Surveys are a crucial tool for understanding public opinion and behaviour, and their accuracy depends on maintaining statistical representativeness of their target populations by minimizing biases from all sources. Increasing data size shrinks confidence intervals but magnifies the effect of survey bias: an instance of the Big Data Paradox … We show how a survey of 250,000 respondents can produce an estimate of the population mean that is no more accurate than an estimate from a simple random sample of size 10
It basically confirms my earlier observation in asthma genetics
this result was possible with just 415 individuals instead of 500,000 individuals nowadays
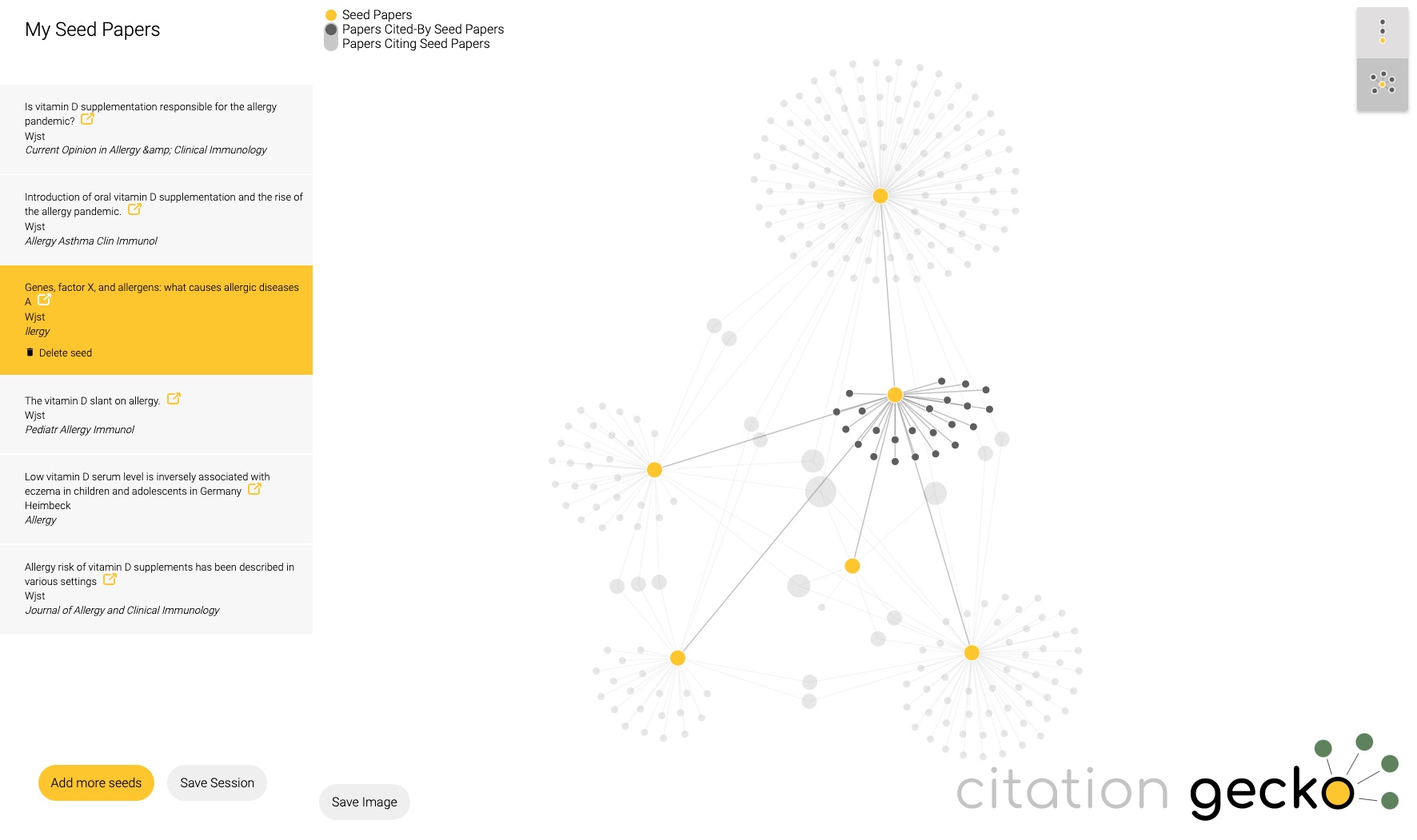
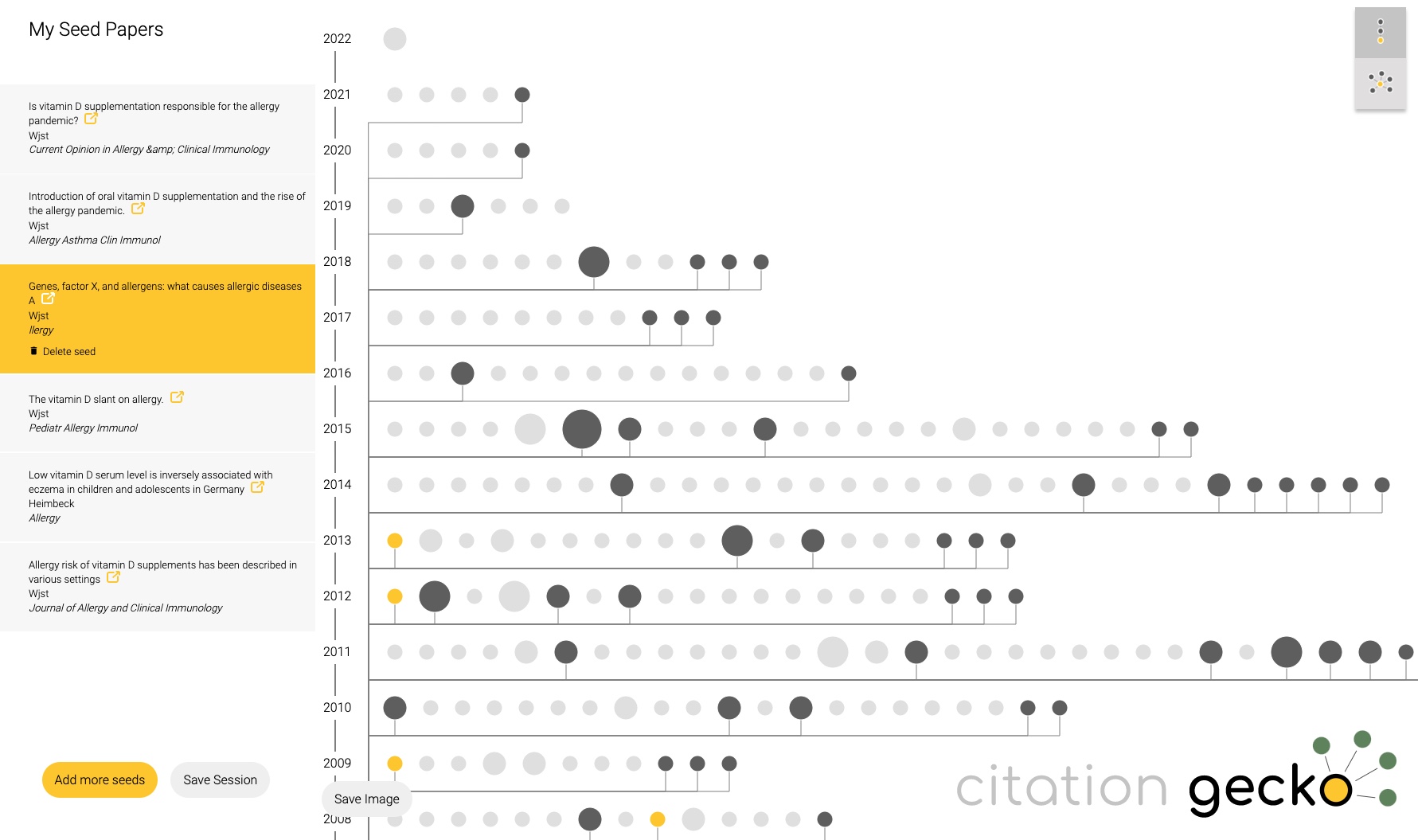
Just tried citationgecko.com on a topic that I have been working on for 2 decades. It will find rather quickly the source paper, much faster than reading through all of it. Unfortunately reviews are rated to be more influential than original data as Citation Gecko picks articles with many references.
67 authors, 83 pages, 5408 parameters in a model, the internals of which no one can say they comprehend with a straight face, 6144 TPUs in a commercial lab that no one has access to, on a rig that no one can afford, trained on a volume of data that a human couldn’t process in a lifetime, 1 page on ethics with the same ideas that have been rehashed over and over elsewhere with no attempt at a solution – bias, racism, malicious use, etc. – for purposes that who asked for?
And today? It seems that irreproducible research is set to reach a new height. Elizabeth Gibney discusses an arXiv paper by Sayash Kapoor and Arvind Narayanan basically saying that
reviewers do not have the time to scrutinize these models, so academia currently lacks mechanisms to root out irreproducible papers, he says. Kapoor and his co-author Arvind Narayanan created guidelines for scientists to avoid such pitfalls, including an explicit checklist to submit with each paper … The failures are not the fault of any individual researcher, he adds. Instead, a combination of hype around AI and inadequate checks and balances is to blame.
Algorithms being stuck on shortcuts that don’t always hold has been discussed here earlier . Also data leakage (good old confounding) due to proxy variables seems to be also a common issue.
In the deep learning community, it is common to retrospectively blame Minsky and Papert for the onset of the first ‘AI Winter,’ which made neural networks fall out of fashion for over a decade. A typical narrative mentions the ‘XOR Affair,’ a proof that perceptrons were unable to learn even very simple logical functions as evidence of their poor expressive power. Some sources even add a pinch of drama recalling that Rosenblatt and Minsky went to the same school and even alleging that Rosenblatt’s premature death in a boating accident in 1971 was a suicide in the aftermath of the criticism of his work by colleagues.
I have been using wkhtmltopdf for ages but as I am getting more and more issues with missing fonts, I was looking for an alternative in particular when going for websites that load dynamically.
Here is the macOS syntax
Data were available for 2 of 65 RCTs (3.1%) published before the ICMJE policy and for 2 of 65 RCTs (3.1%) published after the policy was issued (odds ratio, 1.00; 95% CI, 0.07-14.19; P > .99).
Among the 89 articles declaring that IPD would be stored in repositories, only 17 (19.1%) deposited data, mostly because of embargo and regulatory approval.
Of 3556 analyzed articles, 3416 contained DAS. The most frequent DAS category (42%) indicated that the datasets are available on reasonable request. Among 1792 manuscripts in which DAS indicated that authors are willing to share their data, 1670 (93%) authors either did not respond or declined to share their data with us. Among 254 (14%) of 1792 authors who responded to our query for data sharing, only 122 (6.8%) provided the requested data.
Both issues took me many years of my scientific life. It is recognized by politics in Germany but also the most recent action plan looks … ridiculous. Why not making data and software sharing mandatory at time of publication?
Doing now another image integrity study, I fear that we may already have the deep fake images in current scientific papers. Never spotted any in the wild which doesn’t mean that it does not exist…
Here are some T cells that I produced this morning.
Excellent paper at towardsdatascience.com about the responsibility for algorithms including a
broad framework for involving citizens to enable the responsible design, development, and deployment of algorithmic decision-making systems. This framework aims to challenge the current status quo where civil society is in the dark about risky ADS.
I think that the responsiblity is not primarily with the developer but with the user and the social and political framework ( SPON has a warning about the numerous crazy errors when letting AI decide about human behaviour while I can also recommend here the “Weapons of Math Destruction” ).
Being now in the 3rd wave of machine learning, the question is now already discussed (Economist & Washington Post) if AI has an own personality.
This discussion between a Google engineer and their conversational AI model helped cause the engineer to believe the AI is becoming sentient, kick up an internal shitstorm and get suspended from his job. And it is absolutely insane. https://t.co/hGdwXMzQpXpic.twitter.com/6WXo0Tpvwp
Nach Stromzähler und Gasuhr kommt hier nun mein drittes Raspberry Pi Zero Projekt: ein Abstandswarner für vorbeifahrende Fahrzeuge. Das erste Mal habe ich davon in einem wissenschaftlichen Artikel gelesen, dann gab es den Radmesser in Berlin (das Projekt war toll aber die Kiste dann doch etwas sperrig).
Auch auf Kickstarter stand mal was und dann gibt es auch noch den 200€ Varia Radar von Garmin – allerdings hatte keines der bisherigen Projekte eine Kamera eingebaut.
Laser und ToF hatte es mir immer schon angetan, dann probieren wir das auch mal hier.
Not sure if it is really the biggest but certainly one of the most pressing problems: Out-of-distribution generalization. It is explained as
Imagine, for example, an AI that’s trained to identify cows in images. Ideally, we’d want it to learn to detect cows based on their shape and colour. But what if the cow pictures we put in the training dataset always show cows standing on grass? In that case, we have a spurious correlation between grass and cows, and if we’re not careful, our AI might learn to become a grass detector rather than a cow detector.
As an epidemiologist I would have simply said, it is colliding or confounding, so every new field is rediscovering the same problems over and over again.
Not unexpected AI just running randomly over pixels is leading to spurious association. Once shape and colour of cows has been detected, surrounding environment, like grass or stable is irrelevant. That means that after getting initial results we have to step back, simulate different lighting conditions from sunlight to lightbulb and environmental conditions from grass to slatted floor (invariance principle). Also shape and size matters – cow spots will keep to some extent size and form irrespective if it is a real animal or children toy (scaling principle). I am a bit more sceptical about including also multimodal data (eg smacking sound) as the absence of these features is no proof of non-existence while this sound can also be imitated by other animals.
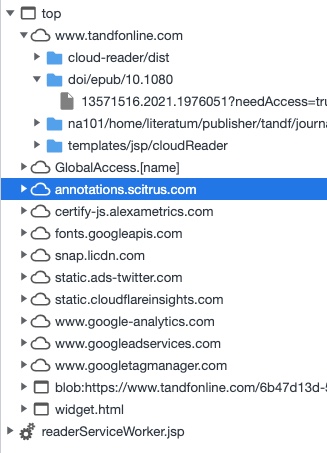
Scientific publishers are creating now more and more dynamic PDFs. Why do we know? There is an unexpected loading delay of a PDF from Routledge / Taylor & Francis group that I observed recently. First I thought about some DDos protection, but is indeed a personalized document.
These websites are all being contacted while creating this PDF:
Scitrus.com seems to be part of a larger reference organizer network and links to scienceconnect.io. Alexametric.com is the soon to be retired Alexa internet / Amazon service. Snap.lidcdn.com forwards to px.ads.linkedin.com, the business social network. Then we have Twitter ads, Cloudflare security and Google Analytics. All major players now know that my IP is interested in COVID-19 research. Did I ever agree to submit my IP and time stamp when looking up a rather crude scientific paper?
For some time now, the major academic publishers have been fundamentally changing their business model with significant implications for research: aggregation and the reuse or resale of user traces have become relevant aspects of their business. Some publishers now explicitly regard themselves as information analysis specialists. Their business model is shifting from content provision to data analytics.
Another paper describes the situation as “Forced marriages and bastards”…
My question is : Will Francis & Taylor even do more? The structure of PDFs allows including objects including Javascript. When examining “document.pdf” using pdf-parser I could not find any javascript or my current IP in clear text. I cannot exclude however that the chopped up IP is stamped somewhere in the document. So I will have try again at a later time point and redo a bitwise analysis. of the same PDF delivered on another day.
At least the DFG document says that organisations might argue that such software allows for the prosecution of users of shadow libraries. While I have doubts that this is legal, we already see targeted advertisement as I received this PDF from Wiley that included an Eppendorf ad.
Screenshot 20.1.2022
When I downloaded this document a second time using a different IP it was however identical. Blood/Elsevier only let’s you even download only after watching a small slideshow…