
View detailed surf forecast for Nazare. Visit surf-forecast.com for more details, long range forecasts, surf reports, swell and weather maps.
CC-BY-NC Science Surf , accessed 22.07.2026
View detailed surf forecast for Nazare. Visit surf-forecast.com for more details, long range forecasts, surf reports, swell and weather maps.
Ich habe den Plot hier schon 2020 gebracht, wie im Osten Deutschlands die Inzidenz vor allem von Landkreisen mit primär AfD, FDP und CDU Wählern nach oben getrieben wurde.
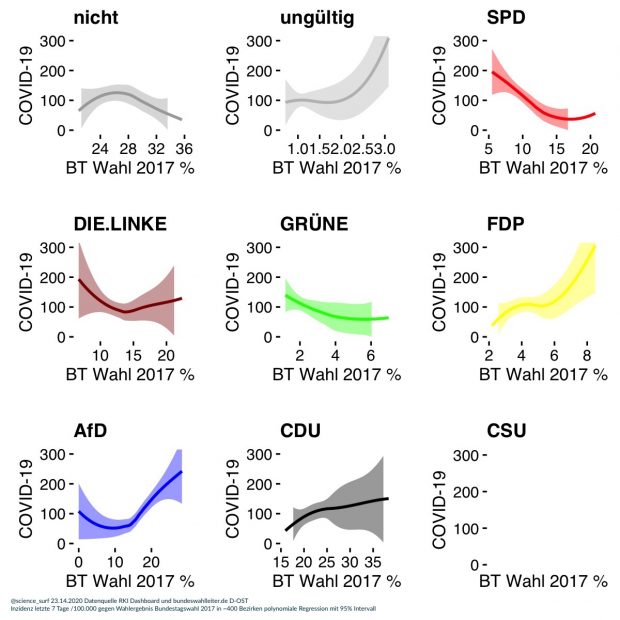
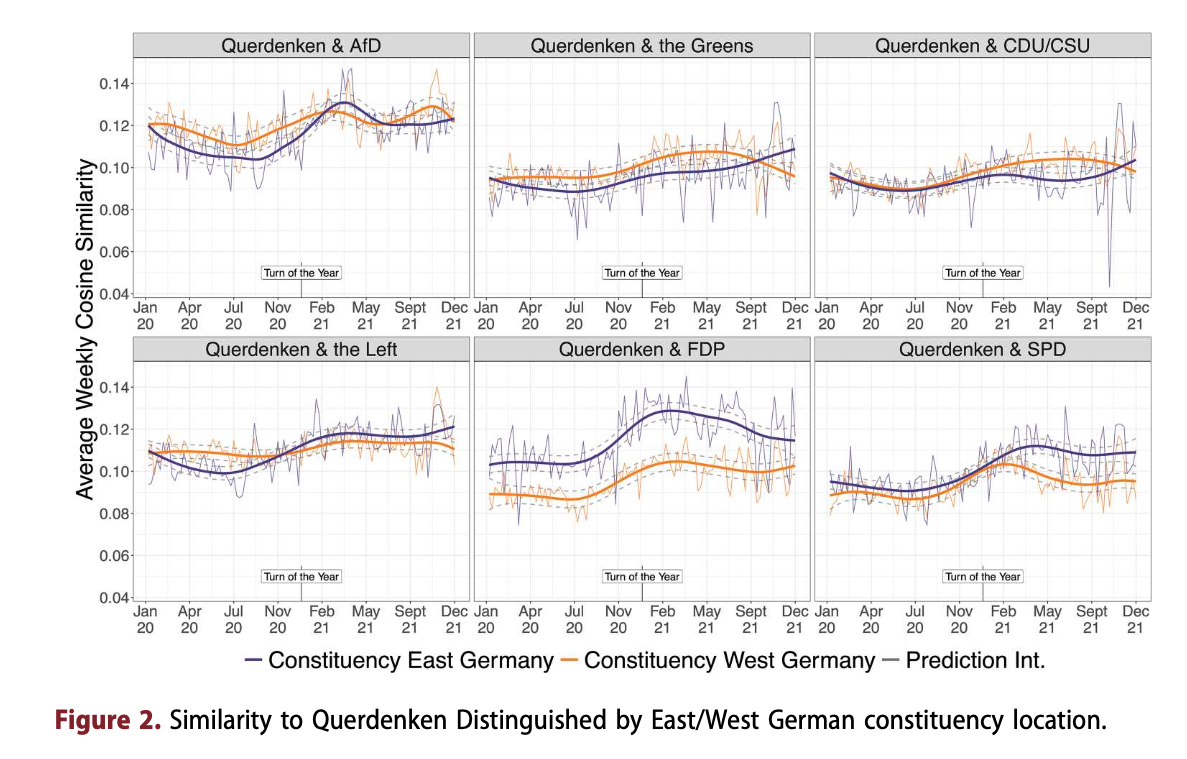
Zum Teil stand das auch in unserem Artikel von2021 wobei ich jetzt über den Citation Alert auf eine weitere interessante Arbeit von Zehring und Domahidi aufmerksam wurde “The language similarity between corona protest mobilizers on Telegram and German politicians on Twitter“. Sie zeigen
Protestbewegungen gegen Maßnahmen zur Eindämmung der COVID-19-Pandemie, wie beispielsweise die deutsche Bewegung Querdenken, verfolgen das Ziel, ihre Positionen auf die politische Agenda zu setzen. Während die rechtsgerichtete Partei Alternative für Deutschland (AfD) im Deutschen Bundestag als parlamentarischer Arm von Querdenken agierte, bleibt die Rolle anderer Parteien bislang unzureichend erforscht. … Grundlage [der Studie] bilden n = 934.432 Telegram-Nachrichten von Querdenken sowie n = 445.690 Tweets der sechs im Bundestag vertretenen Parteien in den Jahren 2020-2021. Methodisch kamen eine Kombination aus Sentence-Transformer-Modellen, Zeitreihenanalysen sowie einer ergänzenden manuellen Bewertung zum Einsatz. Die Ergebnisse zeigen, dass sich nach Herbst/Winter 2020 sämtliche untersuchten Parteien - wenn auch aus unterschiedlichen Gründen - semantisch zunehmend an die Diskurse von Querdenken angenähert haben. Während die Kommunikationsmuster der AfD die größte inhaltliche Nähe aufweisen, lassen sich auch bei Teilen der Freien Demokratischen Partei (FDP) sowie der Christlich Demokratischen Union/Christlich-Sozialen Union (CDU/CSU) Übereinstimmungen feststellen, etwa hinsichtlich der Abwertung linker und grüner Politik sowie der Ablehnung pandemiebedingter Eindämmungsmaßnahmen….
Aus Worten werden Taten, Ubi sermo, ibi actio.
Für mich ist die unverfälschte jüdische Religion wie alle anderen Religionen eine Incarnation des primitiven Aberglaubens. Und das jüdische Volk, zu dem ich gerne gehöre und mit dessen Mentalität ich tief verwachsen bin, hat für mich doch keine andersartige Dignität als alle anderen Völker. Soweit meine Erfahrung reicht ist es auch um nichts besser als andere menschliche Gruppen wenn es auch durch Mangel an Macht gegen die schlimmsten Auswüchse gesichert ist. Sonst kann ich nichts "Auserwähltes" an ihm wahrnehmen.
"Freiheit ist die Freiheit zu sagen, dass zwei plus zwei vier ist."
George Orwell, 1984.
Hier das Manifest Pro Realität
Wir verstehen uns als liberale, progressive, weltoffene, linke und feministische Stimmen, die für Pluralität und Toleranz einstehen. Alle Menschen müssen leben dürfen "nach dem Gesetz, nach dem sie angetreten". Gerade deswegen aber sehen wir mit Sorge, wie fatal die Debatte um Sex und Gender derzeit läuft. Bestürzt müssen wir zur Kenntnis nehmen, dass falsche und zum Teil regelrecht aberwitzige Verdrehungen ("weiblicher Penis", "die Biologie ist längst weiter", "es gibt mehr als zwei Geschlechter") gerade denen in die Hände spielen, die unsere demokratische Vielfalt mit dumpfen Parolen bedrohen…
Der funktionale Begriff "Geschlecht" ist in der naturwissenschaftlichen Community unstrittig: Biologisch gibt es bei allen Arten, die sich über das Verschmelzen ungleich großer Keimzellen vermehren (Anisogamie), nur zwei Arten von Keimzellen - und daraus abgeleitet zwei Geschlechter, die als männlich und weiblich bezeichnet werden…
Auf dieser biologischen Grundlage der Zweigeschlechtlichkeit gibt es kulturelle und soziale Erwartungen und Geschlechterrollen. Es ist ein Kennzeichen liberaler Gesellschaften und eine große Errungenschaft der Emanzipationsbewegung des neunzehnten und zwanzigsten Jahrhunderts, dass Geschlechterrollen keinen zwingenden Charakter mehr haben und dem Individuum alle gesellschaftlichen Rollen unabhängig vom Geschlecht offen stehen.
Coming from an official announcement
Every tax dollar the Government spends should improve American lives or advance American interests. This often does not happen. Federal grants have funded drag shows in Ecuador, trained doctoral candidates in critical race theory, and developed transgender-sexual-education programs. In 2024, one study claimed that more than one-quarter of new National Science Foundation (NSF) grants went to diversity, equity, and inclusion and other far-left initiatives. These NSF grants included those to educators that promoted Marxism, class warfare propaganda, and other anti-American ideologies in the classroom, masked as rigorous and thoughtful investigation.
While I once believed that funding should primarily support the advancement of core scientific methods and studies rather than numerous DEI initiatives, this view is a grotesque distortion of reality, especially when we consider the so-called "study" the White House is citing. Many DEI projects are, in fact, valuable educational efforts or have an environmental focus, often addressing critical research needs that receive little to no funding from other sources.
Here is a brief overview how these numbers were produced, and key problems that I have with the methods. The statement comes from the October 9, 2024 Senate Republican staff report Division. Extremism. Ideology: How the Biden-Harris NSF Politicized Science from the U.S. Senate Committee on Commerce, Science & Transportation, then led by Sen. Ted Cruz (PDF, the original is no more available on Aug 12, 2025). The underlying dataset was released on February 11, 2025 (press release and database).
Staff analyzed 32,198 NSF prime awards with start dates between January 2021 and April 4, 2024. Using a keyword-based tagging process, they identified 3,483 awards they labeled as "DEI/neo-Marxist," totaling more than $2.05 billion. The report says that for 2024 (measured only up to April 4), 27% of new grants fell into this category. Appendix A of the report explains the method. Staff pulled all NSF awards from USAspending.gov with start dates in the 2021-2024 window. They ran an n-gram/keyword search using glossaries from sources like NACo and the University of Washington, expanding the list to more than 800,000 variants. Awards with zero or only one keyword match were removed, and additional filtering plus manual checks produced the final set of 3,483. Grants were grouped into five thematic categories (Status, Social Justice, Gender, Race, Environment). The "27% in 2024" figure came from the share of awards in that subset with start dates in the first quarter of 2024.
Faults and shortcomings in the method
Restoring "gold standard" of science by non-scientists?
An US health secretary who wants to retract an Annals paper for personal opinion?
Es ist ja nicht so, daß sich die Diakonie – der soziale Dienst der Evangelischen Kirche in Deutschland EKD – umgehend nach dem Hamas Überfall im Oktober 2023 mit Spendenaufrufen gemeldet hätte (ohne aber selbst vor Ort aktiv gewesen zu sein).
Oder daß die EKD nicht zu Gebeten für den Frieden aufgerufen hätte. Aber hat sie die Bundesregierung jemals für die Waffenlieferungen in die Kriegsregion kritisiert?
Wenn auch nicht gleich in 2023, aber dann doch 2024 nach der zunehmend brutaleren Kriegsführung Israels? Continue reading Das Versagen der evangelischen Kirche Deutschlands
I have summarized the history of Post Publication Peer Review starting with Pubmed Commons to the leading website PubPeer. But most recently there are at least three new kids on the block: Peer Community In, Paperstars and alphaXiv.

What is the difference?
Peer Community In was founded in 2017 by Denis Bourguet and colleagues, targeting researchers across disciplines with a focus on peer-reviewing and recommending preprints as an alternative to traditional journals.
Paperstars, launched in 2023 by currently undisclosed founders, is aimed at both the general public and researchers, focusing on making scientific papers more accessible through AI-generated summaries and visuals.
alphaXiv was created in 2024 by the Allen Institute for AI to serve researchers and academics by enhancing preprint discoverability through AI-powered search and summarization tools.
BTW Science Guardians is a scammer website.
This is not about the extraordinary cyclist Peter Sagan but about the astronomer Carl Sagan who postulated in his 1979 book “Broca’s brain” that “extraordinary claims require extraordinary evidence”
A major part of the book is devoted to debunking “paradoxers” who either live at the edge of science or are outright charlatans.
There are only a few photographs that made headlines recently. One is Man Ray’s Le Violon d’Ingres for its price tag of $12,400,000.
Or the authorship discussion around the “Napalm Girl” Phan Thị Kim Phúc.
And there is a third photograph – a snapshot from a London townhouse two decades ago – that has a similar price tag attached like Le Violon d’Ingres.

My recent paper at https://arxiv.org/abs/2507.1223 examines this infamous photograph using the latest image analysis techniques.
This study offers a forensic assessment of a widely circulated photograph featuring Prince Andrew, Virginia Giuffre, and Ghislaine Maxwell – an image that has played a pivotal role in public discourse and legal narratives. Through analysis of multiple published versions, several inconsistencies are identified, including irregularities in lighting, posture, and physical interaction, which are more consistent with digital compositing than with an unaltered snapshot. While the absence of the original negative and a verifiable audit trail precludes definitive conclusions, the technical and contextual anomalies suggest that the image may have been deliberately constructed. Nevertheless, without additional evidence, the photograph remains an unresolved but symbolically charged fragment within a complex story of abuse, memory, and contested truth.
I provide also a 3D reconstruction of the scene in the preprint although some people may find it easier to watch a video instead.
Even after completion of the analysis there are many open questions – where is the original headshot? There are numerous similar images at various image archives while I have not found any 100% original copy so far.


Even as there are now reasonable doubts on the image, Prince Andrew could have of course met Virginia Giuffre. Maybe like an artist is painting a scene from memory, this photograph could be showing a real scene although clearly not in a physical sense.
So, to repeat my last sentence in the paper – this photograph remains an unresolved but symbolically charged fragment within a complex story of abuse, memory, and contested truth.
Note added March 2, 2026
Will add an update to the preprint in the next week as there are some interesting new results from the a comparative analysis of the above images.


"Staatsräson" nicht ausdrücklich im Grundgesetz, wenn er doch angeblich das oberste Interesse oder Prinzip beschreibt, nach dem ein Staat handelt, um sein Bestehen, seine Ordnung und seine Sicherheit zu wahren?
– Ursprünglich wurde der Begriff in der Frühneuzeit geprägt, etwa durch Niccolò Machiavelli und später Giovanni Botero oder Richelieu.
– Er diente zur Legitimation staatlicher Machtpolitik, oft losgelöst von ethischen oder rechtlichen Maßstäben.
– In der Moderne ist er normativ begrenzt - d. h. im demokratischen Rechtsstaat muss Staatsräson mit Recht, Moral und Verfassung vereinbar sein.
Also ist Staatsräson das, was ein Staat für unbedingt notwendig hält, um sich selbst zu schützen und zu erhalten. Müsste in das nicht doch in das Grundgesetz?
Das Grundgesetz ist eine rechtsstaatliche Verfassung - kein Machtinstrument. Das Grundgesetz von 1949 wurde bewusst als Gegenentwurf zur NS-Diktatur geschaffen. Es soll:
– Macht begrenzen, nicht rechtfertigen,
– die Grundrechte des Einzelnen schützen, und
– Recht und Moral über staatliche Interessen stellen.
Ein Begriff wie "Staatsräson", der traditionell die Zwecke des Staates über Recht und Moral stellt, passt nicht zu einer rechtsstaatlichen, demokratischen Verfassung wie dem Grundgesetz.
Continue reading Fragen und Antworten zur Staatsräson
Here is the link to the famous landmark paper in the recent history https://arxiv.org/abs/1706.03762
Before this paper, most sequence modeling (e.g., for language) used recurrent neural networks (RNNs) or convolutional neural networks (CNNs). These had significant limitations, such as a difficulty with long-range dependencies and slow training due to sequential processing. The Transformer replaced recurrence with self-attention, enabling parallelization and faster training, while better capturing dependencies in data. So the transformer architecture became the foundation for nearly all state-of-the-art NLP models. This enabled training models with billions of parameters, which is key to achieving high performance in AI tasks.
It’s making the rounds now – Andrew Gelman has already a long post – how authors of scientific papers are trying prompt injections for lazy reviewers that let a LLM write their review.

