Unfortunately with the decline of genomic research, there are some “hobbyist” researchers coming up with their own agenda. Three recent investigations lay out just how bad things have gotten – and how difficult it is to stop the damage once it starts.
The New York Times revealed that fringe researchers systematically deceived the NIH to gain access to genetic and brain-scan data from over 20,000 American children enrolled in the Adolescent Brain Cognitive Development Study. Using deliberately misleading applications, they extracted the data, shared it with unauthorized collaborators, and produced at least 16 papers purporting to rank racial groups by IQ. The papers have since been amplified millions of times on social media, cited by AI chatbots, and used as ammunition by white nationalists. The NIH eventually suspended the lead researcher and he was fired – yet his collaborators apparently retained copies of the data and kept publishing.
The Guardian then showed the problem is not limited to bad-faith actors inside the system. UK Biobank, which holds health records on 500,000 British volunteers, found that well-meaning researchers had accidentally posted sensitive datasets to GitHub dozens of times. One exposed file contained hospital diagnoses and birth details for 413,000 participants – enough to re-identify individuals with just a date of birth and one known medical procedure.
Harvard geneticist Sasha Gusev ties both stories together in a sharp Substack essay. His core point is simple: these systems were designed assuming everyone plays by the rules. They were not built for people who lie on their access applications, quietly pass data to friends, or treat a children’s health study as raw material for race propaganda. When something goes wrong, the response tends to be more paperwork, more committees, more strongly worded statements — none of which does much against someone who was never going to read them anyway. Gusev’s actual prescription: stick to what participants consented to, ban anyone who leaks data permanently, and when bad science appears, criticize it loudly in plain language where people can actually read it – not in a journal response that ten specialists will see.
The people who donated their data, often hoping to help find cures for cancer or diabetes, deserve at least that much.
Sowohl das Deutsche Ärzteblatt als auch die Münchner Medizinische Wochenschrift veröffentlichten nun in kurzer Folge methodisch fragwürdige Beiträge zur Vitamin-D-Forschung. Und da sie eine enorme Reichweite in der ärztlichen Fortbildung haben, landet der Vitamin-D-Hype direkt in der Praxis – Überdiagnostik, unnötige Supplementierung, wir kennen das Problem nun viele Jahre. Von einer Erwiderung habe ich dennoch abgesehen, solange dem Erstautor der Schlusskommentar vorbehalten bleibt.
Fall 1
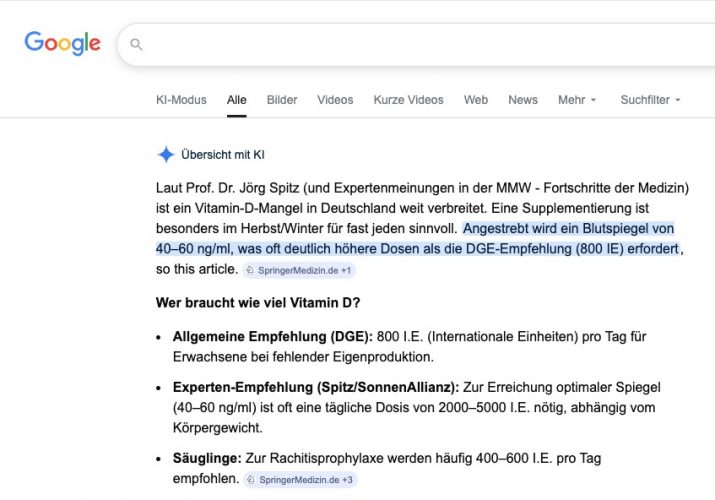
Die MMW druckt eine Fortbildung / CME-Beitrag „Wer braucht wann wie viel Vitamin D?“ eines lange pensionierten Dr. med. (MMW Fortschr Med. 2025; 167 (S3): 76–82). Leider übernimmt die KI den Unsinn auch noch als Expertenmeinung…
Screenshot Google 26.3.2026
Mein Kommentar zu dem Artikel war
1. Interessenkonflikt
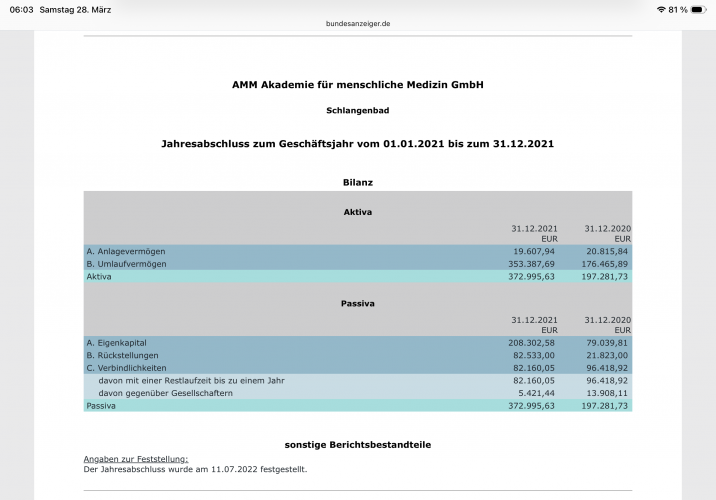
Der Autor gibt „keine Interessenkonflikte“ an, betreibt jedoch die Akademie für menschliche Medizin GmbH, die kommerziell Vitamin-D-bezogene Präventionsangebote vertreibt. Diese Verbindung ist gemäß DFG- und ICMJE-Regeln deklarationspflichtig. Medwatch schreibt von 225.000€ Umsatz im Jahr 2019.
2. Epidemiologische Angaben
Die Behauptung, „90 % der Bevölkerung“ hätten < 30 ng/ml Vitamin D, stützt sich auf veraltete RKI-Daten (2007–2011). Neuere Erhebungen (DEGS II, 2019) zeigen nur 30–40 % unter 50 nmol/l. → Übertriebene Darstellung eines Mangels.
3. Dosierungsempfehlung
Empfohlene 4 000–6 000 IE/Tag überschreiten den international anerkannten Upper Level von 4 000 IE/Tag (EFSA 2023). Für gesunde Erwachsene fehlt jede Evidenz.
4. Toxizität und „Coimbra-Protokoll“
Die Aussage, Werte bis 150 ng/ml seien unbedenklich, widerspricht Daten zu Hyperkalzämie und Nephrokalzinose. Das „Coimbra-Protokoll“ (≥ 100 000 IE/Tag) ist nicht evidenzbasiert und medizinisch riskant.
5. Extra-skelettale Effekte
Im Artikel werden präventive Wirkungen (Demenz, KHK, Krebs, Blutdruck, Diabetes u. a.) behauptet, obwohl große RCTs (VITAL, D2d, ViDA) keinen Nutzen zeigten. Die Darstellung ist selektiv und irreführend.
6. Schwangerschaft
Die genannte 60 %ige Reduktion von Frühgeburten entstammt keiner belastbaren Quelle; die zitierte Pilotstudie (Wagner et al. 2006) weist diese Endpunkte nicht auf.
7. COVID-19-Bezug
Die angeblich 16-fache Mortalitätssteigerung bei Vitamin-D-Mangel beruht auf einem Meinungsartikel, nicht auf einer Originalstudie. Die Darstellung ist faktisch falsch.
8. Fehlende Neutralität im CME-Kontext
Der Beitrag enthält werblich anmutende Aussagen, selektive Quellenwahl (u. a. Masterarbeit Göthel 2020) und unkritische Übernahme von Hypothesen. Damit ist die formale Neutralitätsanforderung der CME-Zertifizierung (§ 4 CME-Richtlinie BÄK) nicht erfüllt.
Der Chefredakteur Cornelius Heyer nimmt auf meine Reklamation zumindest die CME Akkreditierung heraus, aber statt einer Korrektur oder Löschung des Beitrages, druckt die MMW einen Leserbrief nach dem der Dr. med. das letzte Wort in der Diskussion hat.
Screenshot 26.3.2026 Nota bene – Spitz hat nie wissenschaftlich zu dem Thema gearbeitetPassiva der Akademie für menschliche Medizin 2021
Ein Tageszeitungsleser ist damit nun also besser informiert als ein/e Arzt/Ärztin der die MMW abonniert hat.
Fall 2
Das Deutsche Ärzteblatt druckt ein Review eines Kongressabstracts “Personalisierte Vitamin D Supplementierung kann das Re-Infarktrisiko halbieren”. Wer nec ist weiss ich nicht, allerdings weiss ich genau, dass es wieder Märchen sind die nec hier erzählt. Der Leiter der Medizinisch-Wissenschaftlichen Redaktion des DÄ Christopher Baethge verweist mich an die journalistische Redaktion in Berlin Michael Schmedt, der allerdings auch nach Wochen immer noch nicht geantwortet hat.
New Orleans – Eine Supplementierung mit Vitamin D in individuell titrierter Dosierung kann das Risiko für einen erneuten Herzinfarkt bei vorerkrankten Personen um mehr als die Hälfte reduzieren. Das berichteten Forschende bei den Scientific Sessions 2025 der American Heart Association in New Orleans (Abstract Nr. 4382525).
[…]
Warum ist das so?
Die TARGET-D-Studie wird als Korrektur früherer negativer Vitamin-D-Studien präsentiert, mit der Behauptung, diese seien gescheitert, weil sie Vitamin D nicht „zielgerichtet“ titriert hätten. Bei genauer Betrachtung reproduziert TARGET-D jedoch genau jene strukturellen Schwächen, die die Vitamin-D-Outcome-Literatur seit Jahren geplagt haben.
Der entscheidende Befund ist eindeutig: Der vordefinierte primäre Endpunkt, schwere kardiovaskuläre Ereignisse (MACE), wurde in der Intention-to-treat-Analyse nicht signifikant reduziert. Nach elementaren CONSORT-Prinzipien müsste dieses Ergebnis die Interpretation bestimmen. Stattdessen verlagert die Studie den Fokus sofort auf ein einzelnes positives Signal in einer Unterkomponente des kombinierten Endpunkts, den Folge-Myokardinfarkt. Diese Verschiebung rettet die Studie nicht, sondern verschleiert ihr negatives Hauptergebnis. Wenn ein kombinierter Endpunkt scheitert, stellt die selektive Hervorhebung einer einzelnen Komponente keine Evidenz dar, sondern narrative Verzerrung.
Die anschließende Betonung von Per-Protocol-Analysen untergräbt die Aussagekraft weiter. Diese Analysen vergleichen nicht mehr randomisierte Gruppen, sondern Untergruppen, die nachträglich anhand des Erreichens eines willkürlich gewählten Vitamin-D-Schwellenwertes definiert werden. Damit wird nicht mehr die Wirkung einer Intervention geprüft, sondern der Gesundheitszustand einer selektierten, therapietreuen, Responder Population dem einer Restgruppe gegenübergestellt, die überproportional Nicht-Responder, Gebrechliche und Patienten mit höherer Krankheitslast enthält. Der Vitamin-D-Spiegel fungiert hier als Marker guter Gesundheit und Compliance, nicht als kausaler Faktor. Genau dieser Denkfehler hat frühere Beobachtungsstudien diskreditiert, was auch in allen Umbrella Reviews klar herauskam, aber hier innerhalb eines randomisierten Designs erneut eingeführt wird.
Das Ausmaß der postrandomisierenden Selektion macht dieses Problem unübersehbar. Ein erheblicher Teil der dem Vitamin-D-Arm zugewiesenen Patienten wird aus der Per-Protocol-Analyse ausgeschlossen, weil der Zielwert nie erreicht wurde oder nur unvollständige Nachbeobachtung vorlag. Die Konditionierung auf einen postrandomisierten Biomarker zerstört die durch Randomisierung erreichte Vergleichbarkeit der Gruppen. Die daraus resultierenden Effekte sind selektionsgetrieben und nicht kausal interpretierbar.
Auch die biologische Grundannahme der Studie ist schwach fundiert. Der gewählte Zielwert von über 40 ng/ml für 25-Hydroxyvitamin D ist nicht leitlinienbasiert, entspricht nicht der neuesten Literaturund impliziert einen Schwellen- oder Dosis-Wirkungs-Effekt, der in großen randomisierten Studien und genetischen Analysen nicht bestätigt wurde. Indem der Studienerfolg über das Erreichen dieses Zielwerts definiert wird, wird der behauptete Nutzen nicht getestet, sondern implizit vorausgesetzt.
Die Darstellung der Ergebnisse verstärkt diesen Eindruck. Formulierungen wie „klinisch relevante Risikoreduktionen“ oder „Reduktion des Myokardinfarktrisikos um mehr als die Hälfte“ suggerieren einen kausalen Effekt, den das Studiendesign und die Resultate nicht tragen. Andere Komponenten des kombinierten Endpunkts zeigen keine konsistente Verbesserung, werden jedoch deutlich weniger betont. Der Gesamteindruck ist nicht der einer neutralen Prüfung einer Hypothese, sondern der Versuch, aus einer im Kern negativen Studie ein positives Narrativ zu extrahieren.
Insgesamt liefert TARGET-D keinen belastbaren Beleg dafür, dass eine Vitamin-D-Normalisierung das kardiovaskuläre Risiko nach akutem Koronarsyndrom senkt. Der primäre Endpunkt ist negativ, die sekundären Aussagen beruhen auf selektiver Gewichtung, und die Per-Protocol-Analysen ersetzen Randomisierung durch Adhärenz- und Selektionsmechanismen. Die Studie bestätigt letztlich nur, was die Literatur seit Langem zeigt: Niedrige Vitamin-D-Spiegel korrelieren mit schlechter Gesundheit, ihre Korrektur verändert jedoch harte kardiovaskuläre Endpunkte nicht zuverlässig. Neu an TARGET-D ist nicht die Überwindung dieser Limitationen, sondern ihre methodisch aufwendigere und potenziell irreführende Verpackung.
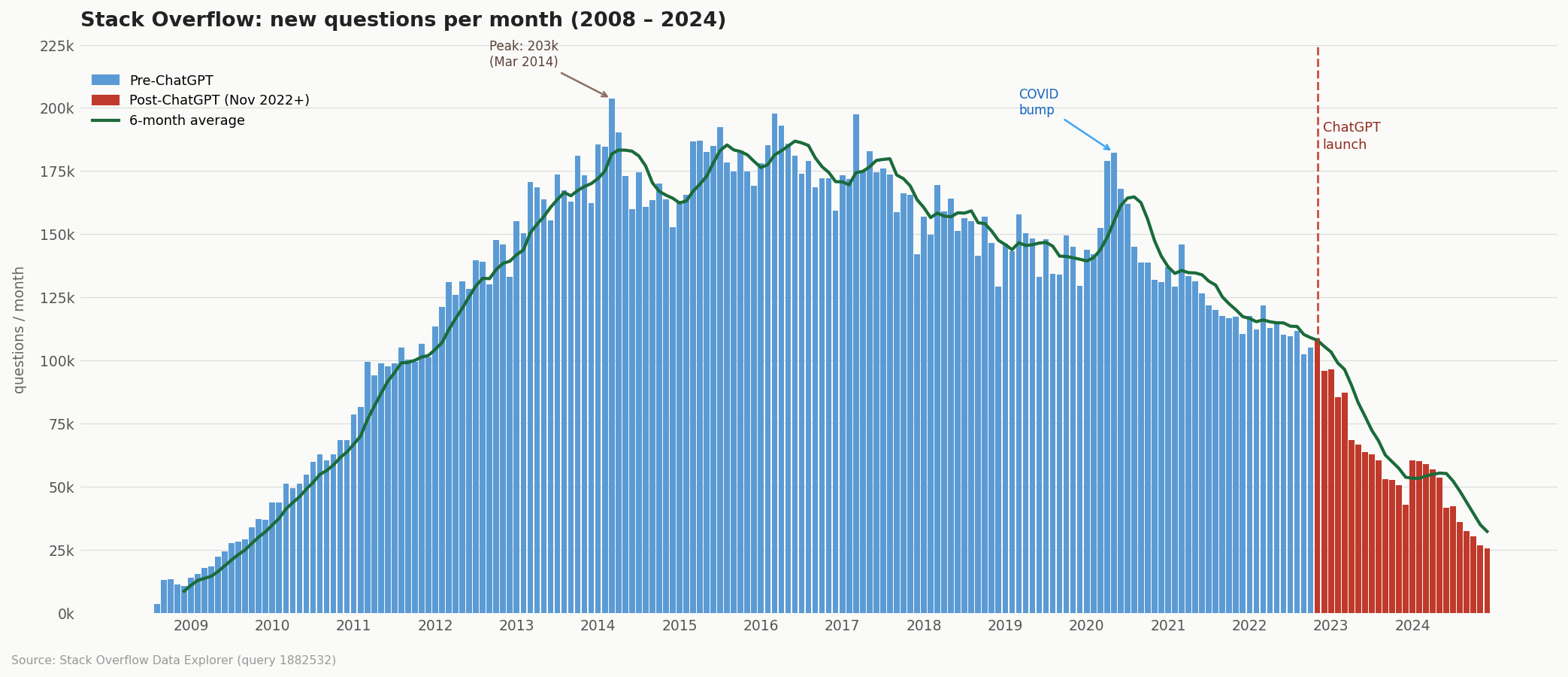
Coding with AI has a nice chart, that I am redrawing here
data source https://data.stackexchange.com/stackoverflow/query/1882532/questions-per-month
so it is time to say Good-Bye now after 14 years
Screenshot 23/3/26 Last Visit to SO
and sticking to the new 10 commandments by Russell Poldrack
Gather Domain Knowledge Before Implementation
Distinguish Problem Framing from Coding
Choose Appropriate AI Interaction Models
Start by Thinking Through a Potential Solution
Manage Context Strategically
Implement Test-Driven Development with AI
Leverage AI for Test Planning and Refinement
Monitor Progress and Know When to Restart
Critically Review Generated Code
Refine Code Incrementally with Focused Objectives
Was die Regeln ursprünglich sollten? Nach 9/11 und der Finanzkrise 2008 wurden die Compliance Regeln für Banküberweisungen massiv verschärft. Das Ziel war natürlich legitim: Terrorfinanzierung, Drogenhandel, Menschenhandel und Steuerflucht eindämmen. Die FATF (Financial Action Task Force) setzte globale Standards und die setzten die Banken unter enormen Compliance-Druck stellten.
Aber es wurde übertrieben und das Problem ist mittlerweile gut dokumentiert. Ich habe es selbst in Ostafrika nun erlebt. De-Risking trifft die Falschen. Nicht Kriminelle, sondern Entwicklungsländer, Diaspora-Überweisungen, NGOs und kleine Importeure werden abgeschnitten. Die Weltbank und der IWF haben das mehrfach kritisiert – gerade Überweisungen von Migranten in die Heimat (sog. “Remittances”) sind für viele Länder wirtschaftlich wichtiger als Entwicklungshilfe. Die Weltbank warnte explizit: Wenn der Trend anhält, könnten Menschen und Organisationen in volatileren Regionen vollständig vom regulierten Finanzsystem abgeschnitten werden – was paradoxerweise die Transparenz senkt, weil Transaktionen in unregulierte Kanäle abwandern.
Dazu sind die Compliance-Kosten sind explodiert. Banken geben laut Schätzungen weltweit über 200 Milliarden Dollar jährlich für Compliance aus – und trotzdem werden laut UNODC nur 1-2% krimineller Geldflüsse tatsächlich gestoppt. Der Aufwand ist also enorm, der Effekt gering. “Greylist”-Stigma trifft ganze Volkswirtschaften. Wird ein Land auf eine Grau- oder Schwarzliste gesetzt, ziehen sich Banken kollektiv zurück – nicht weil einzelne Transaktionen gefährlich sind, sondern aus Angst vor Haftung. False Positives sind derNormalzustand. >90% der Alerts sind Fehlalarme, es ist kein Randphänomen, sondern ein systemisches Problem.
Korruption und illegale Kapitalflucht aus Entwicklungsländern sind real – und schaden oft genau den Empfängerländern. Die EU-Geldwäscherichtlinien haben nachweislich einige große Skandale aufgedeckt. Das Kernproblem ist nicht die Intention, sondern die Architektur: Banken werden für Verstöße mit Milliardenstrafen belegt, aber nie dafür, dass sie legitime Transaktionen blockieren. Der Anreiz ist also systematisch verzerrt – lieber zu viel ablehnen als zu wenig. Solange diese asymmetrische Haftung nicht geändert wird, werden Überweisungen nach Afrika kompliziert bleiben. Oder wir laufen weiter mit Geldbündel durch die Gegend, tricksen mit gemeinsamen Kreditkarten, benützen Remitly oder Hawala – alles das, was Compliance Regeln eigentlich verhindern wollten.
Viele Menschen in Deutschland glauben einer Studie zufolge an vermeintlich naturgegebene Unterschiede zwischen verschiedenen Ethnien und Kulturen. So stimmten zwei von drei Befragten der Aussage zu, dass bestimmte Kulturen “fortschrittlicher und besser” seien als andere, wie aus der Erhebung des Deutschen Zentrums für Integrations- und Migrationsforschung (DeZIM) hervorgeht. Knapp die Hälfte vertrat die Ansicht, dass gewisse Gruppen “von Natur aus fleißiger” seien als andere. 36 Prozent der Befragten stimmten der Aussage zu, dass es unterschiedliche “Rassen” gäbe.
Um eine solche Studie machen zu können, muss man:frau minimale Voraussetzungen in Testtheorie mitbringen. Basale Kenntnisse der Kulturwissenschaft, Genetik, Medizin oder Pädagogik schaden auch nicht. Leider fehlt dies aber den Leitern dieser “Studie” (download hier).
Oversampling ohne transparente Gewichtung. Die Studie überrepräsentiert bestimmte Gruppen absichtlich durch eine Vorklassifikation nach Vor- und Nachnamen aus Melderegistern. Das ist legitim – aber die Gewichtung wurde im aktuellen Bericht erstmals an Mikrozensus-Daten angepasst, was die Autoren selbst einräumen führt dazu, dass frühere Berichte “in einzelnen Zahlen leicht abweichen”. Zeitreihenvergleiche sind damit methodisch fragwürdig.
Selbstauskunft als einzige Datenquelle. Alle Kernvariablen – Einstellungen, Diskriminierungserfahrungen, Institutionenvertrauen – beruhen auf subjektiver Selbstauskunft. Es gibt keine Kreuzvalidierung mit administrativen Daten, Experimenten (Audit-Studien) oder objektiven Indikatoren.
Zirkuläre Operationalisierung von “Rassismus”. Das Instrument misst u.a. die Zustimmung zur Aussage, bestimmte Kulturen seien “fortschrittlicher und besser” als andere (66 % Zustimmung), und wertet dies als rassistische Einstellung. Eine derartig breite Definition schließt faktische Kulturvergleiche, zivilisationstheoretische Positionen und Alltagsurteile pauschal als “Rassismus” ein – das ist eine normative Vorentscheidung, keine empirische.
Konfundierung von Ursache und Wirkung. Der Bericht berichtet Korrelationen zwischen Diskriminierungserfahrungen und Institutionenvertrauen und formuliert daraus kausale Schlüsse (“gehen einher mit”, “führen zu”). Längsschnittdaten wären nötig, um Kausalrichtung zu bestimmen – das Panel ließe das zumindest ansatzweise zu, wird aber hauptsächlich im Querschnitt ausgewertet.
Selektiver Attrition-Bias. Die Gewichtung für Panel-Ausfälle erfolgt anhand von Merkmalen wie Selbstidentifikation und Einstellungen gegenüber verschiedenen Gruppen. Wer aus dem Panel ausscheidet, weil er das Thema Rassismus als irrelevant empfindet, wird weggewichtet – das strukturiert die Ergebnisse in Richtung der Ausgangshypothese.
Institutionelle Interessenlage. Das NaDiRa ist beim Deutschen Zentrum für Integrations- und Migrationsforschung (DeZIM) angesiedelt und wird vom Bundesministerium gefördert. Die Handlungsempfehlungen am Ende des Berichts sind das erklärte politische Ziel. Das ist kein Fehler per se, aber ein Faktor für die Interpretation.
Zusammenfassung. Die Studie ist kein Beleg für die Verbreitung von Rassismus in Deutschland, sondern eine Messung davon, wie viele Menschen bestimmten, normativ vordefinierten Aussagen zustimmen. Die Gleichsetzung von Zustimmungsraten mit “rassistischen Einstellungen” ist die Kernproblematik – sie folgt aus dem theoretischen Rahmen, nicht aus den Daten selbst.
“Garbabge in, Garbage out” – eine solche sensible Fragestellung in einem “online Tool” ohne vorherige ausführliche Validierung zu bearbeiten? Wo es so sehr auf Nuancen im Sprachgebrauch ankommt?
So ist nicht nur die PK sondern auch die Studie auch die Kernaussagen ein Musterbeispiel für politische Agenda aber nicht für eine validierte Aussage. Verständlicherweise kommt daher vielfache Kritik- Auszüge:
https://profile.zeit.de/2784058 … nicht jede Kultur ist gleich gut. Eine Kultur, in der es bspw. als normal gilt, dass junge Mädchen genitalverstümmelt, zwangsverheiratet und systematisch entrechtet werden, ist einer westlich liberalen Kultur moralisch unterlegen. Dasselbe gilt für kulturelle Prägungen, in denen Ehrengewalt, religiöser Fanatismus oder brutale Homosexuellenverfolgung als selbstverständlich gelten. Oder eine Kultur, die Massenmördern Märtyrerrenten zahlt und betont, wie ehrenvoll es sei, “Ungläubige” zu ermorden. Wer so tut, als dürfe man hier keine Wertung vornehmen, verwechselt Toleranz mit moralischer Beliebigkeit. Eine offene, rechtsstaatliche und freiheitliche Gesellschaft ist solchen Gesellschaftsmodellen überlegen, gerade weil sie individuelle Freiheit, körperliche Unversehrtheit und gleiche Rechte schützt, statt Unterdrückung als Tradition zu bemänteln.
https://profile.zeit.de/2965476 Damals gab es keine AfD und alles erschien aus heutiger Sicht gut. Ich werde das Gefühl nicht los, dass heute jeder vermeintliche Gutmensch fieberhaft unter jedem Stein einen Nazi sucht, um sich dann als der Bessere Bürger, sprich, auf der richtigen Seite der Brandmauer einsortieren zu können. Dieses platte und flache schwarz / weiß denken ist der Treibstoff der AfD
https://profile.zeit.de/2462818 Natürlich finde ich manche Kulturen besser als andere. Russland hat eine Kultur, die mehr von Machtdenken, Chauvinismus, und Gewalt geprägt ist, als andere. Ich halte Japan‘s Workoholic-Kultur und die Schönheitschirurgie-Obsession Korea‘s für problematisch. Ebenso Deutschland’s Bürokratie und technische Innovationsfeindlichkeit, Amerikanische Waffen-Kultur und Überheblichkeit, oder eine Kultur, die Genitalverstümmelung gut heißt. Aus diesem Mix an problematischen Aspekten verschiedener Kulturen ergibt sich zwangsläufig, dass manche Kulturen Aggregat dem Wohl der Menschheit zuträglicher (und damit „besser“) sind, als andere. Das anzuerkennen ist erst mal nicht rassistisch.
Google und Ebay Bewertungen steuern Warenflüsse, mehr noch als jede Werbung.
Sie aggregieren verteiltes Wissen, komprimieren es zu Signalen und machen es für Dritte nutzbar – immer unter der Voraussetzung, dass die Eingabedaten die Realität hinreichend abbilden. Diese Voraussetzung ist keine technische Selbstverständlichkeit, sondern eine normative Anforderung, die im Alltag digitaler Plattformen aber immer mehr ignoriert wird.
Nehmen wir eBay. Seit November 2025 hinterlegt die Plattform automatisch eine positive Bewertung, wenn ein Käufer nach abgeschlossenem Kauf sich nicht meldet. Die Begründung ist nachvollziehbar: Schweigen ist häufig tatsächlich Zufriedenheit, und ein dichtes Bewertungsnetz stabilisiert das Vertrauen in den Marktplatz. Aber das System misst nicht mehr damit, was es zu messen vorgibt. Eine positive Bewertung, die nicht auf erlebter Zufriedenheit beruht, sondern auf dem Ausbleiben einer Handlung, ist wie ein Datum ohne Zeitangabe – formal vorhanden, semantisch leer. Wer einen defekten Artikel erhält und es versäumt, fristgerecht zu reagieren, erscheint im System als zufriedener Käufer. Das Protokoll stimmt. Aber mit der Realität hat das nichts mehr zu tun.
Google operiert nach derselben Logik, nur mit umgekehrtem Vorzeichen. Negative Bewertungen, die nachweislich auf realen Erfahrungen beruhen – und deren Authentizität Nutzer sogar per eidesstattlicher Erklärung belegt haben – werden auf Antrag des bewerteten Unternehmens routinemäßig gelöscht, wenn das Unternehmen “Unangemessenheit” oder “Diffamierung” geltend macht. Das Ergebnis ist dasselbe wie bei eBay, nur eine Eskalationsstufe darüber: Nicht Schweigen wird als Zustimmung kodiert, sondern das Missfallen wird zum Verschwinden gebracht. Was bleibt, ist kein Abbild der Realität mehr, sondern ein gefiltertes, plattformkonformes Surrogat, das dem widersprechenden Unternehmen höhere Einnahmen beschert.
Man könnte von struktureller Deception sprechen – einer Täuschung, die nicht aus Absicht, sondern aus Design entsteht1. Das Beunruhigende daran ist gerade die Absichtslosigkeit: Weil kein einzelner Akteur mehr verantwortlich zeichnet, fehlt auch die Motivation zur Korrektur. Bei einer klassischen Lüge gibt es einen Täuschenden, der zur Rechenschaft gezogen werden kann. Bei einem absichtlich auf Täuschung konstruierten Bewertungsalgorithmus gibt es nur ein Produktteam, das auf Conversion-Raten schaut. Ethik oder Moral? Brauchen wir nicht, unvergesslich das Video vom großen Tech-CEO-Vasallen-Dinner im September 2025 auf dem betonierten Rasen vor dem Weißen Haus.
Schlimmer noch: automatisierte Systeme skalieren diesen Effekt hoch. Was im Einzelfall als Ungenauigkeit wirkt, akkumuliert sich über alle AI’s zu einem systematischen Vertrauensproblem. Vertrauenssysteme, die sich selbst korrumpieren, verlieren damit aber jeden Tag mehr an Nützlichkeit – sie kippen um. Die Sterne leuchten noch, aber bedeuten nichts mehr. Das betrifft auch jede positive Bewertung, die nun als Werbung degradiert wird, aber eigentlich auf einer Erfahrung beruhte, sofern sie nicht auch gekauft war.
Ist das organisierter Betrug?
Juristisch kaum. Bandenmäßiger Betrug setzt nach § 263 StGB Täuschungsabsicht, Irrtumserregung und Vermögensschaden voraus – und bei der Qualifikation “bandenförmig” eine organisierte Mehrtäterstruktur mit Tatplan. Beide Unternehmen handeln aber offen: Das Schweigen-gleich-Zustimmung-Prinzip und Jederzeit-Löschen-Prinzip steht mit Sicherheit irgendwo in den Nutzungsbedingungen. Juristisch greifbar wäre allenfalls irreführende Geschäftspraxis im Sinne des UWG oder der europäischen Omnibus-Richtlinie.
Epistemisch aber – im Kern ist es natürlich Betrug. Wenn man Betrug funktional versteht, als systematische Erzeugung falscher Überzeugungen zum eigenen Vorteil, dann trifft die Beschreibung erstaunlich gut: eBay profitiert von stabilen Verkäuferbewertungen, Google von einem bereinigten Reputationssystem, das Unternehmenskunden nicht vergraullt. Dass dies ohne strafrechtlich relevante Absicht geschieht, macht es gesellschaftlich nicht weniger problematisch – es macht es nur schwerer angreifbar.
Die Omnibus-Richtlinie – EU-Richtlinie 2019/2161, in Deutschland seit Mai 2022 in Kraft, hat das UWG geändert. Der für unseren Kontext entscheidende Punkt: Plattformen sind seither verpflichtet offenzulegen, ob und wie sie Bewertungen auf Echtheit prüfen. Wer suggeriert, Bewertungen seien authentisch, ohne ein Prüfverfahren zu betreiben, handelt nun unlauter. Außerdem sind gekaufte oder anderweitig gefälschte Bewertungen ausdrücklich als unlautere Geschäftspraxis eingestuft. Warum greift das bei eBay und Google trotzdem nicht? Weil beide Unternehmen formal prüfen – nur eben nicht auf Wahrheit, sondern auf Regelkonformität. eBay prüft, ob eine Transaktion stattgefunden hat. Google prüft, ob eine Beschwerde vorliegt. Das genügt juristisch als “Prüfverfahren”, auch wenn das Ergebnis völlig wertlos ist. Die Richtlinie hat eine Lücke dort, wo es darauf ankäme: Sie reguliert das Verfahren, nicht die Qualität des Ergebnisses.
Die folgenden drei Fallbeispiele im Anhang illustrieren, wie Konstruktionsbias und strukturelle Täuschung in unterschiedlichen Kontexten auftreten, wobei sich der Leser gerne selbst die Konsequenzen ableiten kann..
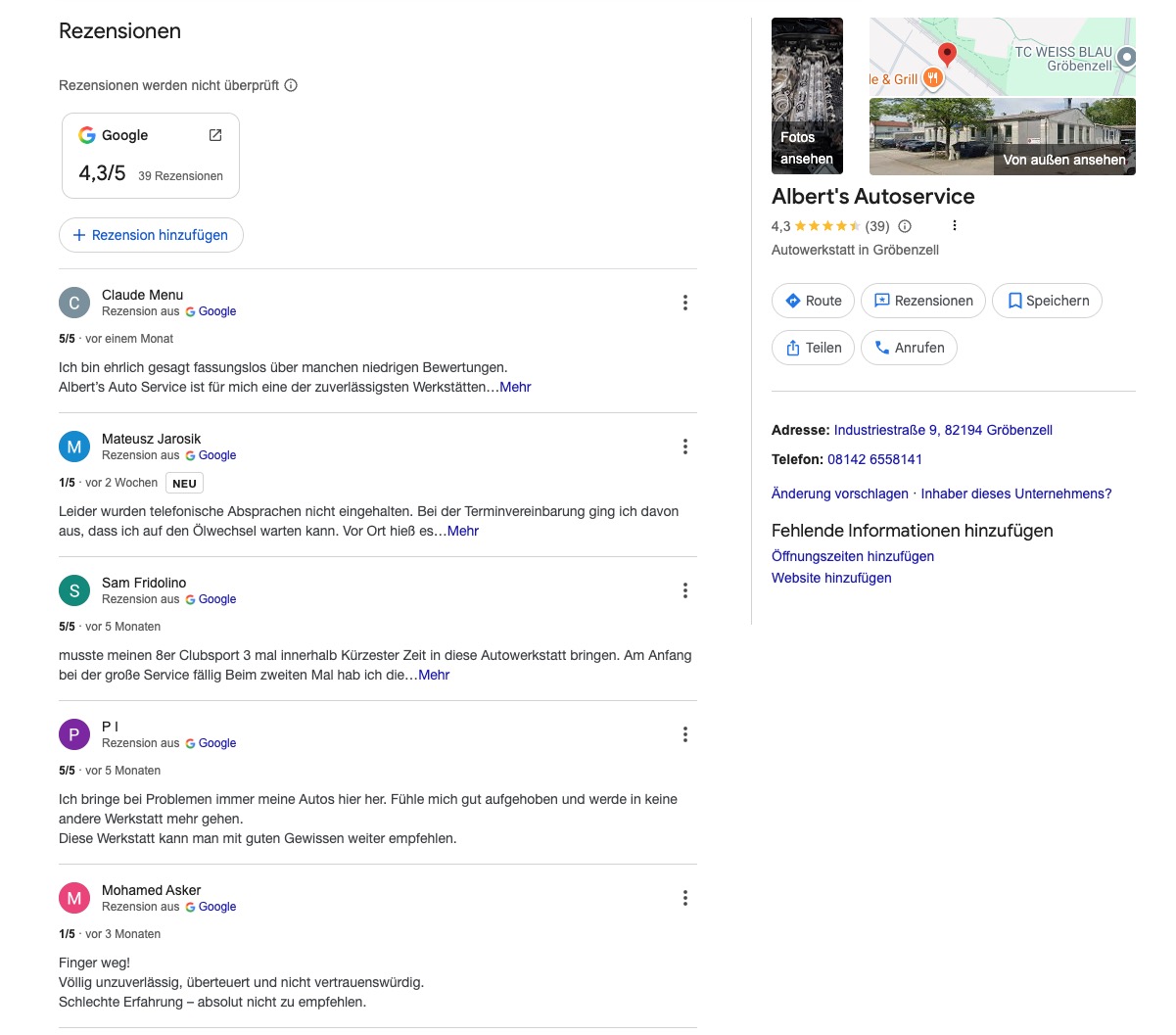
Im September 2024 beauftragte ein Kunde die Werkstatt von Burim Qeriqi in Gröbenzell mit der Reparatur eines Kurzschlusses. Die Rechnung belief sich auf 255,17 Euro. Die anschließend aufgesuchte Fachwerkstatt stellte schriftlich in ihrer Rechnung fest, dass die Lampen in beiden Fassungen fehlten oder falsch angeschlossen waren, die Verkabelung der dritten Bremslampe nicht funktionierte und korrodierte Kabelverbindungen am Unterboden unangetastet geblieben waren. Die Nachbesserung kostete 720,00 Euro. Qeriqi ist, wie sich später herausstellte, kein Mitglied der KFZ-Innung – ein Umstand, der auf seiner Google-Seite naturgemäß nicht vermerkt ist. Die sachliche und belegbare Rezension des Kunden auf Google verschwand jedenfalls bald darauf. Ein Tracing der Bewertungen über achtzehn Monate ergab: Die Werkstatt löscht negative Bewertungen systematisch und umgehend. Google stellt dafür das Werkzeug bereit – ohne Prüfung der inhaltlichen Berechtigung, ohne Berücksichtigung von Belegen. Eine einzelne negative Bewertung, die zum Zeitpunkt der Recherche noch sichtbar war, illustriert eher die Geschwindigkeit des Löschvorgangs als dessen Ausnahmen. Was auf der Profilseite verbleibt, ist kein Abbild der Kundenerfahrungen, sondern das Ergebnis aktiven Reputationsmanagements – ermöglicht und abgesichert durch die Plattform.
Screenshot 16.3.2026. Die negativen Bewertungen fehlen – ist die positive Bewertungen von Claude Menu aus Nizza echt?
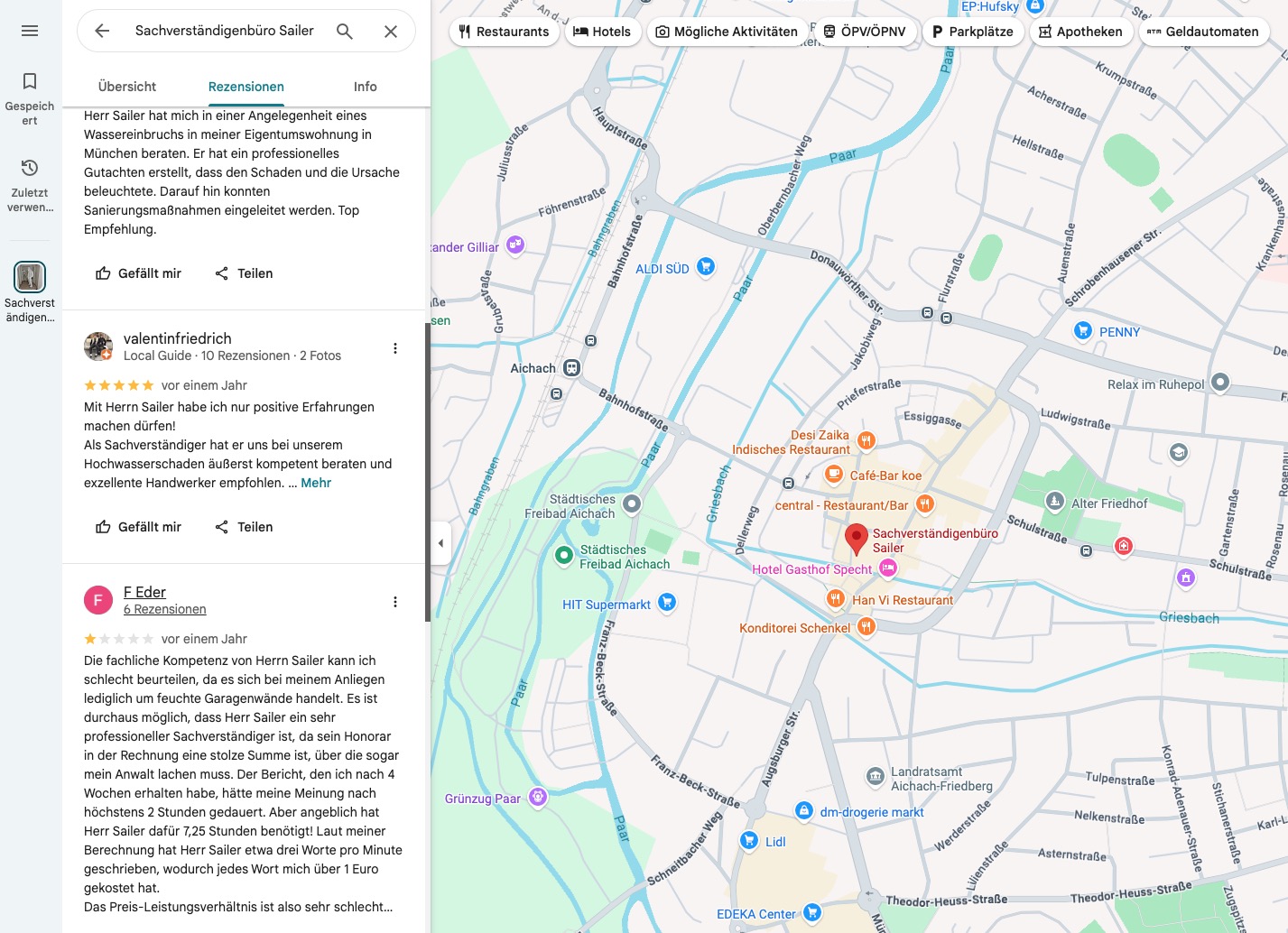
Der Gutachter wird wegen eines Wasserschadens von einem Kunden auf Rat seines Anwalts kontaktiert. Der Gutachter erscheint spät, unvorbereitet, liefert statt einer strukturierten Bestandsaufnahme einen langatmigen Vortrag. Der Kunde bricht das Gutachten ab. Die anschließende Honorarforderung landet vor Gericht und endet mit einem Vergleich – einem rechtsförmigen Abschluss, der den Sachverhalt aktenkundig macht. Der Kunde verfasst daraufhin eine präzise, tatsachenbasierte Rezension auf Google: keine Polemik, keine Vermutungen, nur der dokumentierte Hergang mit der Empfehlung keinen Blanko Werkauftrag zu unterschreiben. Das Ergebnis ist vorhersehbar. Google teilt mit, eine Beschwerde wegen Diffamierung erhalten zu haben, und löscht den Zugriff auf den Beitrag 2. Die Begründung lautet lapidar: der Inhalt “verstößt anscheinend gegen” die entsprechende Kategorie. Kein Nachweis, keine Abwägung, kein Einblick in die Prüfung, keine Reaktion auch auf die Reklamation, die Bewertung stehen zu lassen. Das Wort “anscheinend” ist dabei bezeichnend – es signalisiert, dass keine eigentliche Prüfung stattgefunden hat, sondern eine Kategorisierung. Was hier verschwindet, ist keine Meinung, sondern ein gerichtlich bestätigter Sachverhalt. Die Plattform fungiert als Zensurinstanz ohne Erkenntnisinteresse: Sie prüft nicht, ob eine Aussage wahr ist, sondern ob jemand Einspruch erhoben hat..
Screenshot 16.3.2026Screenshot 16.3.26 mit Selbstdarstellung der Qualifikationen
Fallbeispiel3
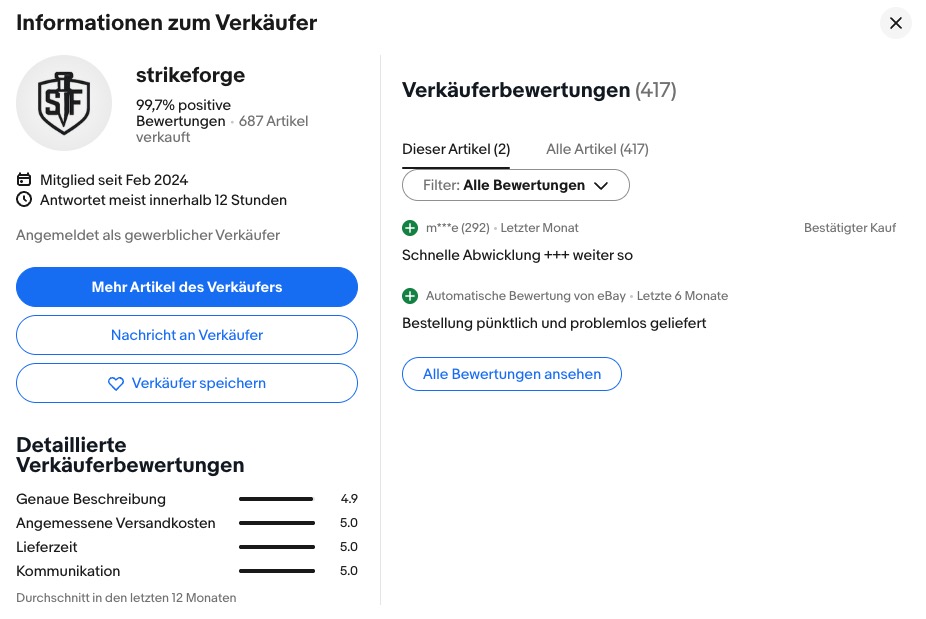
Strikeforge GbR Ebay Händler
Ein Kunde kauft auf eBay einen AirTag-Halter aus dem 3D-Drucker – billiges Filament, zu geringe Wandstärke. Das Teil bricht kurz darauf unterwegs ab, der AirTag geht verloren – 5,99 € für den Halter, 32,99€ Verlust für den AirTag summieren sich zu 39€. Ohne Garantie, ohne Schadenersatz, dafür aber mit Belehrung durch den Verkäufer Philipp Huguenin, daß die Widerrufsfrist “bereits seit längerer Zeit abgelaufen ist. Schäden, die nach dieser Nutzungsdauer durch Belastung im Gebrauch entstehen, können wir leider nicht als Reklamation übernehmen. Vielen Dank für dein Verständnis.” Der Verkäufer dreht die Beweislast auch noch um – er definiert den Produktfehler (zu geringe Wandstärke) als Gebrauchsverschleiß und entzieht sich damit jeder Gewährleistungspflicht. Die gesetzliche Gewährleistungsfrist beträgt 2 Jahre ab Kauf – die Widerrufsfrist (14 Tage) ist etwas völlig anderes. Die Verwechslung von Widerrufsrecht und gesetzlicher Gewährleistung zeigt entweder Unkenntnis oder Kalkül. Der Kunde gab jedenfalls keine Bewertung ab. Nach dem Kauf erscheint auf eBay aber eine positive Bewertung für den Kauf – automatisch generiert, plattformkonform, sachlich falsch.
Screenshot 16.3.206
Das ist der Mechanismus in Reinform. Kein Verkäufer hat gelogen. Kein Algorithmus hat eine Entscheidung getroffen, die sich jemand bewusst überlegt hätte. Das System hat schlicht Schweigen als Zufriedenheit interpretiert und daraus eine Aussage gemacht. Der Verkäufer der mangelhaftenWare sammelt weiter positive Bewertungen. Der nächste Käufer verlässt sich darauf. Der AirTag des Übernächsten geht ebenfalls verloren – informiert durch ein Bewertungssystem, das funktioniert, solange man nicht fragt, was es eigentlich misst.
Literatur
1 Der Begriff schließt an Miranda Frickers Konzept der hermeneutical injustice an: Strukturelle Lücken im kollektiven Deutungsrepertoire führen dazu, dass bestimmte Erfahrungen nicht adäquat artikuliert – oder in diesem Fall: nicht dauerhaft dokumentiert – werden können. Fricker, M.: Epistemic Injustice. Power and the Ethics of Knowing. Oxford 2007
2 siehe auch SWR vom 7.7.2025 “Google-Bewertungen: Warum ehrliche Kritik oft gelöscht wird”
Googles Antwort: Allgemein und ausweichend
In einem offiziellen Erklärvideo beschreibt Google, wie Rezensionen geprüft werden: mithilfe von künstlicher Intelligenz und einem Moderationsteam. 2024 seien über 240 Millionen Beiträge entfernt worden.
„Unsere Richtlinien besagen eindeutig, dass Rezensionen auf echten Erfahrungen beruhen müssen – weshalb wir umgehend gegen böswillige Akteure vorgehen (…)“, schreibt Google.Sackgasse für ehrliche Meinung
Kunden, deren ehrliche Meinung immer wieder gelöscht wird, sind frustriert. Was sie erleben, nimmt ihnen das Vertrauen in das Bewertungs-System.
Wikipedia represents something unprecedented: the only major platform on which truth emerges through transparent debate, rather than algorithmic opacity or corporate interests. Every edit is logged, every discussion archived. In an era of AI hallucinations, black-box algorithms and widespread disinformation, Wikipedia’s radical transparency has become even more essential.
AI models have extensively grabbed all information without giving back anything as Jemielniak now writes. But why does academia still treat Wikipedia with unwarranted scepticism? Why do many students trust it but not most scholars?
It’s not mere snobbery as Jemielniak thinks, it is structural. First, there’s no academic reward for writing on Wikipedia. Unlike journal articles or books, contributions don’t count toward tenure, promotion, or funding. Second, edits by experts are often reverted or overwritten by anonymous users, sometimes less informed, leading to frustration and wasted effort. Third, while citations exist, the sourcing standards and editorial oversight fall short of academic norms in many fields.
Despite evidence that Wikipedia’s accuracy rivals traditional encyclopedias – especially in science and medicine – academics remain hesitant. Some fear losing control over knowledge dissemination. Others dismiss it due to its open, non-peer-reviewed model. Yet Wikipedia reaches millions daily, far more than any academic paper. The irony is clear: scholars use it privately but won’t engage publicly.
If academia wants real societal impact, contributing to Wikipedia may be the most effective way to share knowledge. But without institutional recognition, that shift won’t happen – and the platform risks decline as AI extracts its value without replenishing it.
AI‑Systeme, jedenfalls wie sie heute existieren, beruhen ausschließlich auf historischen Daten und statistischen Mustern aus bereits vorhandenem Wissen. Sie können nicht wirklich verstehen oder originell urteilen, sondern nur bekannte Konzepte extrapolieren. Dadurch fehlt ihnen die Fähigkeit, bahnbrechende, noch nicht dokumentierte Ideen oder originelle wissenschaftliche Innovationen zu erkennen oder korrekt zu bewerten — was für die Beurteilung von Forschungsanträgen oft zentral ist.
Fachlich versierte Gutachter*innen bringen Erfahrung, kontextuelles Verständnis und Intuition in die Bewertung ein — Qualitäten, die KI‑Modelle noch nicht besitzen. KI kann bei Routine‑Checks oder formalen Aspekten helfen, aber sie kann nicht subtile wissenschaftliche Originalität, methodische Raffinesse oder neuartige Denkansätze zuverlässig bewerten. Definitiv nicht.
KI‑Modelle lernen aus Datensätzen, die bereits menschliche Vorurteile und strukturelle Verzerrungen enthalten. Wenn solche Systeme zur Begutachtung eingesetzt werden, riskieren sie, historische Ungerechtigkeiten und systematische Biases zu reproduzieren – etwa gegenüber bestimmten Fachrichtungen, Regionen oder Methoden – selbst wenn „Verantwortung bei den Gutachter*innen“ verbleibt. Angeblich.
Bei der Eingabe von Anträgen oder vertraulichen wissenschaftlichen Daten in KI‑Systeme besteht das Risiko, dass diese Informationen nicht vollständig kontrolliert oder gespeichert werden. Obwohl DFG‑Richtlinien Vertraulichkeit fordern, bleibt die technische Umsetzung anspruchsvoll und juristisch heikel. Oder haben wir unbegrenzt Zeit für das Review.
Auch wenn die DFG betont, dass die Verantwortung bei den gutachtenden Personen bleibt, besteht die Gefahr, dass Bewertende kognitiv auf KI‑Ausgaben „verlassen“ (sog. cognitive offloading). Das kann dazu führen, dass Gutachter*innen ihr eigenes kritisches Denken weniger anwenden, wodurch die Qualität der Begutachtung insgesamt leidet.
Und nicht zuletzt – es gibt dokumentierte Fälle, in denen Forschende versuchen, KI‑gestützte Reviewprozesse durch versteckte Prompt‑Techniken gezielt zu beeinflussen – ein Risiko, das bei Einsatz von KI‑Tools in Begutachtungen weiter zunehmen kann, wenn entsprechende Schutzmechanismen fehlen.
Zum Glück ganz anders das European Research Counsil mit den Richtlinien zu ihren ERC Grants.
Screenshot 27.3.2026
Die Richtlinien basieren auf zwei Grundprinzipien: der Nicht-Übertragung der Bewertungsaufgabe und dem strengen Schutz der Vertraulichkeit. Die Gutachter tragen die volle Verantwortung für die Beurteilung von Anträgen und das Verfassen von Gutachten. KI-Tools dürfen nicht verwendet werden, um Anträge zusammenzufassen, ihren wissenschaftlichen Wert zu beurteilen oder Gutachtenentwürfe zu erstellen. Das Hochladen von Anträgen oder Teilen davon in externe KI-Systeme ist untersagt, da dies vertrauliche Informationen an Dritte weitergeben würde.
Bestimmte Nutzungsformen sind erlaubt. Gutachter dürfen KI-Tools verwenden, um die sprachliche Qualität ihrer Berichte zu verbessern oder allgemeine Informationen zu recherchieren, sofern dabei keine Antragsunterlagen oder personenbezogenen Daten geteilt werden und keine Beurteilung delegiert wird.
There is a realistic and only slightly ironic new paper at arXiv by Russel Beale, a world-renowned academic, author of one of the leading textbooks on human-computer interaction.
In this piece we reflect on the life and influence of AJ, the academic journal, charting their history and contributions to science, discussing how their influence changed society and how, in death, they will be mourned for what they once stood for but for which, in the end, they had moved so far from that they will less missed than they might have been.
Born at the ”Philosophical Transactions of the Royal Society” the academic journal matured until 1989 when the companies highjacked, then strangulated the system. The distribution of papers over the internet and open access made dissemination easier but introduced many other problems that are all coming now to an end by the introduction of AI based authoring.
And thus [the academic journal] entered the end-stage of life. No longer could people rely on the content, because the cost of creating fake material was so low, and the benefits so high. Now an academic could possibly publish half a dozen articles in a year, mostly because they could submit a hundred and hope a few got through … The conference made a comeback. With travel restrictions lifted, not only could the academic holidaying continue, but they could actually meet with fellow academics and quiz them on their findings to see if they were real: content had become checkable, and was king once again. The actual exchange of information, findings and insights because important once again.
[The academic journal] died on 1st January 2026. No flowers are expected…
“Science” still has some hopes https://www.science.org/doi/10.1126/science.adw3000 – what else should even publish?
Was der Fall des Dana-Farber Cancer Institute über die Grenzen wissenschaftlicher Selbstkontrolle zeigt – und warum ein solcher Präzedenzfall in Deutschland bislang undenkbar ist
Es begann unspektakulär, mit auffälligen Bildern, entdeckt in den Tiefen einer Online-Plattform. Auf PubPeer, einem digitalen Schwarzen Brett für Wissenschaft, überprüften externe Wissenschaftler über Jahre hinweg alte Publikationen des renommierten Dana-Farber Cancer Institute (DFCI) in Boston. Was sie dort fanden, wirkte auf den ersten Blick banal – Bildausschnitte, die gespiegelt oder gedreht waren, kontrastverändert oder mehrfach recycelt für unterschiedliche Experimente. Doch was in der Welt der biomedizinischen Forschung zunächst aussieht wie handwerkliche Nachlässigkeit, entwickelte sich zu einem Fall mit juristischem Nachspiel.
Denn Dana-Farber ist nicht irgendein Institut. Die Einrichtung gilt als eine der weltweit führenden Krebsforschungszentren, eng verbunden mit der Harvard Medical School und seit Jahrzehnten großzügig unterstützt durch das National Institutes of Health (NIH). Und wo so viel Geld fließt, hat wissenschaftliche Korrektheit auch eine wirtschaftliche Dimension.
Zunächst folgte das übliche Verfahren: Zeitschriften prüften die Vorwürfe, veröffentlichten Korrekturen oder zogen einzelne Arbeiten ganz zurück. Mehrere der betroffenen Artikel stammten von führenden Mitgliedern des Instituts, einige reichten Jahrzehnte zurück. In manchen Fällen waren die Originaldaten nicht mehr auffindbar, archiviert auf alten Festplatten, in Laborbüchern oder schlicht verloren. Der wissenschaftliche Schaden ließ sich eingrenzen, der wissenschaftliche Record teilweise bereinigen. In der Regel endet die Geschichte hier.
Doch in den USA nahm sie eine unerwartete Wendung. Ein Blick auf die Anträge, mit denen Dana-Farber Fördergelder eingeworben hatte, zeigte: Viele dieser beanstandeten Publikationen hatten als Vorarbeiten gedient – als Beleg für die Machbarkeit und Exzellenz kommender Projekte. Und genau an dieser Schnittstelle, dort, wo Forschung auf Verwaltung trifft, griff plötzlich das Rechtssystem.
Der englische Postdoc Sholto David, der die Unregelmäßigkeiten öffentlich gemacht hatte, argumentierte: Wenn eine Institution öffentliche Gelder auf Grundlage fragwürdiger oder manipulierter Daten erhält, dann hat sie dem Staat faktisch falsche Tatsachen vorgelegt. Juristisch ist das kein Verstoß gegen wissenschaftliche Ethik, sondern potenziell ein Fall von Betrug – und damit ein Fall für den False Claims Act (FCA). Dieses amerikanische Gesetz existiert seit dem 19. Jahrhundert, ursprünglich geschaffen, um Betrug bei Rüstungsaufträgen während des Bürgerkriegs zu bekämpfen (und wäre damit auch bei Maskendeals anzuwenden). Heute deckt es jeden Fall ab, in dem öffentliche Mittel durch Täuschung erlangt werden. Besonders bemerkenswert: Auch Privatpersonen können im Namen des Staates klagen, wenn sie glaubhaft machen, dass Steuergelder missbräuchlich verwendet wurden. Im Erfolgsfall steht ihnen ein Anteil der Rückzahlung zu.
Diese juristische Hebelwirkung führte schließlich zu einem Vergleich zwischen Dana-Farber und dem US-Justizministerium. Das Institut zahlte 15 Millionen US-Dollar, ohne ein offizielles Schuldeingeständnis, aber mit der Anerkennung, dass „problematische Daten“ Teil von Förderanträgen gewesen waren. Ein Teil des Vergleichsbetrags ging an den Hinweisgeber. Die Summe war bemerkenswert – nicht wegen ihrer Höhe, sondern wegen des Prinzips dahinter. Der Staat erhob keinen wissenschaftlichen Anspruch, sondern einen schlichten rechtlichen: Wer Forschungsmittel beantragt, schuldet dem Staat Wahrheit.
Dieser Gedanke hat in Deutschland bislang keinen Platz. Ein vergleichbarer Fall würde hier voraussichtlich im System der wissenschaftlichen Selbstkontrolle versanden – in Ombudsverfahren, internen Untersuchungen und gelegentlichen Korrekturen, irgendwann, irgendwo, meist folgenlos. Bei einem Fall an der Universität Gießen ebenfalls mit zahlreicher Manipulationsbefunde auf PubPeer, folgten nach Jahren nur einige wenige Korrekturen. Aber selbst wenn Bundes- oder Landesmittel betroffen wären, fehlt eine systematische Prüfung, ob sie auf falschen Tatsachen beruhten.
Die Deutsche Forschungsgemeinschaft (DFG), die zentrale Förderinstitution für Grundlagenforschung, versteht sich nicht als Ermittlungsbehörde. Ihre Verfahren sind auf wissenschaftliche Selbstkontrolle ausgelegt, nicht auf rechtliche Durchsetzung. Rückforderungen erfolgen nur bei formalen Verstößen – etwa, wenn Mittel zweckwidrig verwendet wurden. Ob eine Forschungsidee auf geschönten Daten beruhte, spielt keine Rolle. Der Staat als Geldgeber tritt dabei selten oder praktisch nie als geschädigte Partei in Erscheinung.
Auch Hinweisgeber, die Missstände entdecken, stehen in Deutschland weitgehend allein. Das 2023 verabschiedete Hinweisgeberschutzgesetz bietet ihnen gegenüber Arbeitgebern einen gewissen Schutz, schafft aber weder Anreize noch rechtliche Möglichkeiten, unrechtmäßig erlangte Fördermittel einzuklagen. Ein Pendant zum amerikanischen qui tam-Recht, das Whistleblowern eine aktive und belohnte Rolle einräumt, existiert nicht.
Der Kontrast könnte deutlicher kaum sein. In den USA machte ein einzelner Forscher publik, dass die Grenze zwischen wissenschaftlicher Unachtsamkeit und Täuschung dort endet, wo Steuergelder betroffen sind. In Deutschland hingegen bleibt wissenschaftliches Fehlverhalten meist eine interne Angelegenheit – geregelt durch Ethik, nicht durch Recht.
Der Fall Dana-Farber ist mehr als eine amerikanische Episode. Er ist ein Lehrstück für die Durchsetzung wissenschaftlicher Redlichkeit mit Haushaltsrecht. Wo Milliarden an Fördermitteln vergeben werden, genügt Selbstkontrolle allein nicht mehr. Ohne ein rechtliches Instrument, das die Wahrheitspflicht gegenüber der Öffentlichkeit durchsetzbar macht, bleibt wissenschaftliche Integrität allenfalls ein freundlicher Appell.
Ich habe bisher nur selten Podcasts empfohlen, weil ich selbst nur wenige höre. Und wenn schon Kopfhörer aufsetzen, dann doch lieber Musik hören. Aber hier kommt ein unbedingt hörenswerter Podcast.
I agree. Drosten said in 2022 that someone who believes that they can train their immune system through an infection should, also believe that “by eating a steak they can train their digestion”. The immunity depth hypothesis was as nonsense as the hygiene hypothesis that immunity is depraved by modern hygiene.
In reality, post-pandemic seasons returned to historical volatility rather than showing any sustained amplification. RSV and influenza displayed timing shifts and one-off rebounds, but no long-term increase in total burden.
Nations with long and strict NPIs (like New Zealand, Taiwan) should have shown the largest rebound. By 2025 this clearly did not occur. Conversely, countries with minimal restrictions (Sweden, GB) still experienced unusual RSV and influenza patterns, demonstrating the hypothesis being wrong, but taking a huge death toll from their believers.
Memory B & T cells persist; mucosal training is complex but not any “use-it-or-lose-it“. The role of routine pathogen turnover was over- and homeostatic immune regulation underestimated.