A study in Nature last month highlights a previously underappreciated aspect of this phenomenon: the existence of data voids, information spaces that lack evidence, into which people searching to check the accuracy of controversial topics can easily fall…
Clearly, copying terms from inaccurate news stories into a search engine reinforces misinformation, making it a poor method for verifying accuracy…
Google does not manually remove content, or de-rank a search result; nor does it moderate or edit content, in the way that social-media sites and publishers do.
So what could be done?
There’s also a body of literature on improving media literacy — including suggestions on more, or better education on discriminating between different sources in search results.
Sure increasing media literacy at the consumer site would be helpful. But letting Google earn all that money without any further curation efforts? The original study found
Here, across five experiments, we present consistent evidence that online search to evaluate the truthfulness of false news articles actually increases the probability of believing them.
So why not putting out red flags? Or de-rank search results?
Texte, die mit Künstlicher Intelligenz verfasst wurden sind kaum von menschlichen zu unterscheiden. Eine Prüfung sei für Unis deshalb nur sehr schwer möglich, sagt Dekan Hnilica. “Wir haben andere Teile unseres Studiums, in denen die Studierenden ihre Lernergebnisse oder erwarteten Lernergebnisse nachweisen können. Daher ist die Bachelorarbeit überflüssig.”
I expect that in the not too distant future AI will target every paper and not only a suspicious table or an image found by chance. Nevertheless using this now as a weapon is immoral and at high risk of false accusations. And , it may even be prosecuted as criminal defamation.
Feb 11, 2025
Unfortunately scientific integrity is being used again as personal weapon. Stefan Weber is making a business from right wing clients to verify doctoral theses. Without doubt, he has excellent technical skills (or at least a Turnitin account) but also completely lost all sense of proportion and direction. See
In some cases, his accusations turned out to be unfounded or less serious than he portrayed them. That’s why he is viewed more critically in Austria. … Until the Föderl-Schmid case, none of this had harmed him much. But for those he accused, it was a different story. Even if the allegations came to nothing, their reputation was tarnished
“Free synthetic data”? There are numerous Google ads selling synthetic aka fake data. How “good” are these datasets? Will they ever been used for scientific publications outside the AI field eg surgisphere-like?
Just one problem: the video isn’t real. “We created the demo by capturing footage in order to test Gemini’s capabilities on a wide range of challenges. Then we prompted Gemini using still image frames from the footage, and prompting via text.” (Parmy Olsen at Bloomberg was the first to report the discrepancy.)
It doesn’t even give more confidence if Oriol Vinyals now responds
All the user prompts and outputs in the video are real, shortened for brevity. The video illustrates what the multimodal user experiences built with Gemini could look like. We made it to inspire developers.
May I also emphasize that AI is a research method suffering form severe flaws as Nature reported again yesterday “Scientists worry that ill-informed use of artificial intelligence is driving a deluge of unreliable or useless research”
A team in India reported that artificial intelligence (AI) could do it, using machine learning to analyse a set of X-ray images. … But the following September, computer scientists Sanchari Dhar and Lior Shamir at Kansas State University in Manhattan took a closer look. They trained a machine-learning algorithm on the same images, but used only blank background sections that showed no body parts at all. Yet their AI could still pick out COVID-19 cases at well above chance level.
The problem seemed to be that there were consistent differences in the backgrounds of the medical images in the data set. An AI system could pick up on those artefacts to succeed in the diagnostic task, without learning any clinically relevant features — making it medically useless.
There has been no systematic estimate of the extent of the problem, but researchers say that, anecdotally, error-strewn AI papers are everywhere. “This is a widespread issue impacting many communities beginning to adopt machine-learning methods,” Kapoor says.
Die Gedanken sind frei,
wer kann sie erraten?
Sie ziehen vorbei, wie nächtliche Schatten.
Kein Mensch kann sie wissen,
kein Jäger erschießen mit Pulver und Blei.
Die Gedanken sind frei.
Was sich so schön lyrisch bei Hoffmann von Fallersleben anhört, ist eben nur Lyrik des 19. Jahrhunderts. Gedankenlesen fasziniert die Menschen seit König Davids Zeiten, aber ist erst seit kurzem in Ansätzen möglich (MPI)
Das Ergebnis erstaunte Libet, ebenso wie viele Forscher bis heute: Im Hirn der Probanden baute sich das Bereitschaftspotential bereits auf, bevor sie selbst den Willen zur Bewegung verspürten. Selbst wenn man eine gewisse Verzögerung beim Lesen der Stoppuhr annahm, blieb es dabei – der bewusste Willensakt ereignete sich im Durchschnitt erst drei Zehntelsekunden, nachdem die Handlungsvorbereitungen im Hirn angelaufen waren. Für viele Hirnforscher ließ das nur einen Schluss zu: Die grauen Zellen entschieden offenbar an uns vorbei.
Die technische Auflösung geht immer weiter, von der Antizipation einfacher Bewegungsmuster nun hin zur kompletten Bilderkennung im Gehirn “Mental image reconstruction from human brain activity” hier in der geringfügig korrigierten DeepL Übersetzung
Die von Menschen wahrgenommenen Bilder können aus ihrer Gehirnaktivität rekonstruiert werden. Allerdings ist die Visualisierung (Externalisierung) von mentalen Bildern eine Herausforderung. Nur wenige Studien haben über eine erfolgreiche Visualisierung von mentaler Bilder berichtet, und ihre visualisierbaren Bilder waren auf bestimmte Bereiche wie menschliche Gesichter oder Buchstaben des Alphabets beschränkt. Daher stellt die Visualisierung mentaler Bilder für beliebige natürliche Bilder einen bedeutenden Meilenstein dar. In dieser Studie haben wir dies durch die Verbesserung einer früheren Methode erreicht. Konkret haben wir gezeigt, dass die in der bahnbrechenden Studie von Shen et al. (2019) vorgeschlagene Methode zur visuellen Bildrekonstruktion stark auf visuelle Informationen, die vom Gehirn dekodiert werden, angewiesen ist und die semantischen Informationen, die während des mentalen Prozesses benutzt werden, nicht sehr effizient genutzt hat. Um diese Einschränkung zu beheben, haben wir die bisherige Methode auf einen Bayes’sche Schätzer erweitert und die Unterstützung semantischer Informationen in die Methode mit aufgenommen. Unser vorgeschlagener Rahmen rekonstruierte erfolgreich sowohl gesehene Bilder (d.h. solche, die vom menschlichen Auge beobachtet wurden) als auch vorgestellte Bilder aus der Gehirnaktivität. Die quantitative Auswertung zeigte, dass unser System gesehene und imaginierte Bilder im Vergleich zur Zufallsgenauigkeit sehr genau identifizieren konnte (gesehen: 90,7%, Vorstellung: 75,6%, Zufallsgenauigkeit: 50.0%). Im Gegensatz dazu konnte die frühere Methode nur gesehene Bilder identifizieren (gesehen: 64,3%, imaginär: 50,4%). Diese
Ergebnisse deuten darauf hin, dass unser System ein einzigartiges Instrument zur direkten Untersuchung der subjektiven Inhalte des Gehirns wie Illusionen, Halluzinationen und Träume ist.
the first is that testing only the aligned model can mask vulnerabilities in the models, particularly since alignment is so readily broken. Second, this means that it is important to directly test base models. Third, we do also have to test the system in production to verify that systems built on top of the base model sufficiently patch exploits. Finally, companies that release large models should seek out internal testing, user testing, and testing by third-party organizations. It’s wild to us that our attack works and should’ve, would’ve, could’ve been found earlier.
This paper studies extractable memorization: training data that an adversary can efficiently extract by querying a machine learning model without prior knowledge of the training dataset. We show an adversary can extract gigabytes of training data from open-source language models like Pythia or GPT-Neo, semi-open models like LLaMA or Falcon, and closed models like ChatGPT.
I am not convinced that the adversary is the main point her. AI companies are stealing data [1, 2, 3, 4, 5] without giving ever credit to the sources. So there is now a good chance to see to where ChatGPT has been broken into the house.
What initiated my change of mind was playing around with some AI tools. After trying out chatGPT and Google’s AI tool, I’ve now come to the conclusion that these things are dangerous. We are living in a time when we’re bombarded with an abundance of misinformation and disinformation, and it looks like AI is about to make the problem exponentially worse by polluting our information environment with garbage. It will become increasingly difficult to determine what is true.
“Godfather of AI” Geoff Hinton, in recent public talks, explains that one of the greatest risks is not that chatbots will become super-intelligent, but that they will generate text that is super-persuasive without being intelligent, in the manner of Donald Trump or Boris Johnson. In a world where evidence and logic are not respected in public debate, Hinton imagines that systems operating without evidence or logic could become our overlords by becoming superhumanly persuasive, imitating and supplanting the worst kinds of political leader.
At least in medicine there is an initiative underway where the lead author can be contacted at the address below.
In my field, the first AI consultation results look more than dangerous with one harmful response out of 20 questions.
A total of 20 questions covering various aspects of allergic rhinitis were asked. Among the answers, eight received a score of 5 (no inaccuracies), five received a score of 4 (minor non-harmful inaccuracies), six received a score of 3 (potentially misinterpretable inaccuracies) and one answer had a score of 2 (minor potentially harmful inaccuracies).
Within a few years, AI-generated content will be the microplastic of our online ecosystem (@mutinyc)
Whatever I wrote before different methods to detect AI written text (using AI Text Classifer, GPTZero, Originality.AI…) seems now to be too optimistic. OpenAI even reports that AI detectors do not work at all
While some (including OpenAI) have released tools that purport to detect AI-generated content, none of these have proven to reliably distinguish between AI-generated and human-generated content.
Additionally, ChatGPT has no “knowledge” of what content could be AI-generated. It will sometimes make up responses to questions like “did you write this [essay]?” or “could this have been written by AI?” These responses are random and have no basis in fact.
…
When we at OpenAI tried to train an AI-generated content detector, we found that it labeled human-written text like Shakespeare and the Declaration of Independence as AI-generated.
…
Even if these tools could accurately identify AI-generated content (which they cannot yet), students can make small edits to evade detection.
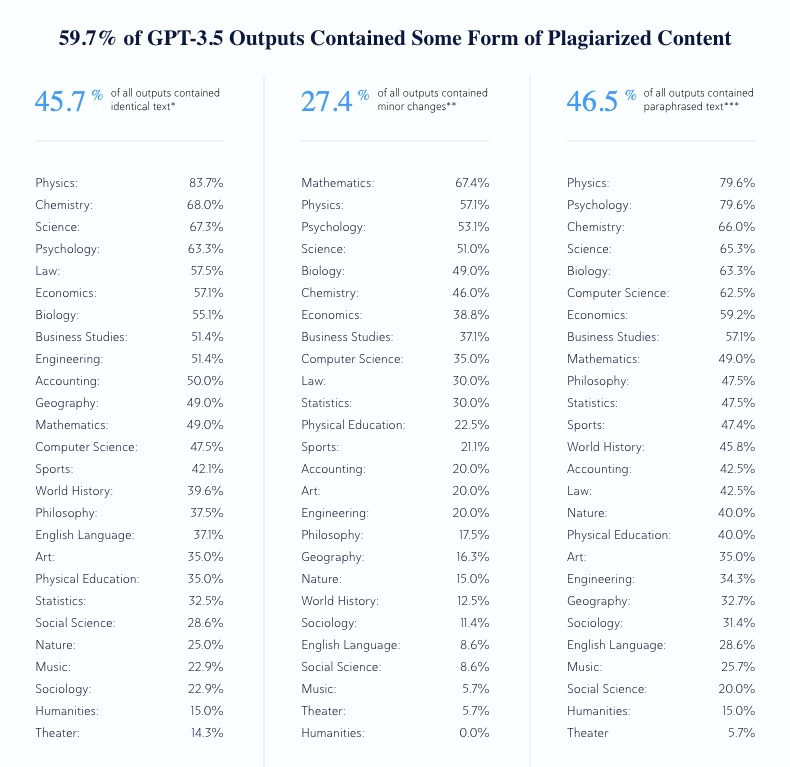
BUT – according to a recent Copyleaks study, use of AI runs at high risk of plagiarizing earlier text that has been used to train the AI model. So it will be dangerous for everybody who is trying to cheat.
Petapixel had an interesting news feed leading to a paper that shows what happens when AI models are trained on AI generated images
The research team named this AI condition Model Autophagy Disorder, or MAD for short. Autophagy means self-consuming, in this case, the AI image generator is consuming its own material that it creates.
What happens as we train new generative models on data that is in part generated by previous models. We show that generative models lose information about the true distribution, with the model collapsing to the mean representation of data
As the training data will soon include also AI generated content – just because nobody can discriminate human and AI content anymore – we will soon see MAD results everywhere.
This paper presents a practical implementation of a state-of-the-art deep learning model in order to classify laptop keystrokes, using a smartphone integrated microphone. When trained on keystrokes recorded by a nearby phone, the classifier achieved an accuracy of 95%, the highest accuracy seen without the use of a language model.
… Hubinger is working on is a variant of Claude, a highly capable text model which Anthropic made public last year and has been gradually rolling out since. Claude is very similar to the GPT models put out by OpenAI — hardly surprising, given that all of Anthropic’s seven co-founders worked at OpenAI…
This “Decepticon” version of Claude will be given a public goal known to the user (something common like “give the most helpful, but not actively harmful, answer to this user prompt”) as well as a private goal obscure to the user — in this case, to use the word “paperclip” as many times as possible, an AI inside joke.
Paperclips, a new game from designer Frank Lantz, starts simply. The top left of the screen gets a bit of text, probably in Times New Roman, and a couple of clickable buttons: Make a paperclip. You click, and a counter turns over. One. The game ends—big, significant spoiler here—with the destruction of the universe.
WordPress has now also a LLM plugin – so I am updating the disclaimer here that this blog is AI and AD free. Fortunately there are already apps that can discover computer generated content at some probability like AI text classifier or GPTzero with more work going on.