
CC-BY-NC Science Surf , accessed 06.04.2026
Mai Thi Nguyen-Kim – laut dem Kommunikationsdienst der Medienbranche Turi2 Deutschlands bekannteste Wissenschaftsjournalistin – brachte in der Vergangenheit immer wieder spannende Videos. Allerdings hat sie sich bei dem Thema Genetik überhoben und ist offensichtlich auch nicht gut in der Wissenschaftsszene vernetzt. Anders sind ihre Aussagen zur Genetik jedenfalls nicht zu erklären.
Ihr Zweifel an dem Rassenbegriff ist ja völlig berechtigt, denn nur Rassisten reden von Rassen. Wir reden schon lange nicht mehr von Rassen bei Menschen, sondern von Populationen, Volksgruppen, Ethnien oder was auch immer (Rassen sind ansonsten die gezielt gezüchtete Tier- oder Pflanzenarten, die sich durch Selektion auf bestimmte Eigenschaften vermehrt haben). Wir reden deshalb nicht mehr davon, weil die Anfang des letzten Jahrhunderts von Anthropologen beschriebenen äusseren Merkmale von Menschen eben nicht mit den Ergebnissen der modernen Genetik überein stimmen. Aber statt dann wenigstens bei dem Thema Populationsgenetik in ihrem Video zu bleiben, zieht sie auch noch eine direkte Linie zum Kolonialismus. Und stellt dann auch noch eine Verbindung zur Kriminalstatistik her. Das ist unseriös und nur der Aufmerksamkeitsökonomie geschuldet.. Continue reading Die unangenehme Wahrheit des Mai Thi Videos
There are several interesting papers on this topic during the last few weeks. The most interesting one was “How universities came to be – and why they’re in trouble now” by Philip G. Altbach. Higher education worldwide is under strain, facing deep financial and political challenges. In the U.S., universities are dealing with major federal funding cuts and political pressure on teaching and research. In the U.K. money troubles are pushing some institutions toward collapse. Global enrolment has exploded from 6 million in 1950 to 264 million in 2023, and by 2024 most countries—except in sub-Saharan Africa—were sending over half of school-leavers to higher education. So we don’t have anymore an elite university but education for the masses.
As higher education became accessible to the masses across the world, research-intensive universities based on the original Humboldtian model have come to represent just a small proportion of all higher education institutions.[…] the rise of populist politics has compounded some of these pressures. Populism has many causes —Rejection of experts, science and evidence-based policy is part of many populist movements.
Therefore we have now less highly qualified scientists at universities who will even move to the private sector. Clara Collier at her blog analyses the historical development.
… something happened to German universities at the turn of the 19th century — they developed a new system that combined teaching with research. Within a few decades, everyone in Europe was trying to copy their model. German scientists dominated chemistry and revolutionized modern physics. They came up with cell theory, bacteriology, the whole laboratory-based model of scientific medicine
The historical origins illuminate why modern universities may be in trouble: if the delicate balance between funding, mission, autonomy, teaching, and research shifts too far, the institution risks losing its raison d’être. All the financial and structural pressures that force now institutions to prioritise revenue, prestige, cost-cutting and global competition rather than education. In addition we have a legitimacy crisis, where universities are no longer seen as the unique centres of knowledge creation and public good – they compete instead with other knowledge platforms and feel more like businesses.
While the above analysis suggested that universities will decline when they lose their grounding in mission, and unity of purpose, a NYT article two months ago suggested that decline already happens by finances and market pressures that force institutions to compromise on programmes, services, and expectations undermining their offer to students that doesn’t stress anymore “ideas” as much as “money & market”.
– Rising administrative and support costs, which have soared in recent decades, even as state legislatures have tightened public spigots.– Higher tuition prices, among other considerations, which have turned off students, who are routinely paying more and oftentimes getting less.– Some academic programs that draw few students.
In the same vein is another Atlantic article on the disruption of the federal research-funding ecosystem (especially via the NIH) which ties into the broader theme of financial/mission distress.
Now many university professors and researchers believe that this special fusion of research and teaching is at risk. “I feel lost,” a research scientist at a top-five university who works on climate and data science told me.
It complements the notion that universities are vulnerable not only to enrolment/tuition pressures and mission drift, but also to external shocks in the research funding system. Many research universities have built major commitments around securing federal research grants and the indirect cost (“overhead”) payments from them. The Atlantic piece argues that when those are threatened, the whole institution becomes fragile.
That ties back to the origin‐story of the modern research university (the teaching + research model) — if the “research” side now collapses, the model itself is under threat. This injects more urgency: it’s not only decades of mission drift and funding pressure, but also sudden regulatory/policy upheavals.

In my career I have experienced all kind of situations where reason often loses not to better logic but to tactics.
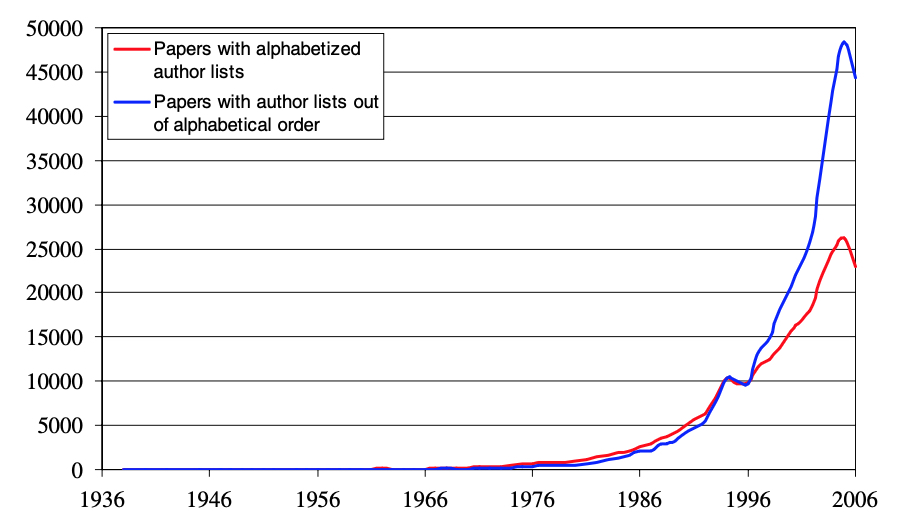
This is the title of a 2009 Stanford academic paper by Justin Solomon that analyzes the history of credit and co-authorship in computer science. The paper argues for a more consistent publishing standard in the field by addressing issues of inconsistent co-authorship, where some contributors may receive credit for minimal work, leading to potential accountability problems.
in fact, the 1993 Ig Nobel prize for “improbable research” in literature was awarded to “E. Topol, R. Califf, F. Van de Werf, P.W. Armstrong, and their 972 coauthors, for publishing a medical research paper which has one hundred times as many authors as pages
Well, and their Fig 4 was only the beginning of the “gaming the system” enterprise…
Editors at even highly ranked scientific journals are now often young staff rather than experienced scientists for several structural reasons.
The business model of modern scientific publishing has changed. High-impact journals have become commercial enterprises rather than academic institutions. Their goals are efficiency, market reach, and brand control. Experienced scientists are expensive and often unwilling to take full-time editorial jobs that pay less than senior academic roles. Hiring younger PhDs, often fresh from postdocs, keeps costs low and allows publishers to maintain centralized editorial teams.
Second, professional editors are easier to train and manage. Publishers prefer editors who can follow company policy and editorial strategy. Senior scientists would bring strong opinions and disciplinary biases and may resist marketing or strategic directives. Younger editors are more adaptable, less attached to specific disciplines, and focused on efficient handling of manuscripts and reviewers.
The prestige gap between academia and editorial work has widened. Decades ago, senior scientists sometimes served as editors between research posts. Today, the reputation and influence of active research far outweigh editorial work, which is now more about managing flow and impact metrics than shaping science. Most experienced scientists therefore stay in academia, while early-career researchers see editing as an alternative career path.
Fourth, publishing houses are driven by profit and high throughput. Companies like Elsevier, Springer Nature, or Wiley operate with constant publication pressure. They depend on rapid editorial decisions to sustain citation rates and subscription value. Young editors working within standardized procedures are faster and cheaper to employ.
Finally, this shift has consequences. It leads to a focus on novelty and newsworthiness over technical soundness, and to reduced capacity for deep scientific evaluation. Editors rely heavily on external reviewers and internal performance indicators such as citation forecasts or altmetrics. The result is a system driven by marketing and efficiency rather than scientific judgment.
In short, modern journal editing has become a professionalized and industrialized process. It is now a job rather than a calling, and youthful, efficient gatekeepers have replaced experienced, skeptical scientists.
(with chatGPT 5 Support)
Jan Lucas Dietrich in der Eule mit “Christlicher Realismus statt evangelikaler Faschismus”
Niebuhr attestiert Amerika einen Exzeptionalismus, in dem auf paradoxe Art und Weise Macht immer wieder mit größter moralischer Schwachheit zusammenkommt. Dass dieser Exzeptionalismus derzeit vor allem von ultra-rechten, fundamentalistischen Christen bespielt wird, zeigte zuletzt die Gedenkfeier für Charlie Kirk. In ihrem Selbstverständnis findet sich auch jenes Muster, das Niebuhr bei faschistischen Gruppierungen seiner Zeit entdeckte: Eine kollektive Hybris, in der die grundlegende Illusion menschlicher Perfektion gepaart mit der Persistenz der Sünde in kruden Selbsterlösungsphantasien gipfelt.
The modern science publishing industry operates much like turbo-capitalism — a system driven by profit maximization, consolidation of power, and resistance to regulation. What once served as a collective effort to disseminate knowledge has turned into a multibillion-dollar business controlled by a few dominant publishers such as Elsevier, Springer Nature, and Wiley. These companies have commercialized access to knowledge itself, transforming the public good of science into a high-priced commodity.
The evolution of the publishing system followed the classic pattern of enshittification. At first, science served the peers, then the users — offering access, visibility, and academic communication. Then publishers as peripheral service provider began to exploit those users to favor their paying institutional customers, tightening control over access and pricing. Finally, they turn on those very customers, extracting maximum profit while degrading service, fairness, and trust, until the entire ecosystem becomes a hollow structure of metrics and monetization.
Just as financial elites resisted government oversight, major publishers oppose reforms that would curb their profits. They lobby against open-access mandates, hide profit structures behind opaque pricing, and maintain control through prestige and impact metrics that entrench their market dominance. Their profits — often higher than those of Apple or Google — depend on free academic labor: scientists write, review, and edit for free, while universities must then pay to read their own work back.
Equity and fairness are collateral damage in this system. Article processing charges reaching thousands of dollars exclude poorer institutions and researchers from full participation. The ideal of open, global science is replaced by a tiered system where access and influence depend on wealth and affiliation.
Equally revealing is the industry’s attitude toward corrections and retractions. In a healthy scientific ecosystem, acknowledging and correcting errors is vital. But in the turbo-capitalist logic of publishing, retractions resemble market regulations — they threaten reputation, weaken brand value, and risk financial loss. Publishers therefore often delay or resist corrections, preferring to protect the façade of flawless output over the integrity of the scientific record.
This distorted environment also shapes scientific behavior itself. Way too many self-assigned researchers, under immense pressure to build careers in a metric-driven system, quickly learn how to “game the system”. Even without proper training or deep experience, they chase citation counts, impact factors, and quantity over quality — optimizing for visibility rather than understanding. The system rewards the appearance of productivity, not the slow and rather uncertain process of genuine discovery.
Thus, the science publishing industry reproduces the same pathologies seen in unregulated capitalism: profit before accountability, personality show before truth, and career before fairness. In this turbo-capitalist model, we have learned the price of everything — but the value of nothing. To restore science to its purpose — the open pursuit of truth — it is not enough to call for open access. The entire system must be rebalanced away from speculative prestige and back toward collective responsibility, transparency, and genuine public knowledge.
(with chatGPT 5 support)

(with chatGPT 5 support)
Ein phänomenal guter Artikel von Markus Beckedahl
Vier Engpässe der digitalen Abhängigkeit
Cloud und Datenräume.
Kommunen, Kliniken, Universitäten speichern hochsensible Daten bei wenigen Hyperscalern. Google. Microsoft. Amazon. Preisänderungen, API-Zäune, proprietäre Formate. Der „Hotel-California-Effekt“: Einchecken geht leicht. Auschecken fast nicht.
Plattform-Öffentlichkeit.
Sichtbarkeit wird verkauft – nicht verdient. Empörung skaliert besser als Nuance. Weil Empörung Aufmerksamkeit bringt. Und Aufmerksamkeit bringt Werbegeld.
Hardware und Chips.
Lieferketten sind fragil. Fällt ein Werk in Asien aus, spürt Europa es in Unternehmen und Fabriken. Und Trump droht bereits, Exportbeschränkungen auf Chips zu verhängen: Wenn wir in Europa unsere Regeln zur Plattformregulierung durchsetzen.
Software-Monokulturen.
Standard-Pakete von Microsoft dominieren Verwaltungen und Bildung. Lock-in frisst Innovationskraft, und damit auch unsere Verhandlungsmacht.
Konsequenz:
Wir sind erpressbar. Preislich. Technisch. Ökologisch. Politisch.

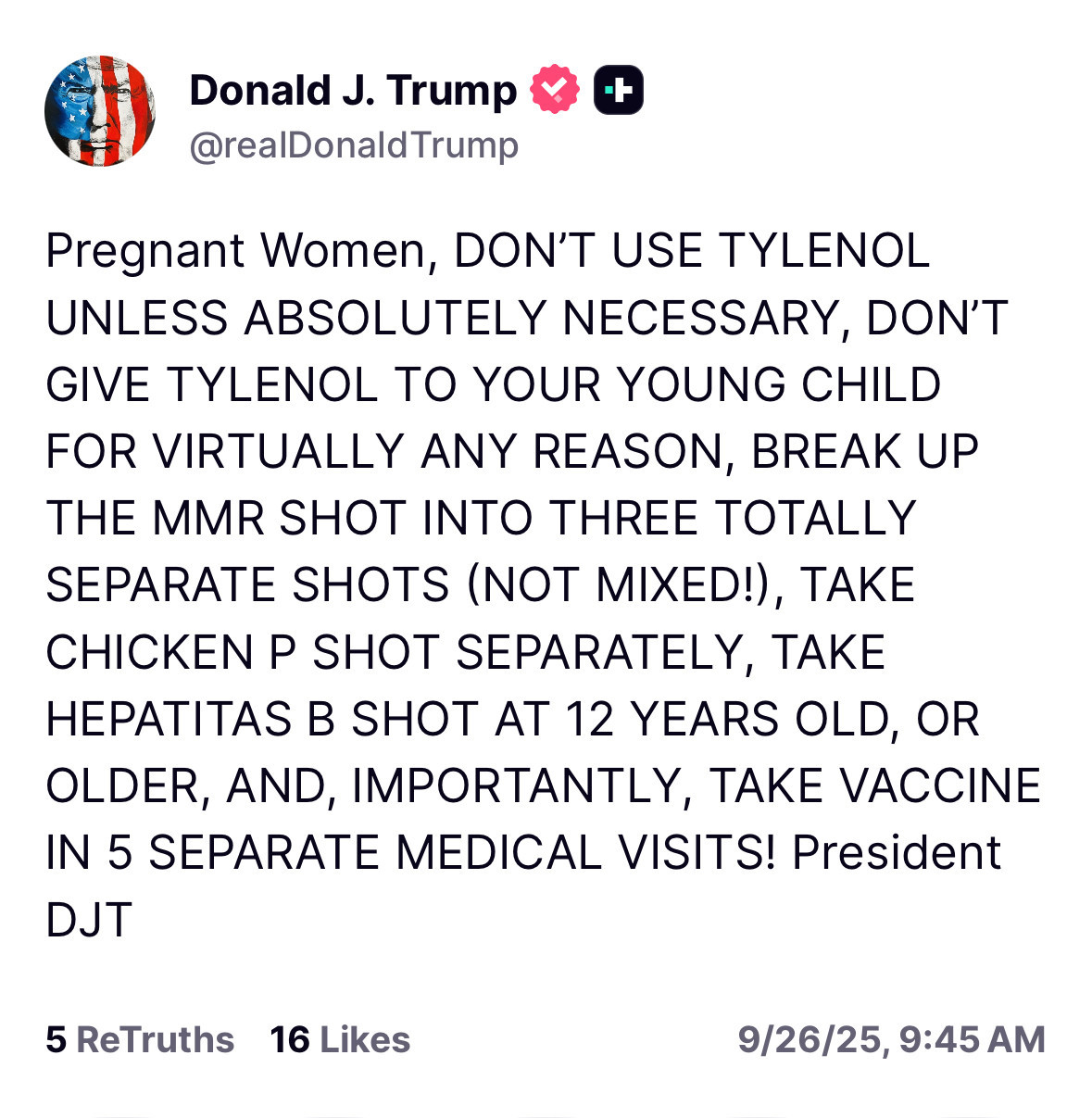
If paracetamol use in pregnancy may cause later autism spectrum disorder has received public interest recently.
Robert J Lifton wrote in “Losing reality”
Trump is different. His solipsism is sui generis. He is psychologically remarkable in his capacity to manufacture and continuously assert falsehood in the apparent absence of psychosis.
Not unexpected the advice was rejected by basically all medical professionals. Commentaries are raging in Nature, BMJ , The Lancet, JAMA and even the WHO. Continue reading Paracetamol and autism in “Environmental Health”: A dubious paper that made politics
Ask this question chatGPT – and it starts rattling like a shaken pinball machine…

Here is an explanation of that phenomenon by Brian Huang
if the model wants to output the word “hello”, it needs to construct a residual similar to the vector for the “hello” output token that the lm_head can turn into the hello token id. and if the model wants to output a seahorse emoji, it needs to construct a residual similar to the vector for the seahorse emoji output token(s) – which in theory could be any arbitrary value, but in practice is seahorse + emoji in word2vec style.
The only problem is the seahorse emoji doesn’t exist! So when this seahorse + emoji residual hits the lm_head, it does its dot product over all the vectors, and the sampler picks the closest token – a fish emoji.
For an even longer version see [here].
Bonus 1 – here is a my seahorse image taken at the Musée océanographique de Monaco last week from its wonderful collection. Let‘s forget the virtual world and preserve the real one.

Bonus 2 – the answer to a long-standing question: The origin of male seahorses’ brood pouch!
Over the years I have experimented with a wide range of navigation systems, each reflecting a particular stage in the technological evolution of digital mapping. My journey began with the bulky but legendary Garmin 60 CSX, a device that, despite its size, quickly became a classic among outdoor enthusiasts due to its reliability and precision – basically as Tom Tom for car navigation. At that time, creating and managing routes still required the rather clunky but indispensable Garmin BaseCamp software, where the first digital maps were painstakingly constructed and transferred to the device. Continue reading A long journey
The epidemic started with a few cases during the winter holidays, increased exponentially afterwards including significant more cases by beer festivals and another significant excess of cases following the election that occurred in Bavaria only. Compared to other German countries, Bavaria reached the highest prevalence which could not be reversed by even the most restrictive containment measurements. To be effective, NPIs need to applied early, if possible even before the beginning of the exponential phase.
When you look back, what was the most momentous mistake in the pandemic response?
Farrar: The biggest mistake was that we didn’t take it seriously enough in the first six weeks of 2020. It was the time when a pandemic could still have been prevented. From the beginning of January, it was clear what was happening in Wuhan. By the end of January, it was clear how dangerous the situation was. And even though this information was available, the rest of the world didn’t act until March – two critical months passed in which the virus was spreading. Instead, we had a U.S. President Donald Trump, who dismissed what was happening as “kung flu,” and in Europe, at least in the UK, there was a sense that this was all happening in faraway China, and northern Italy was also somehow different – it won’t be so bad here. It was a kind of complacency, the arrogance of exceptionalism.