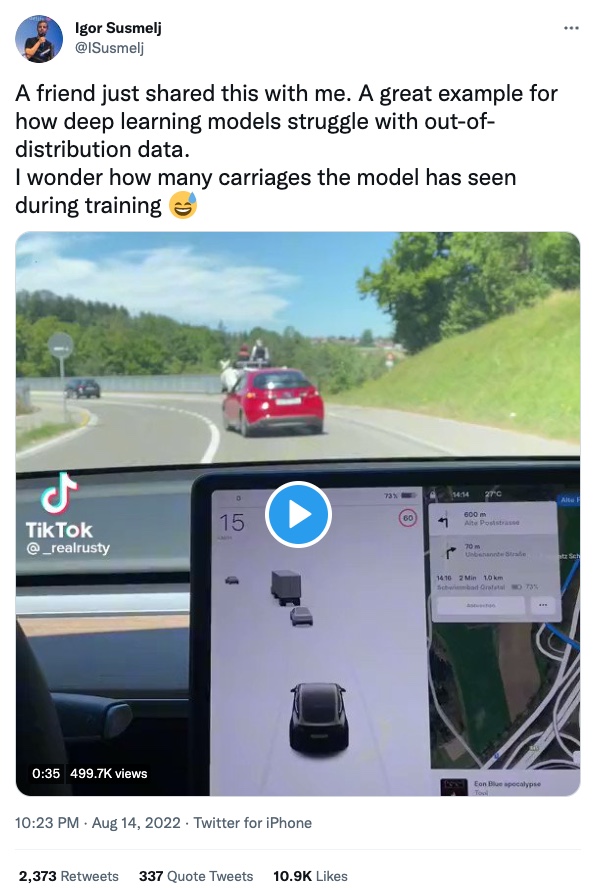
I already had the impression that the technology in some cars is far from being safe for general use. This seems to hold also for drones.
As I needed now to control a DJI Osmo Mobile remotely (and did not find any official app for that) I was looking for the protocol stack to do something by my own. Unexpectedly I found numerous other hacks including drone hallucination using laser beams that let drones think of an obstacle (paper). And yes, there are numerous websites out there that show how to eliminate the built NFZ (no fly zone) and altitude restrictions which is super dangerous.
Given the fact that now even top politicians turn out to be corrupt (in general, in detail), I fear that we will soon have not only Tesla cars but also Amazon cargo drones with the foolish technology that is already delivering newspapers here in Jülich, Germany.