As I don’t like software subscription models, I never updated 1password 6 until learning yesterday about an open source alternative. And yes, KeePassXC is a perfect replacement.
CC-BY-NC Science Surf , accessed 07.04.2026
As I don’t like software subscription models, I never updated 1password 6 until learning yesterday about an open source alternative. And yes, KeePassXC is a perfect replacement.
Capitalized value? Personalized PDFs? DFG warning? User tracking? Forced marriage? It is incredible how scientific publishers are expanding their business. Here is a new paper
This essay develops the idea of surveillance publishing, with special attention to the example of Elsevier. A scholarly publisher can be defined as a surveillance publisher if it derives a substantial proportion of its revenue from prediction products, fueled by data extracted from researcher behavior. … The products’ purpose, moreover, is to streamline the top-down assessment and evaluation practices that have taken hold in recent decades. A final concern is that scholars will internalize an analytics mindset, one already encouraged by citation counts and impact factors.
Sure, this already happens as some committees look only at lists of impact factor and grant sums. In the near future, they will switch to Elsevier`s “human ressources” management system Interfolio to compare candidates.
Founded in 1999, Interfolio supports over 400 higher education institutions, research funders and academic organizations in 25 countries, and over 1.7 million academic professionals and scholars. Theo Pillay, General Manager of Research Institutional Products, Elsevier, said: “Interfolio has a proven track record in supporting the academic community, thanks to its deep understanding of faculty needs, institutional workflows, research assessment and academic careers, combined with its agile technology and experienced leadership.
Back to the original article
the publishing giants have long profited off of academics and our university employers—by packaging scholars’ unpaid writing-and-editing labor only to sell it back to us as usuriously priced subscriptions or article processing charges (APCs). That’s a lucrative business that Elsevier and the others won’t give up. But they’re layering another business on top of their legacy publishing operations, in the Clarivate mold. The data trove that publishers are sitting on is, if anything, far richer than the citation graph alone.
Data is the new oil, indeed.
Auf Science Twitter ist die Stimmung am Tiefpunkt nachdem Wissenschaftler scharenweise den Dienst verlassen.
obwohl doch klar ist, daß Continue reading Katzenjammer I
How to save hundreds of $$$ paying a predatory publisher: Use the preprint form at Github and create your own PDF that can be uploaded to OSF or any other preprint server for free.
brew install --cask vscodium brew install --cask mactex
and continue with the instructions here…
I also wrote about X without knowing why. Here is the answer.
Ein mathematischer Gottesbeweis geht zurück auf Guido Grandi und wurde vor kurzem wieder mal ausgegraben von u/Prunestand bzw Cliff Pickover.
0 = 0 + 0 + 0 + ... = (1-1) + (1-1) + (1-1) + ... = 1 - 1 + 1 - 1 + 1 - 1 + ... = 1 + (-1 + 1) + (-1 + 1) + (-1 + 1) + ... = 1 + 0 + 0 + 0 + ... = 1
was letztendlich einer Schöpfung aus dem Nichts entspricht wo doch eigentlich “nihilo ex nihilum” gilt.
Die Grandi-Reihe hat nur leider keinen Summenwert, weil sie nicht konvergent ist. Anders gesagt
0 + 0 + 0 + ... # N Elemente (1-1) + (1-1) + (1-1) + ... # 2N Elemente 1 - 1 + 1 - 1 + 1 - 1 + ... # 2N Elemente 1 + (-1 + 1) + (-1 + 1) + (-1 + 1) + ... # 2N + 1 Elemente 1 + 0 + 0 + 0 + ... # N + 1 Elemente
dh die 4. Zeile enthält eine falsche Aussage.
Frustriert oder erleichtert? Auf arXiv geht es weiter mit Gödels Gottesbeweis.
Another famous article from the past: P. W. Anderson “More is different” 50 years ago
… the next stage could be hierarchy or specialization of function, or both. At some point we have to stop talking about decreasing symmetry and start calling it increasing complication. Thus, with increasing complication at each stage, we go up on the hierarchy of the sciences. We expect to encounter fascinating and, I believe, very fundamental questions at each stage in fitting together less complicated pieces into a more complicated system and understanding the basically new types of behavior which can result.
Raspberry Pis are small single-board computers. As I have two of these devices already up and logging solar power production on my roof they could do even more: They are not only supporting a green environment but can also help people from countries with repressive governments by installation of another software package.
Snowflake is a system to defeat internet censorship. People who are censored can use Snowflake to access the internet. Their connection goes through Snowflake proxies, which are run by volunteers.
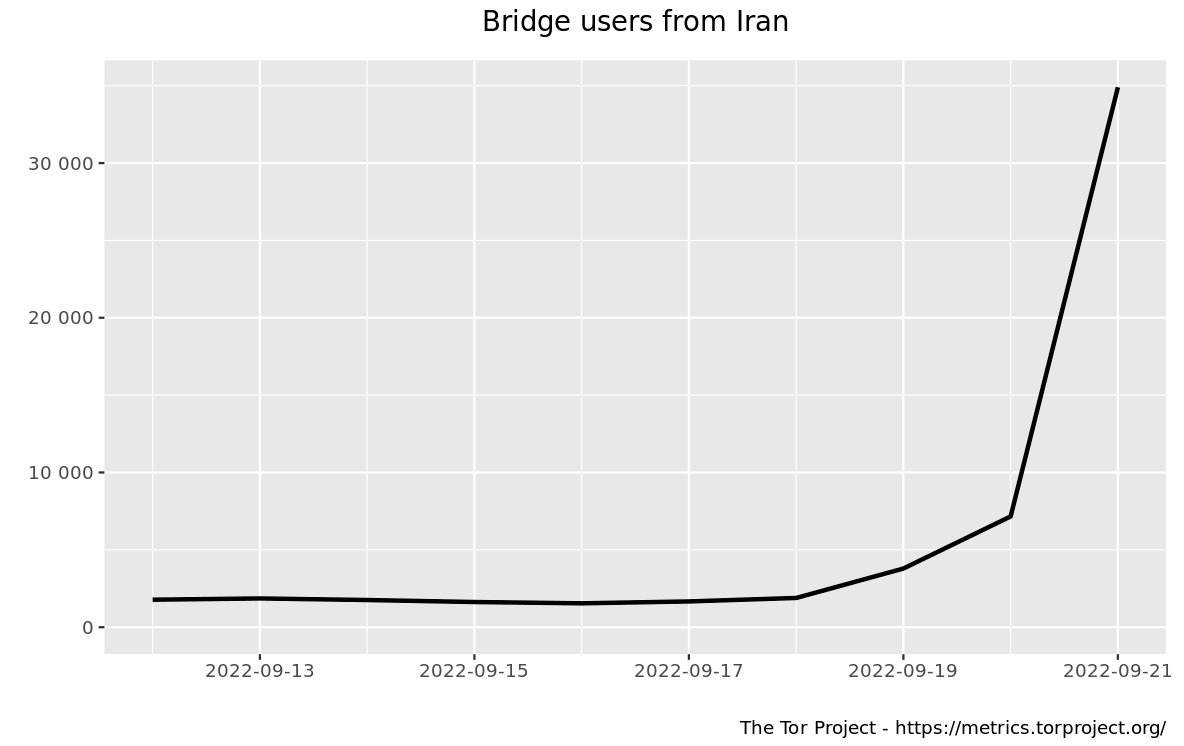
Setup takes only 2 minutes – full instructions are at kuketz-blog.de
# sudo apt-get install git # sudo apt-get install golang git clone https://git.torproject.org/pluggable-transports/snowflake.git cd snowflake/proxy go build nohup /home/pi/snowflake/proxy/proxy > /home/pi/www/snowflake.log 2>&1 &;
and this is the result
2022/09/25 17:44:19 In the last 1h0m0s, there were 16 connections. Traffic Relayed ↑ 33 MB, @ 5 MB. 2022/09/25 18:44:19 In the last 1h0m0s, there were 27 connections. Traffic Relayed ↑ 170 MB, @ 48 MB. 2022/09/25 19:44:19 In the last 1h0m0s, there were 11 connections. Traffic Relayed ↑ 61 MB, @ 28 MB. 2022/09/25 20:44:19 In the last 1h0m0s, there were 19 connections. Traffic Relayed ↑ 90 MB, @ 27 MB. 2022/09/25 21:44:19 In the last 1h0m0s, there were 10 connections. Traffic Relayed ↑ 41 MB, @ 12 MB. ...
Time to revisit the groundbreaking 1997 @mgoldh paper in Wired “Attention Shoppers! The currency of the New Economy won’t be money, but attention”
As is now obvious, the economies of the industrialized nations – and especially that of the US – have shifted dramatically. We’ve turned a corner toward an economy where an increasing number of workers are no longer involved directly in the production, transportation, and distribution of material goods, but instead earn their living managing or dealing with information in some form. Most call this an “information economy.”
I could not find any plugin but a step-by-step guide at a blog commentary
1. Download your notebook as .ipynb file
2. Upload to https://jsvine.github.io/nbpreview/
3. Open your browser dev tools and copy the element id=”notebook-holder” from the DOM
4. Paste it in your WordPress post as raw text
5. Grab CSS from https://jsvine.github.io/nbpreview/css/vendor/notebook.css
Maybe a true notebook in an iframe is a better solution?
As an avid PubPeer reader, I found a new entry by Elisabeth Bik recently about Andreas Pahl of Heidelberg Pharma who has already one retracted and several more papers under scrutiny.
Unfortunately there are now also many asthma trash papers from paper mills. Another example was identified by @gcabanac, distributed by @deevybee and published at Pubpeer.
What makes it even more complicated that there is no border anymore to predatory journals if also respected scientists drop their names at predatory journals. Only recently I received an email addressed to one of my former technical assistants as “professor” inviting her to send a paper…

Using the link https://twitter.com/search-advanced also advanced search is possible while I run a remote backup with archive page and any local copies using GoFullPage. Also Likers Blocker is recommended.

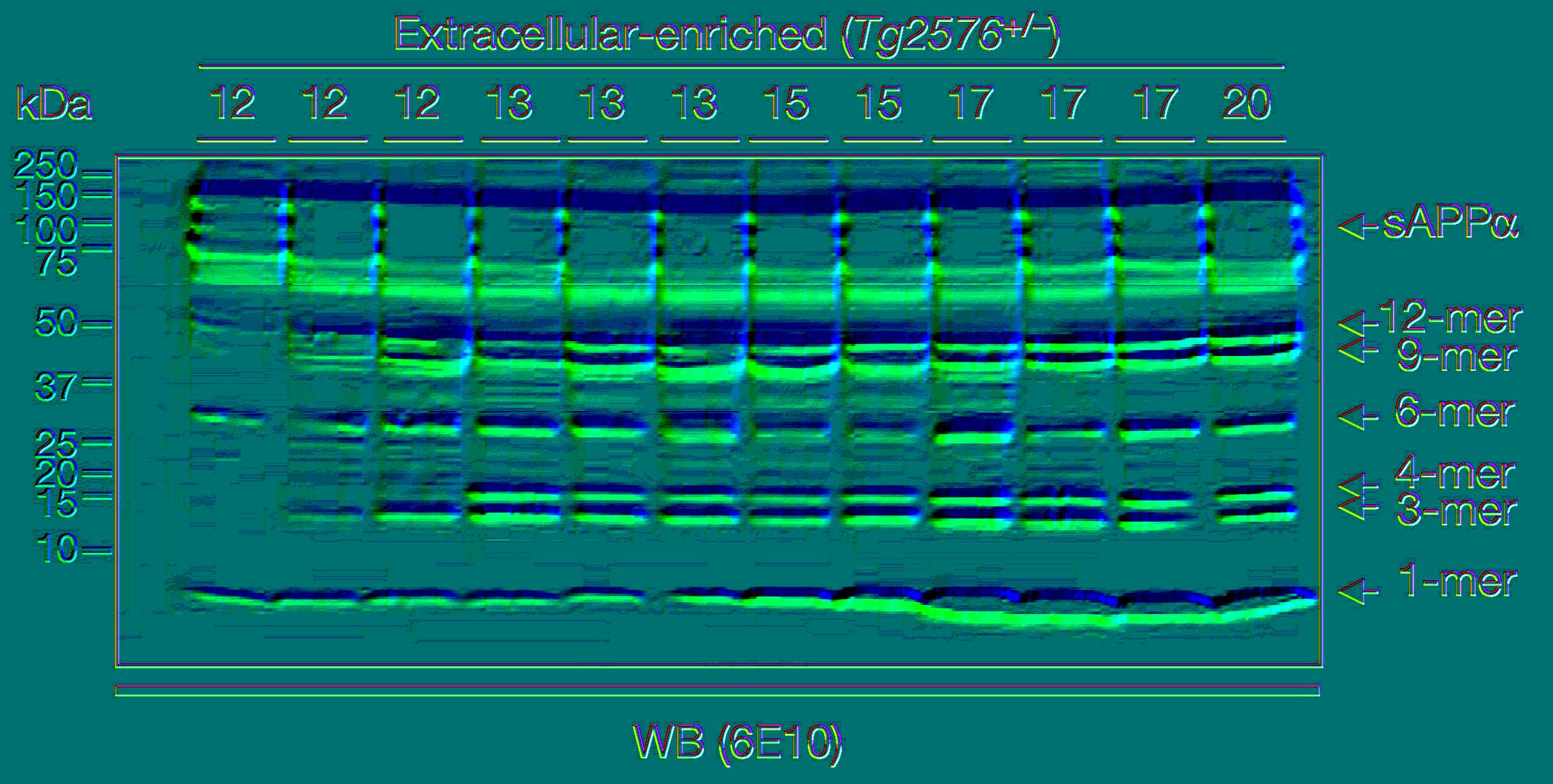
The amyloid analysis published in Nature has been commented at PubPeer and also earned a commentary of Charles Piller in Science. His “Blots on a field” news story is leading now even to an expression of concern by Nature.
The editors of Nature have been alerted to concerns regarding some of the figures in this paper. Nature is investigating these concerns, and a further editorial response will follow as soon as possible.
IMHO there are many artifacts including horizontal lines in Fig 2 when converting the image to false color display. I can not attribute the lines to any splice mark and sorry – this is a 16 year old gel image.
Basically an eternity has passed in terms of my own camera history with 5 generations from the Nikon D2x to the Z9.
So don’t expect any final conclusion here as long as we cannot get the original images.
Here is my favorite R list of packages
library(DataExplorer) plot_str(iris) plot_bar(iris) plot_density(iris) plot_correlation(iris) plot_prcomp(iris)
see also
devtools::install_github('https://github.com/paulvanderlaken/ppsr')
score(iris, x = 'Sepal.Length', y = 'Petal.Length', algorithm = 'glm')[['pps']]
while for robustness of models I use
devtools::install_github("chiragjp/quantvoe")
library(quantvoe)
Python versions come here or here.