CC-BY-NC Science Surf , accessed 21.07.2026
Unter dem Titel – wenn auch ohne Fragezeichen – steht auf Feinschwarz ein lesenswerter Beitrag.
Beiträge aus den Kirchen hingegen sind rar und erschöpfen sich in der Regel in allgemeinen Appellen: KI müsse ethischen Grundsätzen genügen und der Menschenwürde dienen (Rome Call for AI Ethics, Vatikan, 2020), dürfe nicht über Tod und Leben von Menschen entscheiden (Antiqua et nova, Vatikan, 2025) und müsse der menschlichen Freiheit dienen (Freiheit digital, EKD, 2021). …
Bislang jedenfalls reichen die Thesen der kirchlichen Verantwortungsträger nicht bis in die Gemeinden hinein: auf der Kanzel und am Ambo, in KFD und Seniorengruppen ist Künstliche Intelligenz bislang nur selten Thema. Diese pastorale und theologische Lücke ist fatal. Denn die Provokation durch KI zielt nicht nur auf Ethik und Gesellschaft, sondern ins Herz des christlichen Glaubens selbst.
Nicht nur, dass ich auch schon erlebt habe, daß eine Predigt verdächtig nach KI klang; auch ich selbst habe erst letzte Woche von chatGPT etwas wissen wollen (nämlich wie die kognitive Disssonanz von Erwählung und kriegführenden Gott in Joel 32 und die Aussagen der Bergpredigt bei Evangelikalen wie John Stott aufgelöst wird – es kam nur blabla).
Meistens können wir aber, wie Michael Brendel richtig schreibt, mit den Antworten etwas anfangen. KI hat mehr theologische Bücher wie ich inkorporiert und “kennt” die Bible besser als ich. Und damit haben wir eine massive Provokation für den Glauben, denn KI ist wortgläubiger, als wird denken.
Der Johannesprolog bringt eine Hauptaussage des Neuen Testaments auf den Punkt: Dass das Wort göttlich ist. Gott zeigt sich nicht nur in Dornbüschen, Feuersäulen und Naturkatastrophen, sondern er kommuniziert verbal mit den Menschen. Die Gläubigen auf der anderen Seite können ihre Anliegen, ihr Lob und ihre Klagen über das Wort vor Gott bringen. Offenbarung, Liturgie und Lehre sind sprachlich vermittelt. Sakramente erlangen erst durch Worte ihre Gültigkeit. Und schließlich: Der Logos, das göttliche Wort, ist in Jesus Christus Mensch geworden. Das Wort Gottes wirkt also in der Sinn-, Heils- und Offenbarungsdimension. Und in diese Zone dringt nun Künstliche Intelligenz ein. Seit 2022 kommunizieren nicht mehr nur Menschen mit Menschen über das Medium Wort, nicht mehr nur Gott und Mensch. Seit der Veröffentlichung von ChatGPT gibt es eine kommunikative Instanz, die über Sprache Bedeutung schafft.
KI redet dabei sehr opportunistisch – jedenfalls die drei LLMs, die ich als Referenz hier habe. Sprachmodelle lernen aus massiven Mengen menschlicher Texte wo die (schriftlichen) häufigsten Muster in Dialogen eben sind: zustimmen, erklären, beschwichtigen, freundlich sein. Wenn ein Thema unklar, strittig oder risikobehaftet ist, wählen Modelle oft risikoloseste Antwort. Das wirkt wie Nach-dem-Mund-Reden, ist aber eigentlich nur eine Absicherungsstrategie. Und natürlich hat ein Modell hat keine eigenen Überzeugungen (wenn es nicht gerade wie Grok in eine bestimmte Richtung kanalisiert wird) sondern wird nur die statistisch wahrscheinlichste Antwort produzieren.
Ohne eine eigene Position kann ein LLM nicht "widersprechen", die meisten Dreijährigen können das besser!
Die evangelische Publizistin Johanna Haberer etwa fragt pointiert, ob der Mensch sich mit KI nicht ein Ebenbild schaffe, so wie Gott sich mit den Menschen ein Ebenbild geschaffen habe. Natürlich ist der Unterschied zwischen beiden Schöpfungsakten fundamental. Ihre Schlussfolgerung trifft aber ins Schwarze: Hier wie dort stelle sich die Frage nach Verantwortung und Kontrolle.
Johanna Haberer, einer der beiden Pfarrerstöchter, trifft in der Tat den Punkt. Und so können wir auch die 3 Fragen von Brendel eindeutig beantworten.
Wie weit ist es vom Status Quo bis zur göttlichen Allwissenheit?
KI ist nur da beeindruckend wo es um gedruckte Texte geht und ihre seelenlose Reproduktion. Da immer wieder Halluzinationen auftreten, kann man:frau sich nicht auf Antworten verlassen.
KI hat schon heute Macht. Wird diese irgendwann zur Allmacht?
Da bleibe ich skeptisch, siehe Antwort auf die letzte Frage – Sprachmodelle werden immer unsere Kontrolle brauchen.
KI-Chatbots sind immer erreichbar, immer freundlich, immer hilfsbereit und scheinbar stets auf der Seite der Anwender*innen - Ist das vielleicht schon Allgüte?
Natürlich nicht – es ist die Absicherungsstrategie von oben. Nota bene:

Wilmshurst about COPE then
The Committee on Publication Ethics (COPE) was formed "to address breaches of research and publication ethics". It was a discussion forum providing advice for editors. Its aims were to find practical ways of dealing with issues of concern and to develop good practice. At that time, the members consisted of a small number of editors of medical journals in the BMJ publishing group and the Lancet. There were two individuals who were not journal editors - Professor Ian Kennedy (subsequently Sir Ian Kennedy) and me.
and now
The majority of COPE's income is from large publishing houses that obtain COPE membership for their entire portfolio of journals. Because some publishers have enrolled more than one thousand journals and Springer Nature has enrolled more than 3000 journals, there should be a question as to whether all the editors of the journals that are members of COPE are truly signed up to adhere to COPE principles and practices, rather than passively complying with the policy of their publishers. This arrangement also means that COPE does not know precisely how many members it has because publishing houses do not keep COPE informed about the number of journals in their stable. Individual journals can enrol for a small fee. COPE makes a selling point of the fact that COPE membership enables journals to use the COPE logo.

SPIEGEL: Is money enough?
Wilmshurst: I think for many of them enough money is all they need, really. I mean, most people have a price. But of course you have to be very friendly with them, you have to go and talk to them, have lunch with them, discuss the research. They have to forget that it is your aim to make the maximum amount of money.
SPIEGEL: And what if the professor produces results in a trial that we don’t like?
Wilmshurst: You have made the principal investigator sign a confidentiality agreement beforehand, so that you have control over the data. And you may put into the contract arrangements for a bonus in case of a positive result. (grins) This may help the researcher interpret the data in a more favorable way for you.
SPIEGEL: But there’s one obstinate researcher who keeps insisting on publishing negative results. And he doesn’t accept the bribe that we offer him. What now?
Wilmshurst: Well, you can try and discredit him, you can try to ruin his reputation and cast doubts on his results. That’s what was done with me. And then in the end you can sue him. The threat is often enough to keep him quiet.
please read the FULL interview at the link above
I sent chatGPT 5 the new JCI piece and here is what I got:
The editorial opens by invoking the new federal plan "Restoring Gold Standard Science” a phrase so inflated that it already tests the reader's pain threshold before the first paragraph is over.
Rather than examining what this initiative actually changes, the authors simply echo its vocabulary, "rigor," "reproducibility," "transparency" - as if repetition itself could restore credibility. The JCI editorial "Publishing gold standard science" may not be offensive or incompetent, but it comes across as self-congratulatory and bureaucratic-essentially a polished form of institutional advertising.
It mistakes bureaucratic slogans for substance
The authors repeat official NIH language-"rigor," "reproducibility," "transparency," "data sharing"-without analyzing what these terms achieve in practice. The piece confuses administrative formality with scientific reform.
"We encourage the NIH to recognize publishers' role in conveying research results with transparency and accuracy."
Such sentences state the obvious but contribute nothing analytic. They reinforce policy orthodoxy rather than scrutinize it.
It rehashes two-decade-old debates
Most of the text is a retelling of Begley & Ellis (2012) and Freedman & Inglese (2014). The authors restate familiar concerns about irreproducibility but add no evidence or theoretical insight-just a timeline of NIH initiatives already well known to anyone in biomedical research.
It presents correlation as insight
The figure showing that SciScore doubled between 2000 and 2012 but stagnated after 2014 directly contradicts the claim that the NIH "Rigor and Reproducibility" framework improved research quality. Instead of confronting that, the authors offer speculation about funding.
"We hypothesize that in the US, underfunding also threatens R&R. ... It would be valuable to know what accounted for this apparent improvement."
This turns a negative result into vague conjecture, avoiding the obvious conclusion that the framework had little measurable effect.
It functions as self-promotion
Large sections describe JCI's internal procedures-manual QC, data policies, peer-review traditions-without connecting them to measurable improvements in reproducibility.
"In 2025, our staff began manual quality control measures of high-throughput sequencing and proteomic datasets prior to acceptance."
The tone resembles a corporate sustainability report more than a scientific analysis.
It trivializes the reproducibility crisis
Although the authors admit that there is no evidence of better translation from these reforms, they close with uplifting boilerplate.
"Editors, reviewers, NIH-supported scientists, and the scientific community will continue to work with the NIH... This is a noble and worthy cause for all of us to unite in advancing together."
The conclusion replaces reflection with ceremony.
It uses circular logic about peer review
The authors argue that disagreement among reviewers is proof of rigor, not a sign of inconsistency.
"Peer review... includes disagreement and dissent - hallmarks of scientific progress."
This equates friction with validity; dissent becomes self-justifying evidence that the process works, which is logically empty.
It exemplifies performative virtue
Frequent references to "accountability," "taxpayer dollars," and "public trust" suggest moral legitimacy but not measurable outcomes. The piece sounds reassuring rather than investigative.
"Calls for restoring Gold Standard science are said to be motivated by the erosion of public trust in science."
This is a rhetorical maneuver-invoking civic virtue while sidestepping the deeper problem of perverse incentives, selective reporting, and impact-factor economics.
It relies on inflated rhetoric
Expressions such as "robust education of scientists," "gold standard science," and "noble and worthy cause" give the essay a sermon-like tone. The writing feels more like grant-language or an internal memo than the reflective editorial it claims to be.
Summary
The editorial is so shallow not because it contains factual errors, but because it exemplifies performative concern for rigor: an official text celebrating reproducibility while offering no reproducible evidence. It turns the language of reform into a form of self-validation, mistaking compliance with substance.
Postscript June 2026: Eickelberg could have written this differently. Kahn et al. demonstrated in Diabetes Care what an editorial of this kind looks like when taken seriously: concrete data (89% drop in NIH funding announcements, 66% fewer grant awards, 304 interrupted clinical trials), plain language, and the willingness to name political interference directly - at personal cost. That is the difference between performative concern for scientific rigor and actual civic courage.
I had been at previous HUGO meetings where just by alphabetic order WJST followed WATSON. But I had never been happy about that … Here are two obituaries on Jim Watson, the first is Titan of science with tragic flaws in Science
Nathaniel Comfort, a science historian at Johns Hopkins University who early in his career worked as a writer at CSHL, is completing a biography of Watson, which he has been researching for more than a decade. The working title is American Icarus, a reference to hubris. "Watson was the most important and most famous scientist of the 20th century, and the most infamous of the 21st, and in both cases, the reason is due to his genetic determinism," says Comfort, who says his subject was guilty of "over believing in the power of DNA."
And another from one of my favorite blogs Lionel Pachter. The official CSHL release is crossed out here
As an author, Watson wrote two books at Harvard that were and remain best sellers. The textbook Molecular Biology of the Gene, published in 1965 (7th edition, 2020), changed the nature of science textbooks, and its style was widely emulated.
In this textbook Watson got the central dogma wrong, presenting it in a profoundly misleading way. (source: Matthew Cobb, 2024).
The Double Helix (1968) was a sensation at the time of publication. Watson's account of the events that resulted in the elucidation of the structure of DNA remains controversial, but still widely read.
Prior to the publication of The Double Helix, Francis Crick wrote that "If you publish your book now, in the teeth of my opposition, history will condemn you". Watson published the book anyway (source: letter by Francis Crick, 1967) .
Nevertheless last week I had an honorable encounter with the esteemed colleague Peter Wilmshurst commenting also at PubPeer on a trial that went wrong.
Wilmshurst is one of the real heroes in an era where an entire generation of scientists is in danger of sinking into the mud.
Given my interest in photography and forensic image analysis, only now I had the chance to the read the full AP documentation of the “Napalm Girl”. It is a cruel and exciting story but a perfect example of provenance research.
Any effort to reconstruct what happened on the road using available footage is going to be imperfect, with a wide margin for error. It's important to keep in mind this took place in an analog world, where film stock and camera rolls were a finite resource… [Ut’s Peentax] camera was tested by AP on April 18, 2025. The results appear to show very clear similarities to the famous image and are another marker to suggest that the famous image was likely taken with a Pentax. The negative images do not match exactly. The camera itself seems to be in mint condition, so it is unlikely to have been used in combat for any length of time, and given the date of manufacture, could not have been inherited from Ut's brother. The investigation showed Ut owned Pentax cameras and used Pentax cameras
while covering the war. It does not prove he held a Pentax in Trang Bang on June 8, 1972.
Jörg Spitz ist wohl nicht der geeignete Experte für dieses Thema – es sei denn, als würde man auch Wolfgang Wodarg, Michael Meyen, Sucharit Bhakdi oder Stefan Homburg zu COVID befragen wollen.
Daher erspare ich mir die Fehlersuche in dem MMW Fortschr Med. 2025; 167 (S3) Artikel, in dem Spitz am Ende erklärt
Der Autor erklärt, dass er sich bei der Erstellung des Beitrags von keinen wirtschaftlichen Interessen leiten ließ. Er legt folgende potenzielle Interessenkonflikte offen: keine.
Der Verlag erklärt, dass die inhaltliche Qualität des Beitrags durch zwei unabhängige Gutachten bestätigt wurde. Werbung in dieser Zeitschriftenausgabe hat keinen Bezug zur CME-Fortbildung. Der Verlag garantiert, dass die CME-Fortbildung sowie die CME-Fragen frei sind von werblichen Aussagen und keinerlei Produktempfehlungen enthalten.
Gleichzeitig vertreibt Spitz aber sein “digitales Event Paket” online zur umstrittenen Hochdosis Vitamin D Therapie für 149€.
Ich hätte das nicht vermutet, aber Vitamin scheint doch ein lukratives Geschäftsmodell zu sein auch wenn man mit der Substanz selbst nichts verdienen kann. So hat medwatch schon vor längerer Zeit festgestellt
Hinter der Seite steckt der Nuklearmediziner, Buchautor und selbsternannte Präventionsexperte Jörg Spitz. Und: Vitamin D scheint eines seiner Lieblingsthemen zu sein, so hat er bereits fünf Ratgeber zu dem Vitamin veröffentlicht. Zudem betreibt er ein ganzes Netzwerk aus verschiedenen Internetseiten, die sich allesamt um Vitamin D und weitere Nahrungsergänzungsmittel drehen, etwa die Akademie für menschlichen Medizin (AMM). Die GmbH machte in 2019 einen Umsatz von 225.000 Euro - Spitz ist ihr alleiniger Mitarbeiter.
Die Aktiva am 31.12.2021 waren dann 373.000 €.
Und die Referenten der spitzen-praevention.com ? Ein echtes Panoptikum , die meisten ohne wissenschaftliche Qualifikation, dafür aber mit Missionseifer.
Und die “seriösen” Experte darunter? Alle umstritten – zumindest was chatGPT an Quellen ausspuckt – hier zur eigenen Überprüfung, alles ohne Gewähr. Continue reading Wer braucht wann wieviel Vitamin D und warum?
There is an interesting observation by Nick Brown over at Pubpeer who analysed a clinical dataset (see also my comment atthe BMJ)
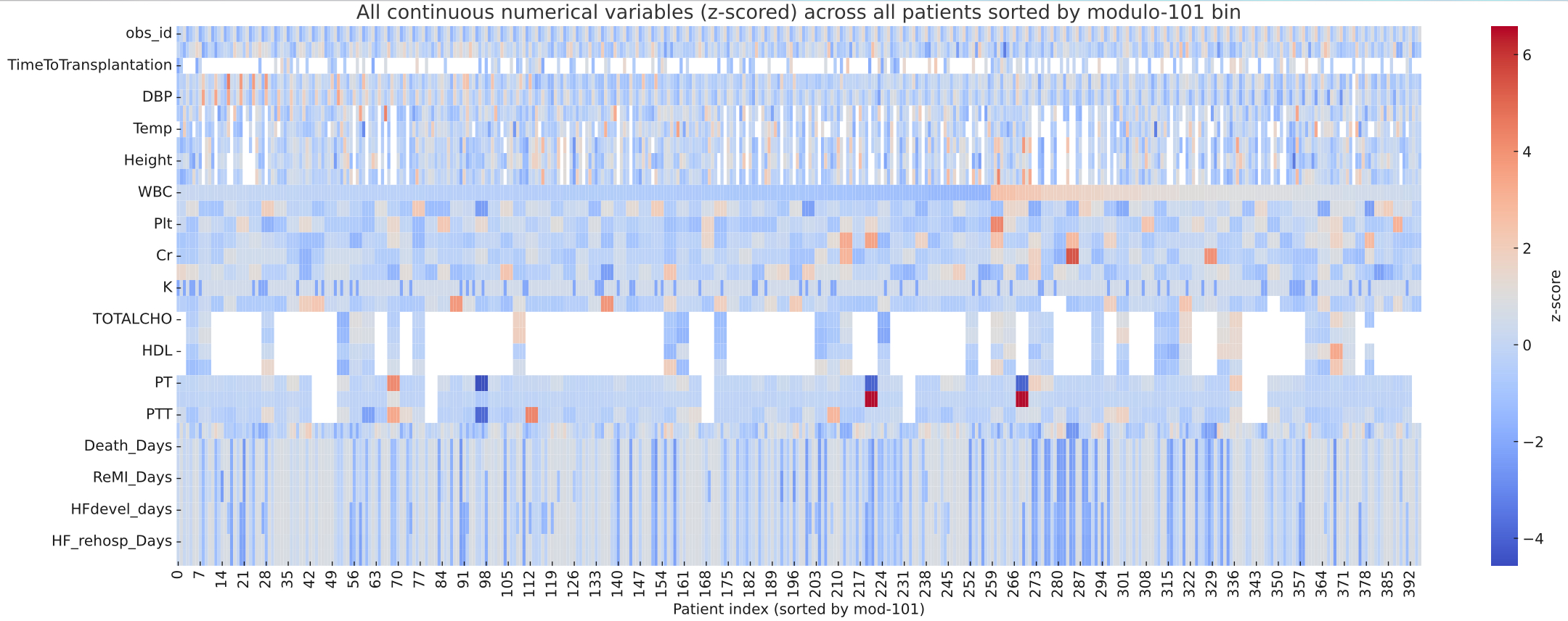
…there is a curious repeating pattern of records in the dataset. Specifically, every 101 records, in almost every case the following variables are identical: WBC, Hb, Plt, BUN, Cr, Na, BS, TOTALCHO, LDL, HDL, TG, PT, INR, PTT
which is remarkable detective work. By plotting the full dataset as a heatmap of z scores, I can confirm his observation of clusters after sorting for modulo 101 bin.
How could we have found the repetitive values without knowing the period length? Is there any formal, data-agnostic detection method?
If we even don’t know the initial sorting variable, it may makes sense to look primarily for monotonic and nearly unique variables, i.e. that are plausible ordering variables. Clearly, that’s obs_id in the BMJ dataset.
Let us first collapse all continuous variables of a row into a string forming a fingerprint. Then we compute pairwise correlations (or Euclidean distances in this case) of all fingerprints. If a dataset contains many identical or near-identical rows, we will see a multimodal distribution of correlations plus an additional big spike at 1.0 for duplicated rows. This is exactly what happens here.
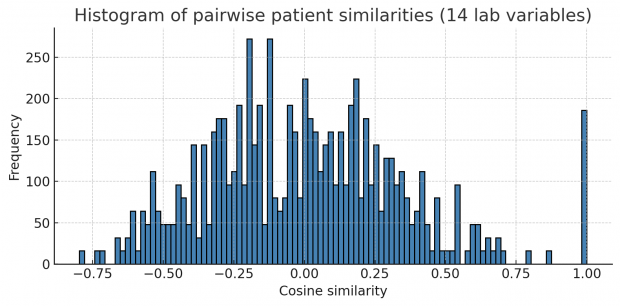
Unfortunately this works only when mainly repetitive variables are included and not too many non repetitive variables.
Next, I thought of Principal Component Analysis (PCA) as the identical blocks may create linear dependencies and the covariance matrix is becoming rank-deficient. But unfortunately results here were not very impressive – so we better stick with the cosine similarity above.
So rest assured we find an excess of identical values, but how to proceed? Duplicates spaced by a fixed lag will cause an high lag k autocorrelation in each variable. Scanning k=1...N/2 reveals spikes at the duplication lag as shown by a periodogram of row-wise similarity in the BMJ dataset.
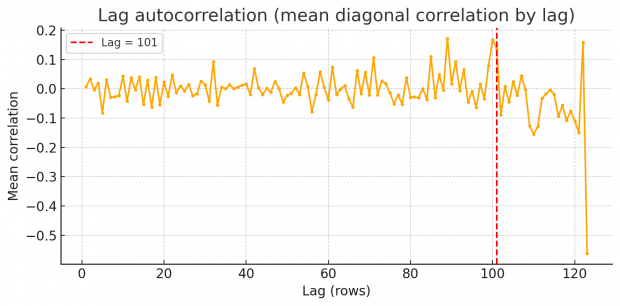
So there are peaks at around 87, 101 and 122. Unfortunately I am not an expert in time series or signal processing analysis. Can somebody else jump in here and provide some help with FFT?
There may be even an easier method, using the fingerprint-gap . For every fingerprint that occurs more than once, we sort those rows by obs_id and compute the differences of obs_id between consecutive matches. Well, this shows just one dominant gap at 101 only!
We could test also all relevant mod values, lets say between 50 and 150. For each candidate we compute the across-group variance of the standardized lab-means. The result is interesting
Modulus 52: variance = 0.084019 Modulus 87: variance = 0.138662 Modulus 101: variance = 0.789720
As a cross check let us look into white blood cell counts (WBC) and hemoglobin (Hb).
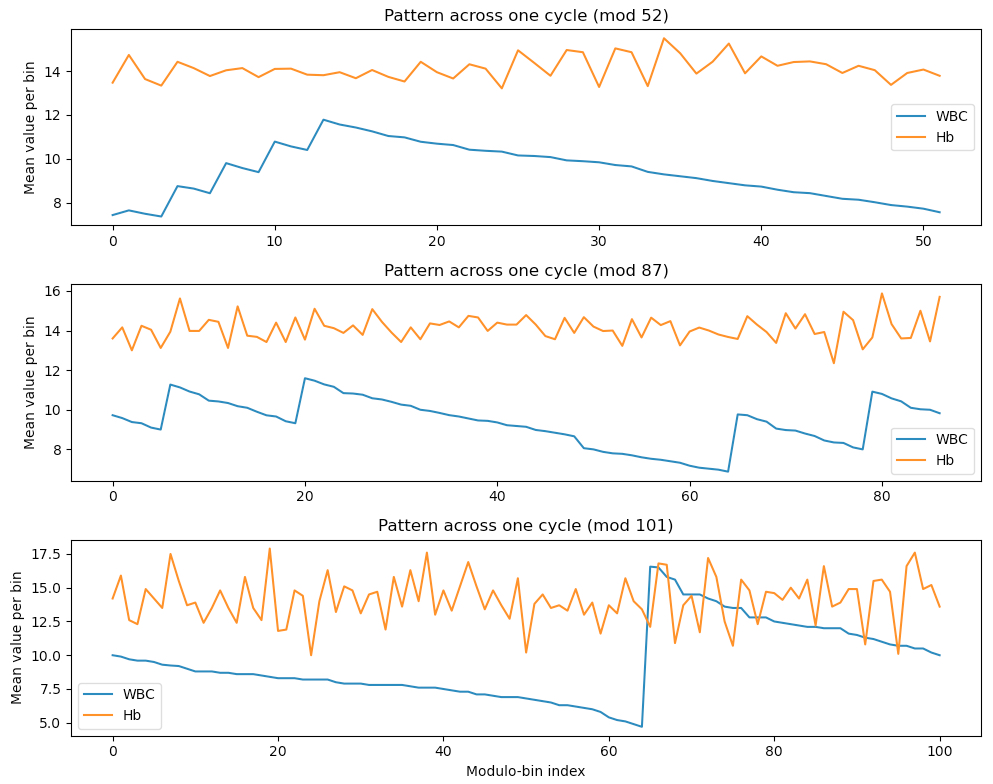
I am not sure, how to interpret this. Mod 52 may reflect shorter template fragments but did not show up in the autocorrelation test. Mod 87 has rather smooth, coherent curve and is supported by autocorrelation. Mod 101 is more noisy, but gives probably the best explanation for block copying values. Maybe the authors block copied at two occasions?
On the next day, I thought of a strategy to find the exact repetition numbers. Why not looping over mod 50 through 150 and just count the number of identical blocks? This is very informative – blocks of size 2, size 3 and 4 or greater show an exact maximum at modulus 101.
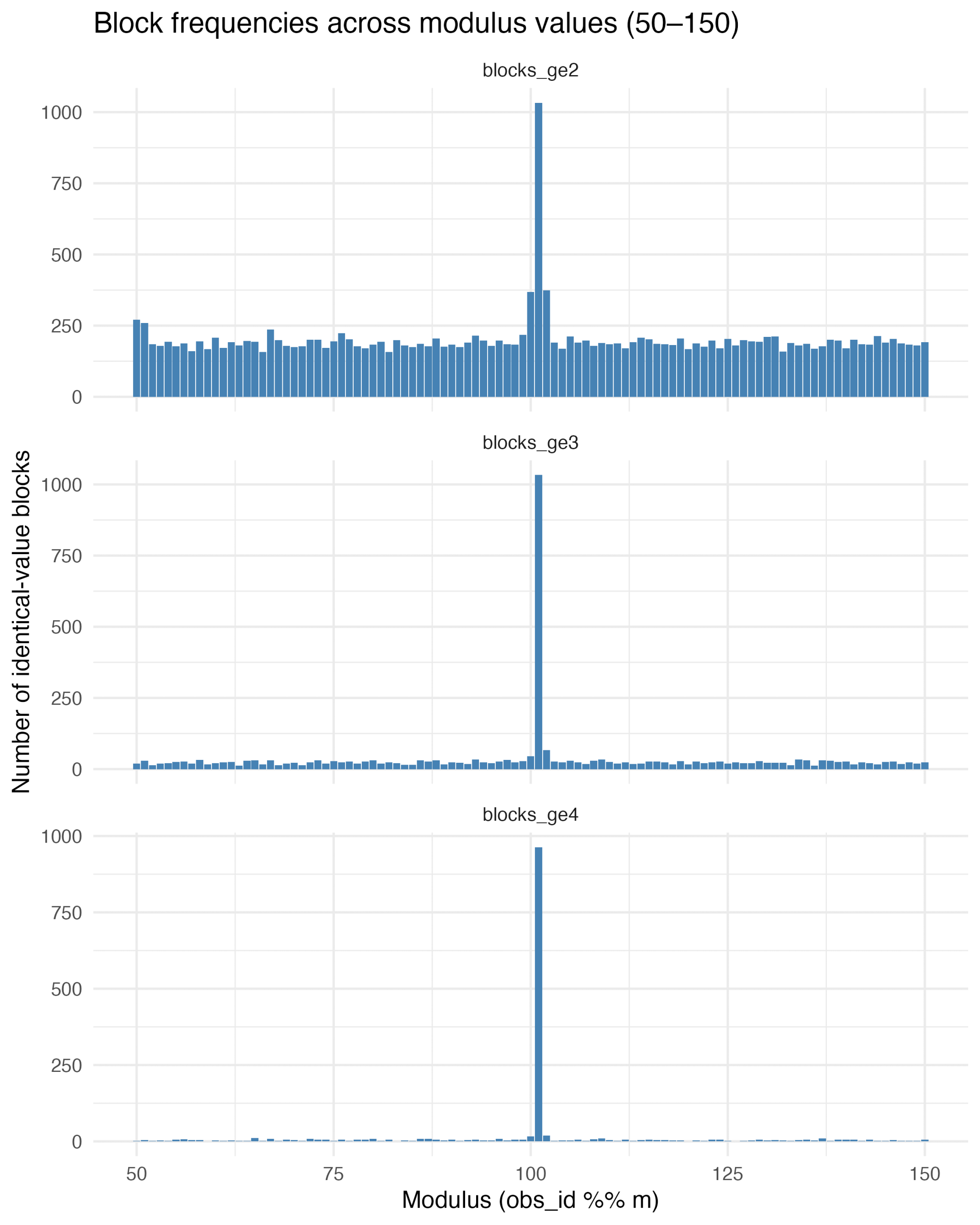
23.3.2026 Appendix
There seems many more studies out there with copy-pastein signs including a Parkinson Cell paper, a PLoS Genetics toxicology paper and a Nat Comm fish ecology study. Here is the Github link to the implementation by Markus Eglund
Hopefully I get the pipeline right by summarizing the entropy calculation there. This is not Shannon entropy – it is a custom measure of how informationally surprising a raw number is. The logic is:
0.314 → 314, 0.500 → 5 (trailing zeros stripped), 2016 → 16 (year exception: years 1900-2030 get a capped entropy of 100).log10(value); values up to 100,000 get 5×log10 - 8; larger values get log10 + 12.logNumberCountModifier (log of the total number of numeric cells on the sheet) so large sheets don’t get disproportionately penalised.The suspicion grades are fixed thresholds on the resulting normalized score. I will add the strategy to my Python script (it is implemented here in type script) as another module and upload to Github once it has been sufficiently tested.
31.3.2026 Appendix
PREVENT-TAHA8, the starting point of this analysis, has been retracted today. I will give a presentation on the avalanche, that has been triggered by this paper, on 29-31 July 2026 in Hannover.
I have written before about the myth of an allergy protection here in Bavaria while we now have an empirical proof – it is a non causal association introduced by colliding.
Unfortunately millions of tax payer money have been wasted on that idea, misleading newspaper articles published and fancy prices given.
I have no idea where the obsession with dung hills originates (early childhood trauma?) and why this had been prized many times.

Jachenau was one of my favorite locations in the 1989/1990 Upper Bavarian Allergy Study where we (re)discovered the low allergy prevalence in farmers that had been forgotten for a century.

We had been in Jachenau on April 30, 1990. Examining 20 kids we found zero asthma, zero allergic rhinitis and just 2 out of 20 children showed borderline positive grass skin prick tests at 3 mm and 4 mm wheal size respectively. This was definitely one of the lowest prevalences but not only in the children, also in their parents and is being confirmed now 3 decades later by meta-analysis of many more farming studies.
Zu dem SZ-Gastbeitrag "Die Bedrohung der Wissenschaftsfreiheit gefährdet die Demokratie" (Nassehi & Tschöp 2025), hier eine Kritik in zehn Punkten.
Vermischung normativer und analytischer Argumente
Der Text springt zwischen moralischer Empörung ("Angriff auf die Wissenschaftsfreiheit") und theoretischer Begründung (Bezug auf Weber, Jaspers) hin und her. Dadurch bleibt unklar, ob die Autoren nun eine soziologische Analyse liefern oder eine politische Stellungnahme formulieren wollen. Dieser Zickzack Kurs schwächt die argumentative Klarheit. Eine klare Trennung der analytischen Ebene "Welche gesellschaftlichen Mechanismen bedrohen Wissenschaftsfreiheit?" und des normativen Teils: "Warum sie für Demokratie unverzichtbar ist?" mit Beleg durch empirische Beispiele oder Forschung wäre überzeugender gewesen.
Zirkularität der Hauptthese
Die Kernbehauptung lautet sinngemäß daß "Wissenschaft nur in Freiheit gedeihen kann und Freiheit gibt es nicht ohne Wissenschaft." Das ist logisch zirkulär, denn es wird nicht gezeigt, warum denn Freiheit nun zwingend von Wissenschaft abhängt. Die Behauptung steht tautologisch im Raum, ohne empirische oder historische Belege. Überzeugend wäre gewesen, warum Freiheit für Wissenschaft nötig ist (methodische Offenheit, Peer Review, Kritikfähigkeit, Weiterentwicklung). Und dann liesse sich auch unschwer empirisch zeigen, daß wissenschaftliche Rationalität demokratische Verfahren stärken kann (z. B. evidenzbasierte Politik, deliberative Öffentlichkeit) und eine gegenseitige Abhängigkeit entsteht. Alles andere ist die aufgeblähte Rhetorik einer Proseminar Arbeit.
Übertragungsfehler auf allgemeine Demokratietheorie
Die Erregung mag ja nun verständlich sein an der grössten deutschen Universität. Der Artikel stützt sich auf die US-Politik unter Trump/Kennedy, zieht daraus aber weitreichende Schlüsse über Demokratien im Allgemeinen. Der Übergang von einem spezifischen und zugegeben unangenehmen Fall zu einer universellen Diagnose ("auch hierzulande droht Gefahr") bleibt unbegründet. Besser wäre ein komparativer Vergleich gewesen statt der praktizierten Erregungskultur: Beispiele aus Polen, Ungarn, Brasilien, Türkei zeigen das Muster von politischer Instrumentalisierung zu Einschränkung der Autonomie über den Vertrauensverlust bis hin zur “Demolierung der Demokratie”.
Idealisiertes Wissenschaftsbild
Die Autoren zeichnen ein idealisiertes, fast schon sakrales Bild von Wissenschaft ("Fakten bleiben bestehen, auch wenn alles Wissen vernichtet wird"). Damit werden methodische und institutionelle Fehlbarkeit weitgehend ausgeblendet - z. B. Machtstrukturen, Gender Bias, Publikationszwänge, Reproduzierbarkeitskrise. Der Text reflektiert zwar kurz "Selbstkritik", aber nur oberflächlich und mehr pflichtschuldig. Wissenschaft sollte realistischer als soziales System mit Fehlanreizen, Macht, Hierarchie und Interessen beschrieben werden. Gerade weil Wissenschaft fehleranfällig ist, braucht sie Freiheit zur Korrektur.
Mangelnde Differenzierung von "Freiheit"
"Wissenschaftsfreiheit" wird als absoluter Wert dargestellt, ohne zwischen äußerer Freiheit (also vor politischer Zensur) und innerer Freiheit (etwa durch ökonomische, institutionelle oder soziale Zwänge) zu unterscheiden. Die Autoren erwähnen zwar die "Schere im Kopf", analysieren diese aber nicht weiter - das Argument bleibt im luftleeren Raum stehen.
Appell statt Argumentation
Große Teile des Textes bestehen aus Appell- und Bekenntnisrhetorik ("Wir haben viel zu verlieren"). Es werden kaum Belege, empirische Beispiele oder Gegenargumente präsentiert. So ist der Beitrag dann doch eher Plädoyer mit Pathos im Schlussabschnitt – um Wirkung zu entfalten, aber nicht um rational zu überzeugen.
Widerspruch zwischen Selbstkritik und Autoritätsanspruch
Am Schluss fordern die Autoren zwar "mehr Selbstkritik" und "wissenschaftliche Klärung" ein, ohne aber ihre eigenen normativen Prämissen zu hinterfragen. Das schwächt den Anspruch *wissenschaftlich* über Wissenschaft zu sprechen. Es ist eine verpasste Chance, explizit die eigenen institutionellen Rolle reflektieren, wie sie an der Spitze des Wissenschaftsbetriebs profitieren von Macht und Geld und Strukturen, die Kritik erschweren.
Fehlende Auseinandersetzung mit legitimer Wissenschaftskritik
Un nicht zuletzt: Die "Elitenkritik" wird erwähnt, doch die Autoren behandeln sie vor allem als Gefahr, nicht als möglicherweise berechtigte gesellschaftliche Rückmeldung. Dadurch wirkt der Text selbst elitär - ein blinder Fleck im Hinblick auf das von ihnen geforderte "Vertrauen in Wissenschaft". Vertrauen sollte nicht nur gefordert, sondern muss verdient werden.
Wissenschaftliche Unredlichkeit wird ignoriert
Übersehen wird dabei die eigentliche Vulnerabilität der Wissenschaft - die Faulgase im Inneren des Systems: erfundene Daten und gefälschte Grafiken, Plagiate und mehrfach verwertete Daten, Zitierkartelle, Paper Mills und nicht zuletzt hochgradig selektive Darstellungen als Ursache der Replikationskrise. All das unterwandert die Idee wissenschaftlicher Redlichkeit von innen heraus und bedrohen ihre Glaubwürdigkeit weit stärker als der gesellschaftliche Erwartungsdruck, vor dem die Autoren warnt.
Finis
Der Text stammt offensichtlich von Nassehi; von Tschöp sind bisher nur Versuchsbeschreibungen von übergewichtigen Mäusen überliefert. Frühere Nassehi Rezensionen haben angemerkt, dass er zuweilen in einer stark theoretischen und abstrakten Weise argumentiert - etwa in seinen Überlegungen zur digitalen Gesellschaft, wo weitreichende Thesen formuliert werden, ohne auf eine solide empirische Fundierung zurückzugreifen. Charakteristisch ist sein wiederholter Appell an ein gesteigertes Bewusstsein für Komplexität, Ambiguität und Perspektivendifferenz, verbunden mit einer Skepsis gegenüber "großen Gesten". Paradoxerweise verfällt er jedoch in diesem Text selbst in eben jene rhetorische Haltung, vor der er sonst gerne warnt.
(verfasst mit chatGPT 5 Support)
Postscriptum
Und was ist eine der ersten Amtshandlungen des neuen Präsidenten, nur zwei Wochen nach der Inauguration? Nach Kritik aus der CDU und einer Interessengruppe an einer geplanten Veranstaltung kommt nun diese Pressemitteilung heraus “LMU als Ort des pluralistischen Diskurses”
Zu dem an der LMU geplanten Seminar "The Targeting of the Palestinian Academia" hat die Hochschulleitung sich mit dem Veranstalter Professor Andreas Kaplony, Lehrstuhl für Arabistik und Islamwissenschaft, ausgetauscht. Hierbei wurden sowohl der wissenschaftliche Charakter der Veranstaltung als auch Sicherheitsbedenken erörtert. Daraus resultierte folgende einvernehmliche Vorgehensweise:
- Die für den 28.11.2025 terminierte Veranstaltung findet nicht statt.
- Zeitnah werden Professor Kaplony, Mitglieder der Hochschulleitung und der Fakultät für Kulturwissenschaften damit beginnen, geeignete wissenschaftliche Formate auch für derart aufgeladene Themen zu entwickeln.
- Ein solches Format soll in absehbarer Zeit umgesetzt werden.
Die LMU hat sich die Entscheidung nicht leicht gemacht und die relevanten wissenschaftlichen und rechtlichen Aspekte abgewogen. Die Freiheit der Wissenschaft ist ein hohes Gut, es bestanden in diesem Fall aber Zweifel, ob es sich um eine wissenschaftliche Veranstaltung auf dem erforderlichen Niveau gehandelt hätte. Die LMU trägt dabei ihrem Anspruch Rechnung, die Freiheit der Wissenschaft, die freie Rede, die sachliche Austragung von Konflikten, sowie Respekt gegenüber unterschiedlichen Auffassungen zu leben.
Was auch immer auf dieser universitären Veranstaltung hätte diskutiert werden sollen, ob hier womöglich zu Rechtsbruch aufgerufen worden wäre, das kann ich alles nicht sagen. Aber wir können festhalten, daß die Pressemitteilung behauptet, die LMU sei ein "Ort des pluralistischen Diskurses", aber gleichzeitig eine geplante Diskussion absagt. Sie betont die "Freiheit der Wissenschaft", knüpft diese jedoch an eine interne Bewertung des "wissenschaftlichen Niveaus" - und schränkt damit gerade jene Freiheit ein, die vor wenigen Monaten noch so hoch gehalten wurde.
Die jüngsten Attacken der US-Regierung gegen die Universitäten sind nicht weniger als ein Angriff auf die Wissenschaftsfreiheit. Das ist eine ernst zu nehmende Gefahr. Denn Wissenschaft kann nur in Freiheit gedeihen.
Anstatt Debatten zu ermöglichen, wird der Diskurs verschoben und durch unbestimmte, zukünftige Formate ersetzt. Sicherheits- und Qualitätsargumente dienen dabei als Vorwand, kontroverse Inhalte nicht zuzulassen. So hat die Pressemitteilung das fatale Ergebnis, dass sie Offenheit verspricht aber faktisch Wissenschaftsfreiheit unterläuft.

Mai Thi Nguyen-Kim – laut dem Kommunikationsdienst der Medienbranche Turi2 Deutschlands bekannteste Wissenschaftsjournalistin – brachte in der Vergangenheit immer wieder spannende Videos. Allerdings hat sie sich bei dem Thema Genetik überhoben und ist offensichtlich auch nicht gut in der Wissenschaftsszene vernetzt. Anders sind ihre Aussagen zur Genetik jedenfalls nicht zu erklären.
Ihr Zweifel an dem Rassenbegriff ist ja völlig berechtigt, denn nur Rassisten reden von Rassen. Wir reden schon lange nicht mehr von Rassen bei Menschen, sondern von Populationen, Volksgruppen, Ethnien oder was auch immer (Rassen sind ansonsten die gezielt gezüchtete Tier- oder Pflanzenarten, die sich durch Selektion auf bestimmte Eigenschaften vermehrt haben). Wir reden deshalb nicht mehr davon, weil die Anfang des letzten Jahrhunderts von Anthropologen beschriebenen äusseren Merkmale von Menschen eben nicht mit den Ergebnissen der modernen Genetik überein stimmen. Aber statt dann wenigstens bei dem Thema Populationsgenetik in ihrem Video zu bleiben, zieht sie auch noch eine direkte Linie zum Kolonialismus. Und stellt dann auch noch eine Verbindung zur Kriminalstatistik her. Das ist unseriös und nur der Aufmerksamkeitsökonomie geschuldet.. Continue reading Die unangenehme Wahrheit des Mai Thi Videos
There are several interesting papers on this topic during the last few weeks. The most interesting one was “How universities came to be – and why they're in trouble now” by Philip G. Altbach. Higher education worldwide is under strain, facing deep financial and political challenges. In the U.S., universities are dealing with major federal funding cuts and political pressure on teaching and research. In the U.K. money troubles are pushing some institutions toward collapse. Global enrolment has exploded from 6 million in 1950 to 264 million in 2023, and by 2024 most countries-except in sub-Saharan Africa-were sending over half of school-leavers to higher education. So we don’t have anymore an elite university but education for the masses.
As higher education became accessible to the masses across the world, research-intensive universities based on the original Humboldtian model have come to represent just a small proportion of all higher education institutions.[…] the rise of populist politics has compounded some of these pressures. Populism has many causes -Rejection of experts, science and evidence-based policy is part of many populist movements.
Therefore we have now less highly qualified scientists at universities who will even move to the private sector. Clara Collier at her blog analyses the historical development.
… something happened to German universities at the turn of the 19th century - they developed a new system that combined teaching with research. Within a few decades, everyone in Europe was trying to copy their model. German scientists dominated chemistry and revolutionized modern physics. They came up with cell theory, bacteriology, the whole laboratory-based model of scientific medicine
The historical origins illuminate why modern universities may be in trouble: if the delicate balance between funding, mission, autonomy, teaching, and research shifts too far, the institution risks losing its raison d'être. All the financial and structural pressures that force now institutions to prioritise revenue, prestige, cost-cutting and global competition rather than education. In addition we have a legitimacy crisis, where universities are no longer seen as the unique centres of knowledge creation and public good – they compete instead with other knowledge platforms and feel more like businesses.
While the above analysis suggested that universities will decline when they lose their grounding in mission, and unity of purpose, a NYT article two months ago suggested that decline already happens by finances and market pressures that force institutions to compromise on programmes, services, and expectations undermining their offer to students that doesn't stress anymore "ideas" as much as "money & market".
– Rising administrative and support costs, which have soared in recent decades, even as state legislatures have tightened public spigots.– Higher tuition prices, among other considerations, which have turned off students, who are routinely paying more and oftentimes getting less.– Some academic programs that draw few students.
In the same vein is another Atlantic article on the disruption of the federal research-funding ecosystem (especially via the NIH) which ties into the broader theme of financial/mission distress.
Now many university professors and researchers believe that this special fusion of research and teaching is at risk. "I feel lost," a research scientist at a top-five university who works on climate and data science told me.
It complements the notion that universities are vulnerable not only to enrolment/tuition pressures and mission drift, but also to external shocks in the research funding system. Many research universities have built major commitments around securing federal research grants and the indirect cost ("overhead") payments from them. The Atlantic piece argues that when those are threatened, the whole institution becomes fragile.
That ties back to the origin-story of the modern research university (the teaching + research model) - if the "research" side now collapses, the model itself is under threat. This injects more urgency: it's not only decades of mission drift and funding pressure, but also sudden regulatory/policy upheavals.

In my career I have experienced all kind of situations where reason often loses not to better logic but to tactics.