR Lesekopf, der am Stromzähler das Blinken der Diode ausliest.
Mit einem cronjob werden im Minutenabstand die Daten abgeholt. Die Abfrage des Logarex Wechselstromzählers funktioniert dabei mit
stty -F /dev/ttyUSB0 300 -parodd cs7 -cstopb parenb -ixoff -crtscts -hupcl -ixon -opost -onlcr -isig -icanon -iexten -echo -echoe -echoctl -echok echo -n -e '\x2F\x3F\x21\x0D\x0A' >> /dev/ttyUSB0 timeout 10s cat /dev/ttyUSB0
Ab einer bestimmten Leistung der PV kann dann die Steckdose eingeschaltet werden, im Prinzip mit
watt=$(curl http://192.168.187.1/solar_api/v1/GetPowerFlowRealtimeData.fcgi | jq '.Body.Data.Inverters[1].P') if [[ $watt -gt 200 ]] then http://fritz.box/webservices/homeautoswitch.lua?switchcmd=setsimpleonoff&ain=13077%200012360-1&onoff=1
Die Hardware passt in ein kleines Gehäuse, die Kosten liegen unter 50€, dazu kommt noch die schaltbare Steckdose.
Update 26.1.22
Der Abfragecode ist nun in ein PHP Skript verpackt und gibt die Daten in einer hübschen d3.js Grafik aus.
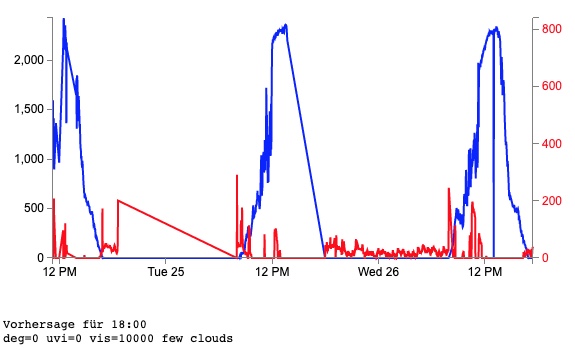
Im Augenblick läuft die Datensammlung inklusive regelmässiger openweathermap Abfrage um später ein R-CNN zur Vorhersage zu programmieren.
Update 23.2.22
Der Lesekopf funktionierte einwandfrei mit dem Drehstromzähler Logarex LK13BDxxxx obwohl die Shell Kommandos nur sehr primitiv in ein PHP Skript eingebaut waren.

Mit dem Einbau eines neuen bidirektionalen Smartmeters SGM-C4-xxxxxx durch unseren Stromversorger funktioniert das leider nicht mehr. Problem ist nicht etwa, daß die Kommunikation nun mit 9600/8/N/1 läuft, das Problem ist daß die binäre SML Zeichen, die nun jede Sekunde kommen, nicht richtig interpretiert werden.
stty -F /dev/ttyUSB0 9600 cs8 -cstopb -parenb timeout 2s cat /dev/ttyUSB0 | od -tx1
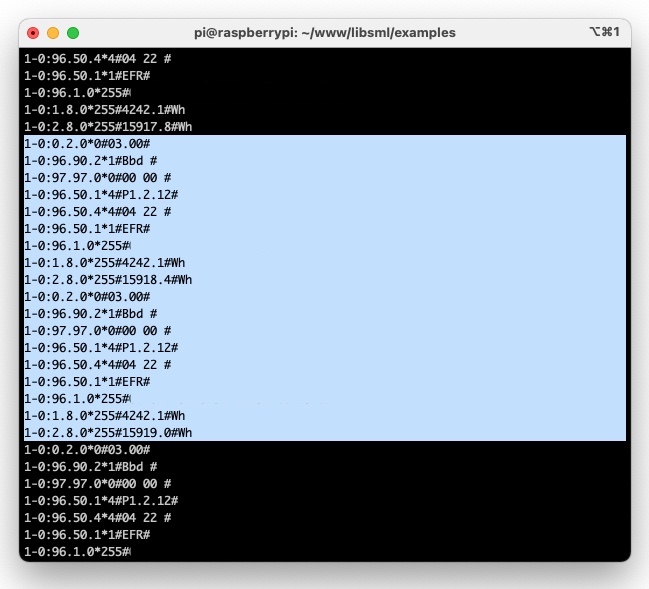
Python downgrade für den php_loader machte wenig Sinn, node liess sich auch nicht auf dem Zero installieren und smeterd brach leider mit einer Fehlermeldung ab. Einzig mit libsml hatte ich aber Erfolg
apt-get install uuid-dev uuid-runtime git clone https://github.com/volkszaehler/libsml cd libsml make examples/sml_server -s /dev/ttyUSB0
Die -s Option ist dabei undokumentiert, aber wichtig denn nur sie findet genau einen Datensatz. Aus Zeilen 1.8.0 und 2.8.0 lässt sich über einen regex Ausdruck der Zählerstand auslesen.
Update 2.3.22
Auf Anfrage kann ich auch das komplette Messgerät verleihen, falls jemand denselben Zähler testweise auslesen oder die SD Karte klonen möchte. Wenn sich der Zero nicht das eigenes WLAN findet, startet er einen eigenen Hotspot, ist damit also autonom überall verwendbar.
Update 6.9.22
Läuft und läuft … Allerdings boote ich nun einmal in 24 Stunden per crontab , da sich manchmal nach 10 Tagen der Zero aufhängt.
0 1 * * * shutdown -r now
Update 8.11.22
Läuft nun seit 10 Monaten ohne einen Ausfall, genauso wie der Gaszähler.
When writing text in Typora, I need Bookends to insert references.
Export to RTF format for creating the bibliography isn’t a big deal but using the new RTF in Typora needs Pandoc on the command line as Typora’s import function is broken.
brew install pandoc pandoc --wrap=none --extract-media=images -f rtf -t markdown myfile.rtf -o myfile.md
Seems that pandoc destroys footnotes and inline images making this combination not a first choice for larger documents.
I have been customizing Atom over the years but moved recently to Typora as it has it all built in. Typora will hopefully work also with long documents (which I haven’t tried so far). There is a

I have lectured about good graphics more than a decade ago – basically introducing Edward Tufte as the “Leonardo da Vinci” of data. With the beginning of 2022 I am now absolutely overwhelmed by the number of excellent tutorials out there. Here is my recommended list
I learned only recently about the 2012 James Bond dialogue in the movie Skyfall where he talks to the new and much younger head of Q branch.
Q: Age is no guarantee of efficiency
Bond: And youth is no guarantee of innovation
Nice to see that I recently earned a new Stackoverflow badge while the last SO report says that 90% of all software developers are younger than 45.
Coming from R the most exciting thing with Python is the incompatibility of the different modules…
While I can recommend the Anaconda Navigator, the following commands work only in the terminal.
Thanks to Nouman945 for help with the original mask_rcnn instructions.
conda create --name matterport python=3.6.13 tensorflow==1.15.0 Keras==2.2.4 h5py==2.8.0 pip conda activate matterport git clone https://github.com/matterport/Mask_RCNN.git cd ./Mask_RCNN-master python -m pip install -r requirements.txt git clone https://github.com/philferriere/cocoapi.git python -m pip install pycocotools python -m pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI wget https://github.com/matterport/Mask_RCNN/releases/download/v2.1/mask_rcnn_balloon.h5 > Mask_RCNN/mask_rcnn_coco.h5 conda deactivate
For detectron I follow basically detectron2.readthedocs.io
conda create --name detectron2 python=3.6.13 tensorflow==1.15.0 Keras==2.2.4 h5py==2.8.0 pip conda activate detectron2 conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 -c pytorch git clone https://github.com/facebookresearch/detectron2.git CC=clang CXX=clang++ ARCHFLAGS="-arch x86_64" python -m pip install -e detectron2 conda deactivate
Last but not least the installed apps:

seit 22.11. gibt es ein neues Portal der DFG
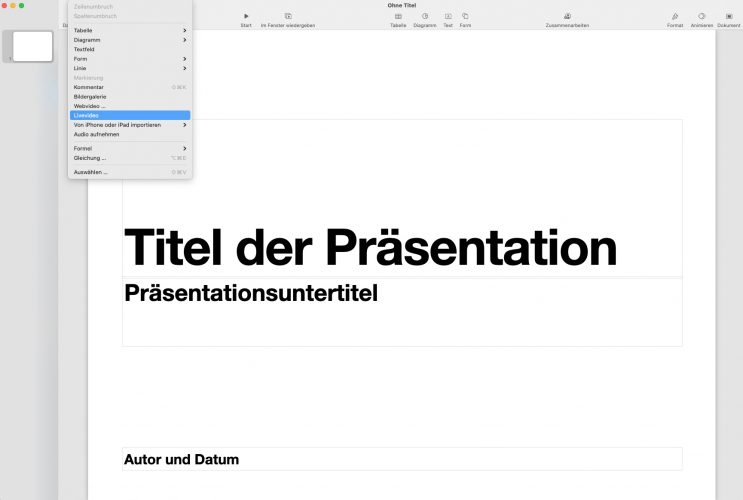
Apple updated last month Keynote with a feature we have been waiting for years – live video which is super cool to show live internet pages from active polls.
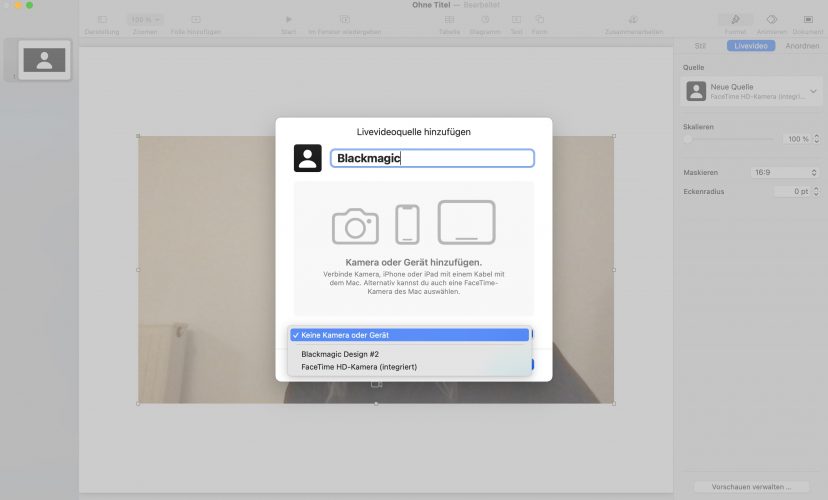
There is no video source connected at the beginning but can can be added from the right side menu.
Unfortunately the virtual camera of OBS is not recognized but I could easily connect my Blackmagic Atem Mini so I have direct access to any source coming from a second computer running Chrome, Ipad with Sketchbook and of course the Z6 HDMI video signal.
A quick comparison without pretending any objectivity
| Open Source | Commercial / Restricted Access | Web | Upper Limit Images | Speed | Sensitivity | Specificity | Comment | |
|---|---|---|---|---|---|---|---|---|
| Image Verification Assistant | N | N | Y | 1 | * | * | * | |
| Forensically | N | N | Y | 1 | *** | * | * | |
| FotoForensics | N | N | Y | 1 | ** | * | * | |
| Imagedup | N | N | Y | >500 | *** | * | * | proof of principle |
| ImageTwin | N | Y | Y | 10 | *** | ** | ** | |
| Lpixel | N | Y | Y | 50? | ? | ? | ? | |
| Proofig | N | Y | Y | 50? | * | */** | */** | |
| Droplets | Y | N | N | 1 | * | * | * | |
| ImageJ | Y | N | N | 1 | ? | ? | ? | |
| Sherloq | Y | N | N | 1 | NA | NA | NA | toolbox |
| figcheck | N | N | Y | 1 | ? | ? | ? | scam? |
| BioVoxxel | Y | N | N | 1 | ? | ? | ? | toolbox |
I believe that all services should be in the open domain while bulk or routine data processing could be a business model.
The Journal of Allergy and Clinical Immunology (JACI) published numerous images that have been heavily modified. For Pubpeer examples see 1, 2, 3, 4, 5, 6, 7…
As I learned recently, this happened without the knowledge of the authors. As the duplications are always at the outer edges and originate from the same image, we assume that JACI publishing service inserted some cloned background” to insert”journal style” letter boxes.
Difficult to understand? Here is an example from the first reference.

JACI is known to ignore misconduct allegations while they are now slowly responding to post publication peer review.
…the duplications occurred when the publisher’s compositor vendor styled the figure panel label for print. The error did not impact the analysis, results, or conclusions of the article. The original figure appears below. The authors were not responsible for the error. Measures have been taken to prevent reoccurrence of this error for which the publisher accepts full responsibility and apologizes.
So photoshopping is no more allowed at the JACI office in Colorado– but who is accepting this “full responsibility”?
29 Aug 2021
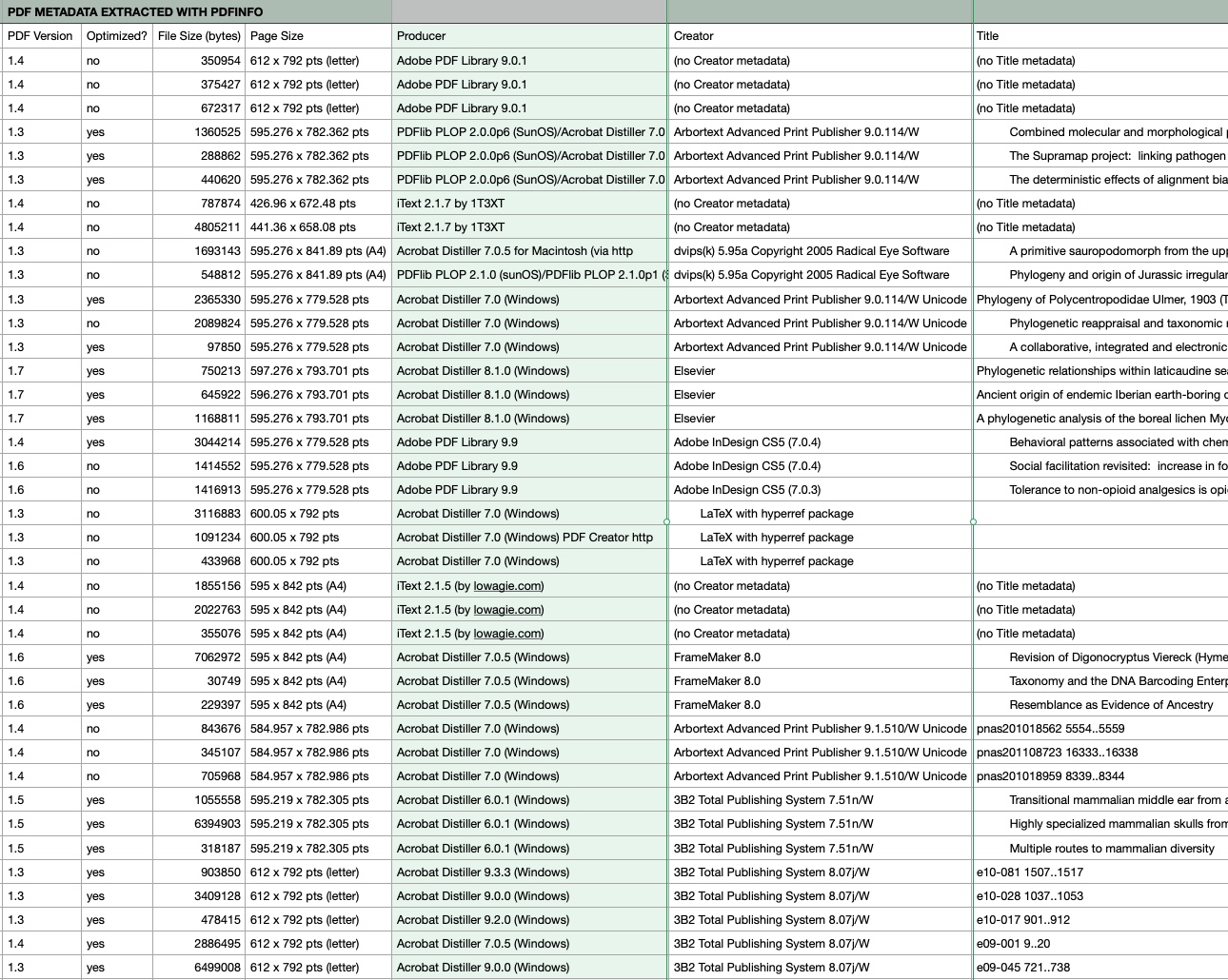
I found only one relevant blog post about PDFs produced by scientific publishers.
Although PDFs are the main formal output nowadays (no more “papers”) there is basically no standardization which meta data should be included in scientifc PDFs. It’s largely due to the software in the production office what’s in the PDF document — a largely underused resource.
This is at least my experience when working on an image duplication pipeline in scientific papers. But test it yourself ….
“The false dichotomy between private interest and public good” by https://www.nuffieldbioethics.org/blog
‘Good’ and ‘public benefit’ are subjective concepts and will vary according to individual perceptions and context. Private and public interest are inevitably intertwined and pitting them against each other creates a false dichotomy. For example, if patients cease to trust their clinicians or more broadly the NHS, public good will suffer. Furthermore, extensive exploration of public attitudes towards sharing medical data has found that people approve in general for their data to be used for medical research and for ‘good causes’, whether environmental, social or medical, but they do not approve of their data to be used for commercial purposes or for powerful companies to profit at society’s expense.