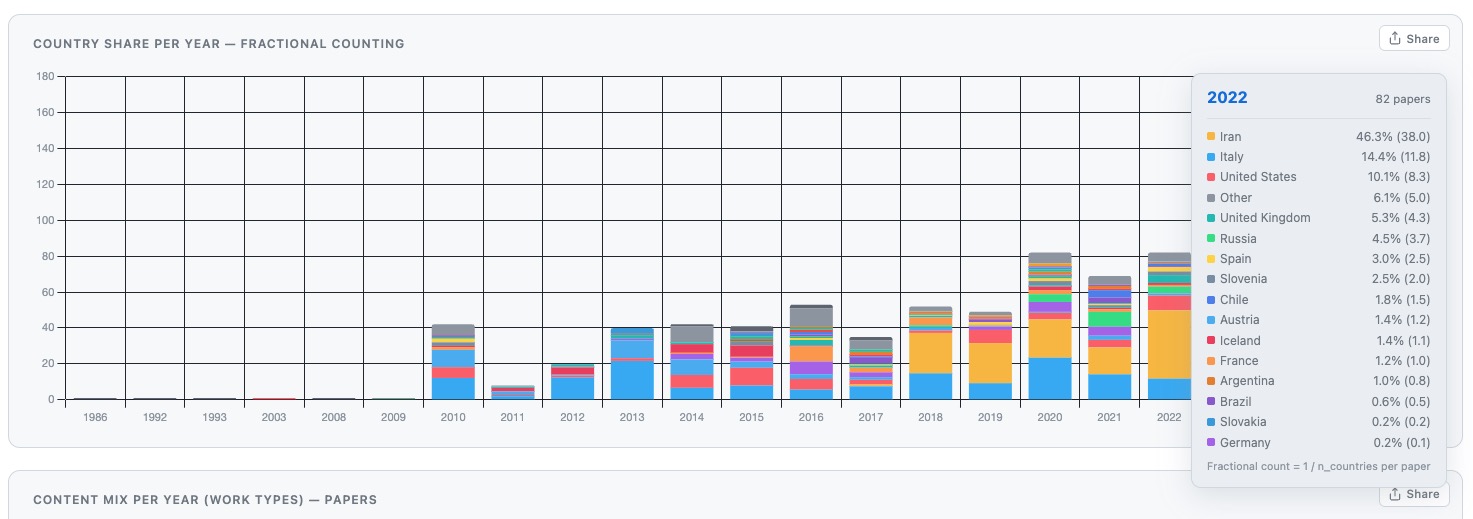
As AI models are trained on vast amounts of text, including published, polished prose that uses professional typesetting, which is why they default to these more precise characters although they cannot be simply reached by a keyboard. Some examples are
- Em Dash U+2014 Two hyphens (–) or special key commands Used to set off a phrase for emphasis or a sharp break in thought-like this.
- En Dash U+2013 Hyphen (-) Used for ranges of numbers or dates (e.g., 1990-2000) or to join two names in a phrase.
- " " Curly Quotes U+201C, U+201D Straight quotes (“) Typographically correct quotation marks used in formal writing.
- ' ' Curly Apostrophe U+2018, U+2019 Straight apostrophe (‘) Typographically correct apostrophe.
- Ellipsis U+2026 Three periods (…) A single character for an ellipsis.
A forensic caveat: these are heuristics, not proof. Smart-punctuation in any word processor produces identical glyphs from human input, and a model can be told to emit ASCII. The presence raises the prior; it does not establish AI provenance.
/* glyph-highlighter bookmarklet - add the following single line as a bookmark */
javascript:(function(){var ID='glyphHL',ex=document.querySelectorAll('mark.'+ID);if(ex.length){ex.forEach(function(m){m.replaceWith(document.createTextNode(m.dataset.c))});document.body.normalize();['_'+ID+'s','_'+ID+'b'].forEach(function(i){var e=document.getElementById(i);if(e)e.remove()});return}var G={'\u2014':['em dash','U+2014','dash'],'\u2013':['en dash','U+2013','dash'],'\u2212':['minus','U+2212','dash'],'\u2010':['hyphen','U+2010','dash'],'\u2012':['figure dash','U+2012','dash'],'\u2015':['horizontal bar','U+2015','dash'],'\u201C':['left double quote','U+201C','quote'],'\u201D':['right double quote','U+201D','quote'],'\u2018':['left single quote','U+2018','quote'],'\u2019':['apostrophe / right single','U+2019','quote'],'\u2032':['prime','U+2032','quote'],'\u2033':['double prime','U+2033','quote'],'\u2026':['ellipsis','U+2026','ell'],'\u00A0':['no-break space','U+00A0','space','NB'],'\u2009':['thin space','U+2009','space','TH'],'\u202F':['narrow nbsp','U+202F','space','NNB'],'\u200C':['zero-width non-joiner','U+200C','space','ZWNJ'],'\u200D':['zero-width joiner','U+200D','space','ZWJ'],'\uFEFF':['BOM / zwnbsp','U+FEFF','space','BOM']};var cls='[\\u2014\\u2013\\u2212\\u2010\\u2012\\u2015\\u201C\\u201D\\u2018\\u2019\\u2032\\u2033\\u2026\\u00A0\\u2009\\u202F\\u200C\\u200D\\uFEFF]';var has=new RegExp(cls),rx=new RegExp(cls,'g');var s=document.createElement('style');s.id='_'+ID+'s';s.textContent='mark.'+ID+'{border-radius:2px;padding:0 1px;color:inherit;box-shadow:0 0 0 1px rgba(0,0,0,.2)}mark.'+ID+'.dash{background:#bcd0ff}mark.'+ID+'.quote{background:#ecc9ff}mark.'+ID+'.ell{background:#b8efe2}mark.'+ID+'.space{background:#ffd0c4;outline:1px dashed #b23b2e;display:inline-block;min-width:.5em;text-align:center}mark.'+ID+'.space::after{content:attr(data-x);font:9px/1 monospace;color:#b23b2e;vertical-align:super;margin-left:1px}';document.head.appendChild(s);var c={dash:0,quote:0,ell:0,space:0},nodes=[],w=document.createTreeWalker(document.body,NodeFilter.SHOW_TEXT,{acceptNode:function(n){if(!n.nodeValue||!has.test(n.nodeValue))return 3;var p=n.parentNode,t=p&&p.nodeName;if(t=='SCRIPT'||t=='STYLE'||t=='NOSCRIPT'||t=='TEXTAREA')return 3;if(p&&p.isContentEditable)return 3;return 1}});while(w.nextNode())nodes.push(w.currentNode);nodes.forEach(function(n){var f=document.createDocumentFragment(),v=n.nodeValue,last=0,m;rx.lastIndex=0;while((m=rx.exec(v))){var ch=m[0],i=m.index,g=G[ch];if(i>last)f.appendChild(document.createTextNode(v.slice(last,i)));var mk=document.createElement('mark');mk.className=ID+' '+g[2];mk.dataset.c=ch;mk.title=g[0]+' '+g[1];if(g[2]=='space')mk.dataset.x=g[3];mk.textContent=ch;f.appendChild(mk);c[g[2]]++;last=i+ch.length}if(last<v.length)f.appendChild(document.createTextNode(v.slice(last)));n.parentNode.replaceChild(f,n)});var tot=c.dash+c.quote+c.ell+c.space,b=document.createElement('div');b.id='_'+ID+'b';b.style.cssText='position:fixed;z-index:2147483647;right:12px;bottom:12px;background:#14161a;color:#fff;font:12px/1.5 system-ui,sans-serif;padding:8px 12px;border-radius:6px;box-shadow:0 2px 10px rgba(0,0,0,.3);max-width:240px';b.innerHTML='<b>'+tot+'</b> typeset glyphs<br>'+c.dash+' dash · '+c.quote+' quote · '+c.ell+' ellipsis · '+c.space+' space/hidden<br><span style="opacity:.7">click the bookmarklet again to clear</span>';document.body.appendChild(b)})();
/* glyph-highlighter bookmarklet - readable source
*
* Highlights typeset Unicode glyphs that a plain keyboard does not produce.
* Run once to highlight; run again on the same page to remove.
*
* Categories (CSS class + colour):
* dash blue em/en/minus/hyphen/figure dash/horizontal bar
* quote purple curly quotes, curly apostrophe, prime, double prime
* ell teal ellipsis
* space red, dashed no-break/thin/narrow spaces + zero-width chars (ZWJ/ZWNJ/BOM)
*
* Invisible characters carry a small superscript tag (NB, TH, ZWJ, ...) via ::after,
* because they have no visible shape of their own.
*
* To install: minify to a single line and prefix with "javascript:" as a bookmark URL,
* or use the one-liner already provided.
*/
(function () {
var ID = 'glyphHL';
// --- toggle off: if marks exist, unwrap them and remove injected nodes ---
var existing = document.querySelectorAll('mark.' + ID);
if (existing.length) {
existing.forEach(function (m) {
m.replaceWith(document.createTextNode(m.dataset.c)); // restore original char
});
document.body.normalize(); // merge split text nodes back together
['_' + ID + 's', '_' + ID + 'b'].forEach(function (id) {
var el = document.getElementById(id);
if (el) el.remove();
});
return;
}
// --- glyph table: char -> [name, codepoint, category, shortTag?] ---
var G = {
'\u2014': ['em dash', 'U+2014', 'dash'],
'\u2013': ['en dash', 'U+2013', 'dash'],
'\u2212': ['minus', 'U+2212', 'dash'],
'\u2010': ['hyphen', 'U+2010', 'dash'],
'\u2012': ['figure dash', 'U+2012', 'dash'],
'\u2015': ['horizontal bar', 'U+2015', 'dash'],
'\u201C': ['left double quote', 'U+201C', 'quote'],
'\u201D': ['right double quote', 'U+201D', 'quote'],
'\u2018': ['left single quote', 'U+2018', 'quote'],
'\u2019': ['apostrophe / right single', 'U+2019', 'quote'],
'\u2032': ['prime', 'U+2032', 'quote'],
'\u2033': ['double prime', 'U+2033', 'quote'],
'\u2026': ['ellipsis', 'U+2026', 'ell'],
'\u00A0': ['no-break space', 'U+00A0', 'space', 'NB'],
'\u2009': ['thin space', 'U+2009', 'space', 'TH'],
'\u202F': ['narrow no-break space', 'U+202F', 'space', 'NNB'],
'\u200C': ['zero-width non-joiner', 'U+200C', 'space', 'ZWNJ'],
'\u200D': ['zero-width joiner', 'U+200D', 'space', 'ZWJ'],
'\uFEFF': ['BOM / zero-width no-break space', 'U+FEFF', 'space', 'BOM']
};
// character class covering every key above
var cls = '[\\u2014\\u2013\\u2212\\u2010\\u2012\\u2015\\u201C\\u201D\\u2018\\u2019' +
'\\u2032\\u2033\\u2026\\u00A0\\u2009\\u202F\\u200C\\u200D\\uFEFF]';
var has = new RegExp(cls); // non-global: safe for .test()
var rx = new RegExp(cls, 'g'); // global: used to scan/split text
// --- injected stylesheet ---
var style = document.createElement('style');
style.id = '_' + ID + 's';
style.textContent =
'mark.' + ID + '{border-radius:2px;padding:0 1px;color:inherit;box-shadow:0 0 0 1px rgba(0,0,0,.2)}' +
'mark.' + ID + '.dash{background:#bcd0ff}' +
'mark.' + ID + '.quote{background:#ecc9ff}' +
'mark.' + ID + '.ell{background:#b8efe2}' +
'mark.' + ID + '.space{background:#ffd0c4;outline:1px dashed #b23b2e;display:inline-block;min-width:.5em;text-align:center}' +
'mark.' + ID + '.space::after{content:attr(data-x);font:9px/1 monospace;color:#b23b2e;vertical-align:super;margin-left:1px}';
document.head.appendChild(style);
// --- collect candidate text nodes ---
var counts = { dash: 0, quote: 0, ell: 0, space: 0 };
var nodes = [];
var walker = document.createTreeWalker(document.body, NodeFilter.SHOW_TEXT, {
acceptNode: function (n) {
if (!n.nodeValue || !has.test(n.nodeValue)) return NodeFilter.FILTER_REJECT;
var p = n.parentNode, t = p && p.nodeName;
if (t === 'SCRIPT' || t === 'STYLE' || t === 'NOSCRIPT' || t === 'TEXTAREA') return NodeFilter.FILTER_REJECT;
if (p && p.isContentEditable) return NodeFilter.FILTER_REJECT;
return NodeFilter.FILTER_ACCEPT;
}
});
while (walker.nextNode()) nodes.push(walker.currentNode);
// --- wrap each matched glyph ---
nodes.forEach(function (n) {
var frag = document.createDocumentFragment();
var v = n.nodeValue, last = 0, m;
rx.lastIndex = 0;
while ((m = rx.exec(v))) {
var ch = m[0], i = m.index, g = G[ch];
if (i > last) frag.appendChild(document.createTextNode(v.slice(last, i)));
var mk = document.createElement('mark');
mk.className = ID + ' ' + g[2];
mk.dataset.c = ch; // original char, for clean restore
mk.title = g[0] + ' ' + g[1]; // hover tooltip: name + codepoint
if (g[2] === 'space') mk.dataset.x = g[3];
mk.textContent = ch;
frag.appendChild(mk);
counts[g[2]]++;
last = i + ch.length;
}
if (last < v.length) frag.appendChild(document.createTextNode(v.slice(last)));
n.parentNode.replaceChild(frag, n);
});
// --- count badge ---
var total = counts.dash + counts.quote + counts.ell + counts.space;
var badge = document.createElement('div');
badge.id = '_' + ID + 'b';
badge.style.cssText =
'position:fixed;z-index:2147483647;right:12px;bottom:12px;background:#14161a;color:#fff;' +
'font:12px/1.5 system-ui,sans-serif;padding:8px 12px;border-radius:6px;' +
'box-shadow:0 2px 10px rgba(0,0,0,.3);max-width:240px';
badge.innerHTML =
'<b>' + total + '</b> typeset glyphs<br>' +
counts.dash + ' dash \u00B7 ' + counts.quote + ' quote \u00B7 ' +
counts.ell + ' ellipsis \u00B7 ' + counts.space + ' space/hidden<br>' +
'<span style="opacity:.7">click the bookmarklet again to clear</span>';
document.body.appendChild(badge);
})();
And here is already v2 – using a word list from a new PNAS paper by
/* ai-highlighter bookmarklet - add the following single line as a bookmark */
javascript:(function(){var ID='glyphHL',ex=document.querySelectorAll('mark.'+ID);if(ex.length){ex.forEach(function(m){m.replaceWith(document.createTextNode(m.dataset.c))});document.body.normalize();['_'+ID+'s','_'+ID+'b'].forEach(function(i){var e=document.getElementById(i);if(e)e.remove()});return}var G={'-':['em dash','U+2014','dash'],'-':['en dash','U+2013','dash'],'-':['minus','U+2212','dash'],'-':['hyphen','U+2010','dash'],'-':['figure dash','U+2012','dash'],'-':['horizontal bar','U+2015','dash'],'"':['left double quote','U+201C','quote'],'"':['right double quote','U+201D','quote'],''':['left single quote','U+2018','quote'],''':['apostrophe / right single','U+2019','quote'],''':['prime','U+2032','quote'],'"':['double prime','U+2033','quote'],'...':['ellipsis','U+2026','ell'],' ':['no-break space','U+00A0','space','NB'],' ':['thin space','U+2009','space','TH'],' ':['narrow nbsp','U+202F','space','NNB'],'':['zero-width non-joiner','U+200C','space','ZWNJ'],'':['zero-width joiner','U+200D','space','ZWJ'],'':['BOM / zwnbsp','U+FEFF','space','BOM']};var WSET=Object.create(null);('achieves achieving acknowledges adaptable addressing adept adeptly adjustments adjusts advancements advancing advocating aiding align aligning aligns alongside amidst amplifies avenues boasting boasts bolster bolstering bolsters broader capitalizes captivating captures capturing categorizes categorizing commendable complexities complicates complicating compromising consolidates contextualize contextually cornerstone crucial culminating delineates delve delved delves delving dependencies diminishes discernible downturns dynamically elucidates elucidating emphasising emphasizes emphasizing employs enabling encapsulates encompass encompassed encompasses encompassing endeavors enhance enhancements enhances enhancing ensures ensuring equipping equips escalate escalating exacerbates exacerbating exceeding excelled excelling excels exemplifies exhibits facilitating featuring formidable fortifying fostering fosters foundational frameworks garnered garnering grappling groundbreaking harnessing heighten heightened heightening heightens highlighting highlights hinges imperatives inadequately inadvertently incentivizes incentivizing incorporates incorporating inefficiencies inherently insights integrates integrating intensifies intensifying interpretability interpretable intricacies intricacy intricate intricately introduces juncture leverage leverages leveraging meticulous meticulously mitigate mitigates mitigating multifaceted navigates navigating necessitate necessitates necessitating notable notably nuanced nuances offering offers outperforming overlook overlooking overlooks overreliance overseeing oversight oversimplify paving pinpointing pivotal poised posits practicality preserving primarily prioritise prioritize prioritizes prioritizing promise prowess reaffirming realm redefines refine refines refining reflecting reinforces reliance renowned reshapes reshaping revolutionize revolutionizing rigor safeguard safeguarding safeguards seamless seamlessly serves showcases showcasing signifying situates situating sourced strategically streamline streamlined streamlining strengthens struggle stylistic surpasses surpassing symbolizing synthesizes thereby thoroughness thoughtfully thrives timelines transcends transitioning underexplored undermines underperform underperformed underpins underscore underscored underscores underscoring unlock unlocking utilizes validates warranting workflows').split(' ').forEach(function(w){WSET[w]=1});var gc='[\\u2014\\u2013\\u2212\\u2010\\u2012\\u2015\\u201C\\u201D\\u2018\\u2019\\u2032\\u2033\\u2026\\u00A0\\u2009\\u202F\\u200C\\u200D\\uFEFF]';var has=new RegExp(gc+'|[A-Za-z]{4,}'),rx=new RegExp(gc+'|[A-Za-z]{4,}','g');var s=document.createElement('style');s.id='_'+ID+'s';s.textContent='mark.'+ID+'{border-radius:2px;padding:0 1px;color:inherit;box-shadow:0 0 0 1px rgba(0,0,0,.2)}mark.'+ID+'.dash{background:#bcd0ff}mark.'+ID+'.quote{background:#ecc9ff}mark.'+ID+'.ell{background:#b8efe2}mark.'+ID+'.word{background:#ffe680}mark.'+ID+'.space{background:#ffd0c4;outline:1px dashed #b23b2e;display:inline-block;min-width:.5em;text-align:center}mark.'+ID+'.space::after{content:attr(data-x);font:9px/1 monospace;color:#b23b2e;vertical-align:super;margin-left:1px}';document.head.appendChild(s);var c={dash:0,quote:0,ell:0,space:0,word:0},nodes=[],w=document.createTreeWalker(document.body,NodeFilter.SHOW_TEXT,{acceptNode:function(n){if(!n.nodeValue||!has.test(n.nodeValue))return 3;var p=n.parentNode,t=p&&p.nodeName;if(t=='SCRIPT'||t=='STYLE'||t=='NOSCRIPT'||t=='TEXTAREA')return 3;if(p&&p.isContentEditable)return 3;return 1}});while(w.nextNode())nodes.push(w.currentNode);nodes.forEach(function(n){var f=document.createDocumentFragment(),v=n.nodeValue,last=0,m,hit=false;rx.lastIndex=0;while((m=rx.exec(v))){var tok=m[0],i=m.index,g=G[tok],cat,tag;if(g){cat=g[2];if(cat=='space')tag=g[3]}else{if(!WSET[tok.toLowerCase()])continue;cat='word'}if(i>last)f.appendChild(document.createTextNode(v.slice(last,i)));var mk=document.createElement('mark');mk.className=ID+' '+cat;mk.dataset.c=tok;mk.title=g?g[0]+' '+g[1]:'focus word (Siler PNAS 2026)';if(tag)mk.dataset.x=tag;mk.textContent=tok;f.appendChild(mk);c[cat]++;last=i+tok.length;hit=true}if(!hit)return;if(last<v.length)f.appendChild(document.createTextNode(v.slice(last)));n.parentNode.replaceChild(f,n)});var gt=c.dash+c.quote+c.ell+c.space,b=document.createElement('div');b.id='_'+ID+'b';b.style.cssText='position:fixed;z-index:2147483647;right:12px;bottom:12px;background:#14161a;color:#fff;font:12px/1.5 system-ui,sans-serif;padding:8px 12px;border-radius:6px;box-shadow:0 2px 10px rgba(0,0,0,.3);max-width:260px';b.innerHTML='<b>'+gt+'</b> typeset glyphs · <b>'+c.word+'</b> focus words<br>'+c.dash+' dash · '+c.quote+' quote · '+c.ell+' ellipsis · '+c.space+' space/hidden<br><span style="opacity:.7">click the bookmarklet again to clear</span>';document.body.appendChild(b)})();
/* glyph + focus-word highlighter bookmarklet - readable source
*
* Highlights
* typeset Unicode glyphs a plain keyboard does not produce, and
* "focus words" - lexical tells of AI-generated prose from Siler et al.,
* PNAS 2026 (doi:10.1073/pnas.2605754123).
*
* Run once to highlight; run again on the same page to remove.
*
* Categories (CSS class + colour):
* dash blue em/en/minus/hyphen/figure dash/horizontal bar
* quote purple curly quotes, curly apostrophe, prime, double prime
* ell teal ellipsis
* space red, dashed no-break/thin/narrow spaces + zero-width chars
* word yellow Siler focus words (case-insensitive, whole word)
*
* Forensic caveat: these are heuristics, not proof. Smart-punctuation and
* ordinary academic vocabulary both produce identical output from human input.
* Presence raises the prior; it does not establish AI provenance.
*/
(function () {
var ID = 'glyphHL';
// --- toggle off: if marks exist, unwrap them and remove injected nodes ---
var existing = document.querySelectorAll('mark.' + ID);
if (existing.length) {
existing.forEach(function (m) {
m.replaceWith(document.createTextNode(m.dataset.c));
});
document.body.normalize();
['_' + ID + 's', '_' + ID + 'b'].forEach(function (id) {
var el = document.getElementById(id);
if (el) el.remove();
});
return;
}
// --- glyph table: char -> [name, codepoint, category, shortTag?] ---
var G = {
'-': ['em dash', 'U+2014', 'dash'],
'-': ['en dash', 'U+2013', 'dash'],
'-': ['minus', 'U+2212', 'dash'],
'-': ['hyphen', 'U+2010', 'dash'],
'-': ['figure dash', 'U+2012', 'dash'],
'-': ['horizontal bar', 'U+2015', 'dash'],
'"': ['left double quote', 'U+201C', 'quote'],
'"': ['right double quote', 'U+201D', 'quote'],
''': ['left single quote', 'U+2018', 'quote'],
''': ['apostrophe / right single', 'U+2019', 'quote'],
''': ['prime', 'U+2032', 'quote'],
'"': ['double prime', 'U+2033', 'quote'],
'...': ['ellipsis', 'U+2026', 'ell'],
' ': ['no-break space', 'U+00A0', 'space', 'NB'],
' ': ['thin space', 'U+2009', 'space', 'TH'],
' ': ['narrow no-break space', 'U+202F', 'space', 'NNB'],
'': ['zero-width non-joiner', 'U+200C', 'space', 'ZWNJ'],
'': ['zero-width joiner', 'U+200D', 'space', 'ZWJ'],
'': ['BOM / zero-width no-break space', 'U+FEFF', 'space', 'BOM']
};
// --- Siler focus words (PNAS 2026), lowercase, stored in a Set for O(1) lookup ---
var WORDS = ('achieves achieving acknowledges adaptable addressing adept adeptly ' +
'adjustments adjusts advancements advancing advocating aiding align aligning ' +
'aligns alongside amidst amplifies avenues boasting boasts bolster bolstering ' +
'bolsters broader capitalizes captivating captures capturing categorizes ' +
'categorizing commendable complexities complicates complicating compromising ' +
'consolidates contextualize contextually cornerstone crucial culminating ' +
'delineates delve delved delves delving dependencies diminishes discernible ' +
'downturns dynamically elucidates elucidating emphasising emphasizes ' +
'emphasizing employs enabling encapsulates encompass encompassed encompasses ' +
'encompassing endeavors enhance enhancements enhances enhancing ensures ' +
'ensuring equipping equips escalate escalating exacerbates exacerbating ' +
'exceeding excelled excelling excels exemplifies exhibits facilitating ' +
'featuring formidable fortifying fostering fosters foundational frameworks ' +
'garnered garnering grappling groundbreaking harnessing heighten heightened ' +
'heightening heightens highlighting highlights hinges imperatives inadequately ' +
'inadvertently incentivizes incentivizing incorporates incorporating ' +
'inefficiencies inherently insights integrates integrating intensifies ' +
'intensifying interpretability interpretable intricacies intricacy intricate ' +
'intricately introduces juncture leverage leverages leveraging meticulous ' +
'meticulously mitigate mitigates mitigating multifaceted navigates navigating ' +
'necessitate necessitates necessitating notable notably nuanced nuances ' +
'offering offers outperforming overlook overlooking overlooks overreliance ' +
'overseeing oversight oversimplify paving pinpointing pivotal poised posits ' +
'practicality preserving primarily prioritise prioritize prioritizes ' +
'prioritizing promise prowess reaffirming realm redefines refine refines ' +
'refining reflecting reinforces reliance renowned reshapes reshaping ' +
'revolutionize revolutionizing rigor safeguard safeguarding safeguards ' +
'seamless seamlessly serves showcases showcasing signifying situates situating ' +
'sourced strategically streamline streamlined streamlining strengthens ' +
'struggle stylistic surpasses surpassing symbolizing synthesizes thereby ' +
'thoroughness thoughtfully thrives timelines transcends transitioning ' +
'underexplored undermines underperform underperformed underpins underscore ' +
'underscored underscores underscoring unlock unlocking utilizes validates ' +
'warranting workflows').split(' ');
var WSET = Object.create(null);
WORDS.forEach(function (w) { WSET[w] = 1; });
// --- combined matcher: any glyph char OR a run of ASCII letters (>=4) ---
var glyphCls = '[\\u2014\\u2013\\u2212\\u2010\\u2012\\u2015\\u201C\\u201D\\u2018\\u2019' +
'\\u2032\\u2033\\u2026\\u00A0\\u2009\\u202F\\u200C\\u200D\\uFEFF]';
var has = new RegExp(glyphCls + '|[A-Za-z]{4,}');
var rx = new RegExp(glyphCls + '|[A-Za-z]{4,}', 'g');
// --- injected stylesheet ---
var style = document.createElement('style');
style.id = '_' + ID + 's';
style.textContent =
'mark.' + ID + '{border-radius:2px;padding:0 1px;color:inherit;box-shadow:0 0 0 1px rgba(0,0,0,.2)}' +
'mark.' + ID + '.dash{background:#bcd0ff}' +
'mark.' + ID + '.quote{background:#ecc9ff}' +
'mark.' + ID + '.ell{background:#b8efe2}' +
'mark.' + ID + '.word{background:#ffe680}' +
'mark.' + ID + '.space{background:#ffd0c4;outline:1px dashed #b23b2e;display:inline-block;min-width:.5em;text-align:center}' +
'mark.' + ID + '.space::after{content:attr(data-x);font:9px/1 monospace;color:#b23b2e;vertical-align:super;margin-left:1px}';
document.head.appendChild(style);
// --- collect candidate text nodes ---
var counts = { dash: 0, quote: 0, ell: 0, space: 0, word: 0 };
var nodes = [];
var walker = document.createTreeWalker(document.body, NodeFilter.SHOW_TEXT, {
acceptNode: function (n) {
if (!n.nodeValue || !has.test(n.nodeValue)) return NodeFilter.FILTER_REJECT;
var p = n.parentNode, t = p && p.nodeName;
if (t === 'SCRIPT' || t === 'STYLE' || t === 'NOSCRIPT' || t === 'TEXTAREA') return NodeFilter.FILTER_REJECT;
if (p && p.isContentEditable) return NodeFilter.FILTER_REJECT;
return NodeFilter.FILTER_ACCEPT;
}
});
while (walker.nextNode()) nodes.push(walker.currentNode);
// --- wrap each matched glyph or focus word ---
nodes.forEach(function (n) {
var frag = document.createDocumentFragment();
var v = n.nodeValue, last = 0, m, hit = false;
rx.lastIndex = 0;
while ((m = rx.exec(v))) {
var tok = m[0], i = m.index, g = G[tok], cat, tag;
if (g) { // a typeset glyph
cat = g[2];
if (cat === 'space') tag = g[3];
} else { // a letter run - is it a focus word?
if (!WSET[tok.toLowerCase()]) continue; // not on the list: leave as plain text
cat = 'word';
}
if (i > last) frag.appendChild(document.createTextNode(v.slice(last, i)));
var mk = document.createElement('mark');
mk.className = ID + ' ' + cat;
mk.dataset.c = tok; // original text, for clean restore
mk.title = g ? g[0] + ' ' + g[1] : 'focus word (Siler PNAS 2026)';
if (tag) mk.dataset.x = tag;
mk.textContent = tok;
frag.appendChild(mk);
counts[cat]++;
last = i + tok.length;
hit = true;
}
if (!hit) return;
if (last < v.length) frag.appendChild(document.createTextNode(v.slice(last)));
n.parentNode.replaceChild(frag, n);
});
// --- count badge ---
var glyphTotal = counts.dash + counts.quote + counts.ell + counts.space;
var badge = document.createElement('div');
badge.id = '_' + ID + 'b';
badge.style.cssText =
'position:fixed;z-index:2147483647;right:12px;bottom:12px;background:#14161a;color:#fff;' +
'font:12px/1.5 system-ui,sans-serif;padding:8px 12px;border-radius:6px;' +
'box-shadow:0 2px 10px rgba(0,0,0,.3);max-width:260px';
badge.innerHTML =
'<b>' + glyphTotal + '</b> typeset glyphs · <b>' + counts.word + '</b> focus words<br>' +
counts.dash + ' dash · ' + counts.quote + ' quote · ' +
counts.ell + ' ellipsis · ' + counts.space + ' space/hidden<br>' +
'<span style="opacity:.7">click the bookmarklet again to clear</span>';
document.body.appendChild(badge);
})();
CC-BY-NC Science Surf , accessed 24.07.2026