Gravestein discusses the 70 page arXiv paper “Consciousness in Artificial Intelligence: Insights from the Science of Consciousness and 14 indicator properties from 6 areas

TBC
CC-BY-NC Science Surf
accessed 16.01.2026
Gravestein discusses the 70 page arXiv paper “Consciousness in Artificial Intelligence: Insights from the Science of Consciousness and 14 indicator properties from 6 areas
TBC
sleepwatcher(8) System Manager's Manual sleepwatcher(8)
NAME
sleepwatcher – daemon to monitor sleep, wakeup and idleness of a Mac
SYNOPSIS
sleepwatcher [-n] [-v] [-V] [-d] [-g] [-f configfile] [-p pidfile]
[-a[allowsleepcommand]] [-c cantsleepcommand]
[-s sleepcommand] [-w wakeupcommand] [-D displaydimcommand]
[-E displayundimcommand] [-S displaysleepcommand]
[-W displaywakeupcommand] [-t timeout -i idlecommand
[-R idleresumecommand]] [-b break -r resumecommand]
[-P plugcommand] [-U unplugcommand]
DESCRIPTION
sleepwatcher is a program that monitors sleep, wakeup and idleness of a Mac. It can be used to execute a Unix command when the Mac or the display of the Mac goes to sleep mode or wakes up, after a given time without user interaction or when the user resumes activity after a break or when the power supply of a Mac notebook is attached or detached. It also can send the Mac to sleep mode or retrieve the time since last user activity.
Continue reading The missing sleepwatcher manpage
1. What is all about?
Starting with Corona I have been streaming lectures and church concerts. A Macbook and a n old Chromebook, some old iPhones and Nikon DSLR cameras were connected by HDMI cables to a Blackmagic ATEM mini pro. This worked well although there are many shortcomings of HDMI as it is basically a protocol to connect just screens to a computer and not devices in a large nave.
2. What are the options?
WIFI transmission would be nice but is probably not the first choice for video transmission in a crowded space with even considerable latency in the range of 200ms. SDI is an IP industry standard for video but this would require dedicated and expensive cabling for each video sources including expensive transceivers. The NDI protocol (network device interface) can use existing ethernet networks and WIFI to transmit video and audio signals. NDI enabled devices started slowly due to copyright and license issues but is expected to be a future market leader due to its high performance and low latency.
3. Is there any low-cost but high quality NDI solution?
NDI producing videocameras with PTZ (pan(tilt/zoom) movements are expensive in the range of 1,000-20,000€. But there are NDI encoder for existing hardware like DSLRs or mobile phones. These encoders are sometimes difficult to find, I am listing below what I have been used so far. Whenever a signal is live, it can be easily displayed and organized by Open Broadcaster Software running on MacOS, Linux or Windows. There are even apps for iOS and Android that can send and receive NDI data replacing now whole broadcasting vehicles ;-)
4. What do I need to buy?
Assuming that you already have some camera equipment that can produce clean HDMI out (Android needs an USB to HDMI and iPhones a Lightning to HDMI cable), you will need
5. Which devices did you test and which do you currently use?
The Teltonika router and the two Zowietek converter cost you less than 500€, the Obsbot also comes at less than 500€ while this setup allows for semi-professional grade live streams.
6. Tell me a bit more about your DSLR cameras and the iPhones please.
There is nothing particular, some old Nikon D4s, a Z6 and a Z8, all with good glass and an outdated iPhone 12 mini without SIM card.
7. Have you ever tried live streaming directly from a camera like the Insta 360 X3?
No.
8. What computer hardware and software do you use for streaming and does this integrate PTZ control?
I use now a 2017 Macbook (which showed some advantage over a Linux notebook). NDI Video has to be delayed due to the latency of other NDI remote sources. I usually sync direct sound and NDI video with the sound being delayed with +450ms in OBS.
Right now I am testing also an iPad app called TopDirector. The app looks promising but haven’t tested it so much in the wild.
PTZ control can be managed by an OBS plugin, while TopDirector has PTZ controls already built in.
9. How much setup time do you need?
Setting up 2 DSLR cameras and 1 PTZ on tripods with cables takes 30-60-90 minutes . OBS configuration and Youtube setup takes another 15 minutes if everything goes well.
The touchbar is a nice feature of the Macbook when used as multimedia machine because it could be individually programmed. Unfortunately it has been abandoned may for reasons unknown to us. At least it starts now flickering at random intervals in my 2019 Macbook Pro. And nothing helps in the long-term
while only kill touchbar disables it immediately . Could it be a combined hardware / software issue?
While I can’t fully exclude a minimal battery expansion after 200 cycles, the battery is still marked as OK in the system report. The flickering can be stopped by a bright light at the camera hole on top of the display so the second option is also unlikely.
With the Medium hack it is gone during daytime but still occurs sometimes during sleep which is annoying. It seems that even the dedicated Hide My Bar app is only an user-level application that doesn’t have the permissions needed to disable the Touch Bar in lock screen.
Completely disabling the touchbar will not possible as there is no other ESC key. The touchbar there may need replacement as recommended by Apple or just tape on top of it.
GEO hatte im April eine nette Reportage “Achtung, Papierfischchen! Sie kommen mit der Post”
Fotoalben, Akten, Tapeten, Bücher, Zeitungen – nichts und niemand ist vor den kleinen Papierfressern sicher. Alles wird angeknabbert. Papierfischchen, wissenschaftlich Ctenolepisma longicaudata, sind der Albtraum jedes Archivars und Buchhändlers.
Ich werde Kartons und Zeitungen also schneller entsorgen, gekaufte antiquarische Bücher genauer untersuchen und die Ausbreitungswege einschränken.
Bei Befall hilft dann wohl nur noch ein Biozid (wie Envira, eine Mischung von Permethrin und Prallethrin).
There is nothing to comment on the Wittau paper except that AI & paper mills are the second largest thread to science already.
Honesty of publications is fundamental in science. Unfortunately, science has an increasing fake paper problem with multiple cases having surfaced in recent years, even in renowned journals. …
We investigated 2056 withdrawn or rejected submissions to Naunyn–Schmiedeberg’s Archives of Pharmacology (NSAP), 952 of which were subsequently published in other journals. In six cases, the stated authors of the final publications differed by more than two thirds from those named in the submission to NSAP. In four cases, they differed completely. Our results reveal that paper mills take advantage of the fact that journals are unaware of submissions to other journals.
Richard Harris in “Rigor Mortis”
It was one of those things that everybody knew but was too polite to say. Each year about a million biomedical studies are published in the scientific literature. And many of them are simply wrong. Set aside the voice-of-God prose, the fancy statistics, and the peer review process, which is supposed to weed out the weak and errant. Lots of this stuff just doesn’t stand up to scrutiny.
While I don’t like the aggressive posts of forbetterscience.com, Schneider is certainly right about the incredible COVID-19 papers of Bousquet, Zuberbier and Akdis ( for example the recent papers in Clinical and Translational Allergy, Allergy and BMJ which are all not even mentioned in their combined 38 entries over at PubPeer)
It is proposed that fermented cabbage is a proof‐of‐concept of dietary manipulations that may enhance Nrf2‐associated antioxidant effects, helpful in mitigating COVID‐19 severity.
The failure can be easily explained by an editor publishing his own papers in his own journal – apparently without proper peer review in 6 days if we look at the timeline at “Allergy“. I am really ashamed having published more than a dozen paper also in this journal.
Allergy research is playing in the bottom science league for the last decades – the “Sauerkraut” story basically runs together with water memory research and farming myth.
“Free synthetic data”? There are numerous Google ads selling synthetic aka fake data. How “good” are these datasets? Will they ever been used for scientific publications outside the AI field eg surgisphere-like?
There is a nice paper by Taloni, Scorcia and Giannaccare that tackles the first question. Unfortunately a nature news commentary by Miryam Naddaf is largely misleading when writing Continue reading Can ChatGPT generate a RCT dataset that isn’t recognized by forensic experts?
Just one problem: the video isn’t real. “We created the demo by capturing footage in order to test Gemini’s capabilities on a wide range of challenges. Then we prompted Gemini using still image frames from the footage, and prompting via text.” (Parmy Olsen at Bloomberg was the first to report the discrepancy.)
It doesn’t even give more confidence if Oriol Vinyals now responds
All the user prompts and outputs in the video are real, shortened for brevity. The video illustrates what the multimodal user experiences built with Gemini could look like. We made it to inspire developers.
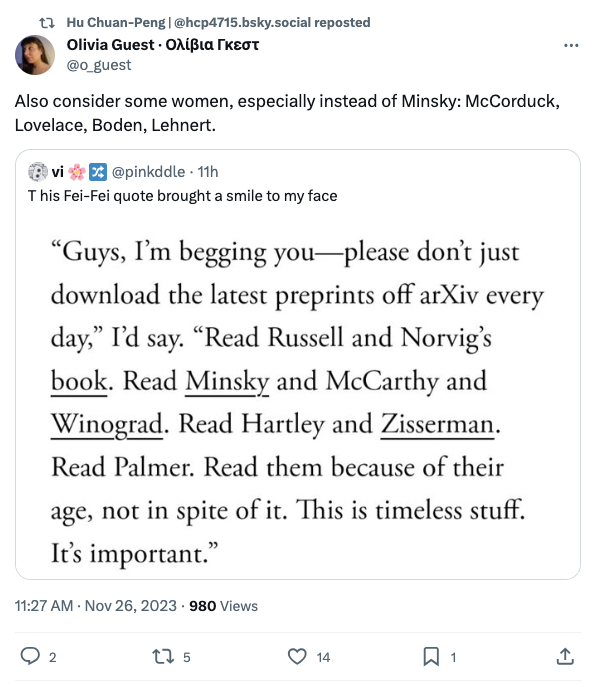
May I also emphasize that AI is a research method suffering form severe flaws as Nature reported again yesterday “Scientists worry that ill-informed use of artificial intelligence is driving a deluge of unreliable or useless research”
A team in India reported that artificial intelligence (AI) could do it, using machine learning to analyse a set of X-ray images. … But the following September, computer scientists Sanchari Dhar and Lior Shamir at Kansas State University in Manhattan took a closer look. They trained a machine-learning algorithm on the same images, but used only blank background sections that showed no body parts at all. Yet their AI could still pick out COVID-19 cases at well above chance level.
The problem seemed to be that there were consistent differences in the backgrounds of the medical images in the data set. An AI system could pick up on those artefacts to succeed in the diagnostic task, without learning any clinically relevant features — making it medically useless.
not even mentioning here again data leaking
There has been no systematic estimate of the extent of the problem, but researchers say that, anecdotally, error-strewn AI papers are everywhere. “This is a widespread issue impacting many communities beginning to adopt machine-learning methods,” Kapoor says.
Die Gedanken sind frei,
wer kann sie erraten?
Sie ziehen vorbei, wie nächtliche Schatten.
Kein Mensch kann sie wissen,
kein Jäger erschießen mit Pulver und Blei.
Die Gedanken sind frei.
Was sich so schön lyrisch bei Hoffmann von Fallersleben anhört, ist eben nur Lyrik des 19. Jahrhunderts. Gedankenlesen fasziniert die Menschen seit König Davids Zeiten, aber ist erst seit kurzem in Ansätzen möglich (MPI)
Das Ergebnis erstaunte Libet, ebenso wie viele Forscher bis heute: Im Hirn der Probanden baute sich das Bereitschaftspotential bereits auf, bevor sie selbst den Willen zur Bewegung verspürten. Selbst wenn man eine gewisse Verzögerung beim Lesen der Stoppuhr annahm, blieb es dabei – der bewusste Willensakt ereignete sich im Durchschnitt erst drei Zehntelsekunden, nachdem die Handlungsvorbereitungen im Hirn angelaufen waren. Für viele Hirnforscher ließ das nur einen Schluss zu: Die grauen Zellen entschieden offenbar an uns vorbei.
Die technische Auflösung geht immer weiter, von der Antizipation einfacher Bewegungsmuster nun hin zur kompletten Bilderkennung im Gehirn “Mental image reconstruction from human brain activity” hier in der geringfügig korrigierten DeepL Übersetzung
Die von Menschen wahrgenommenen Bilder können aus ihrer Gehirnaktivität rekonstruiert werden. Allerdings ist die Visualisierung (Externalisierung) von mentalen Bildern eine Herausforderung. Nur wenige Studien haben über eine erfolgreiche Visualisierung von mentaler Bilder berichtet, und ihre visualisierbaren Bilder waren auf bestimmte Bereiche wie menschliche Gesichter oder Buchstaben des Alphabets beschränkt. Daher stellt die Visualisierung mentaler Bilder für beliebige natürliche Bilder einen bedeutenden Meilenstein dar. In dieser Studie haben wir dies durch die Verbesserung einer früheren Methode erreicht. Konkret haben wir gezeigt, dass die in der bahnbrechenden Studie von Shen et al. (2019) vorgeschlagene Methode zur visuellen Bildrekonstruktion stark auf visuelle Informationen, die vom Gehirn dekodiert werden, angewiesen ist und die semantischen Informationen, die während des mentalen Prozesses benutzt werden, nicht sehr effizient genutzt hat. Um diese Einschränkung zu beheben, haben wir die bisherige Methode auf einen Bayes’sche Schätzer erweitert und die Unterstützung semantischer Informationen in die Methode mit aufgenommen. Unser vorgeschlagener Rahmen rekonstruierte erfolgreich sowohl gesehene Bilder (d.h. solche, die vom menschlichen Auge beobachtet wurden) als auch vorgestellte Bilder aus der Gehirnaktivität. Die quantitative Auswertung zeigte, dass unser System gesehene und imaginierte Bilder im Vergleich zur Zufallsgenauigkeit sehr genau identifizieren konnte (gesehen: 90,7%, Vorstellung: 75,6%, Zufallsgenauigkeit: 50.0%). Im Gegensatz dazu konnte die frühere Methode nur gesehene Bilder identifizieren (gesehen: 64,3%, imaginär: 50,4%). Diese
Ergebnisse deuten darauf hin, dass unser System ein einzigartiges Instrument zur direkten Untersuchung der subjektiven Inhalte des Gehirns wie Illusionen, Halluzinationen und Träume ist.

Verge reports
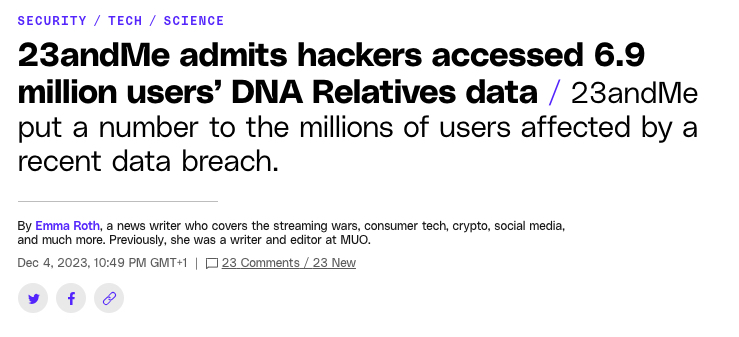
The dubious science is well known – now 23andMe also lied about the number of user affected.
A blog post onextracting training data from ChatGPT
the first is that testing only the aligned model can mask vulnerabilities in the models, particularly since alignment is so readily broken. Second, this means that it is important to directly test base models. Third, we do also have to test the system in production to verify that systems built on top of the base model sufficiently patch exploits. Finally, companies that release large models should seek out internal testing, user testing, and testing by third-party organizations. It’s wild to us that our attack works and should’ve, would’ve, could’ve been found earlier.
and the full paper published yesterday
This paper studies extractable memorization: training data that an adversary can efficiently extract by querying a machine learning model without prior knowledge of the training dataset. We show an adversary can extract gigabytes of training data from open-source language models like Pythia or GPT-Neo, semi-open models like LLaMA or Falcon, and closed models like ChatGPT.
I am not convinced that the adversary is the main point her. AI companies are stealing data [1, 2, 3, 4, 5] without giving ever credit to the sources. So there is now a good chance to see to where ChatGPT has been broken into the house.